2023. 7. 20. 11:37ㆍDiffusion
On Distillation of Guided Diffusion Models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, Tim Salimans
Abstract
Classifier-free guided diffusion 모델은 최근 고해상도 이미지 생성에 매우 효과적인 것으로 나타났으며 DALL·E2, Stable Diffusion 및 Imagen을 포함한 대규모 diffusion 프레임워크에서 널리 사용되고 있습니다.
그러나 classifier-free guided diffusion 모델의 단점은 클래스-조건적 모델과 무조건적 모델이라는 두 가지 diffusion 모델을 수십에서 수백 번 평가해야 하기 때문에 추론 시 계산 비용이 많이 든다는 것입니다.
이러한 한계를 해결하기 위해 classifier-free guided diffusion 모델을 샘플링 속도가 빠른 모델로 distilling하는 접근 방식을 제안합니다: 사전 학습된 classifier-free guided 모델이 주어지면, 먼저 결합된 조건적 및 무조건적 모델의 출력과 일치하는 단일 모델을 학습한 다음, 훨씬 적은 샘플링 단계를 필요로 하는 diffusion 모델로 점진적으로 해당 모델을 distill합니다.
픽셀 공간에 대해 학습된 표준 diffusion 모델의 경우, 우리의 접근 방식은 ImageNet 64x64 및 CIFAR-10에서 최소 4개의 샘플링 단계를 사용하여 원래 모델과 시각적으로 유사한 이미지를 생성할 수 있으며, 샘플링 속도가 최대 256배 더 빠르면서 원래 모델과 유사한 FID/IS 점수를 달성할 수 있습니다.
잠재 공간(예: Stable Diffusion)에 대해 학습된 diffusion 모델의 경우, 우리의 접근 방식은 1~4개의 디노이징 단계를 사용하여 높은 충실도의 이미지를 생성할 수 있으며, ImageNet 256x256 및 LAION 데이터 세트의 기존 방법에 비해 추론을 최소 10배 가속화할 수 있습니다.
우리는 또한 text-guided 이미지 편집 및 인페인팅에 대한 접근 방식의 효과를 입증합니다, 여기서 distilled 모델은 2-4개의 디노이징 단계를 사용하여 고품질 결과를 생성할 수 있습니다.

1. Introduction
Denoising diffusion probabilistic models (DDPM) [4,37,39,40]은 이미지 생성 [22,26–28,31], 오디오 합성 [11], 분자 생성 [44] 및 likelihood 추정 [10]에서 SOTA 성능을 달성했습니다.
Classifier-free guidance [6]은 diffusion 모델의 샘플 품질을 더욱 향상시키며 GLIDE [23], Stable Diffusion [28], DALL·E2 [26] 및 Imagen [31]을 포함한 대규모 diffusion 모델 프레임워크에서 널리 사용되었습니다.
그러나 classifier-free guidance의 한 가지 주요 제한 사항은 낮은 샘플링 효율성입니다—하나의 샘플을 생성하려면 두 개의 diffusion 모델을 수십 번에서 수백 번 평가해야 합니다.
이러한 제한은 실제 환경에서 classifier-free guidance 모델의 적용을 방해했습니다.
distillation 접근법이 diffusion 모델에 대해 제안되었지만 [33,38], 이러한 접근법은 classifier-free guidance diffusion 모델에 직접 적용할 수 없습니다.
이 문제를 처리하기 위해 classifier-free guidance 모델의 샘플링 효율성을 향상시키기 위한 2단계 distillation 접근법을 제안합니다.
첫 번째 단계에서, 우리는 teacher의 두 diffusion 모델의 결합된 출력과 일치하는 단일 student 모델을 소개합니다.
두 번째 단계에서, 우리는 [33]에서 소개된 접근법을 사용하여 첫 번째 단계에서 학습한 모델을 점진적으로 더 적은 단계 모델로 distill합니다.
우리의 접근 방식을 사용하여 단일 distilled 모델은 다양한 guidance 강도를 광범위하게 처리할 수 있으므로 샘플 품질과 다양성 간의 균형을 효율적으로 유지할 수 있습니다.
모델에서 샘플링하기 위해 문헌 [33, 38]에서 기존의 결정론적 샘플러를 고려하고 확률적 샘플링 프로세스를 추가로 제안합니다.

우리의 distillation 프레임워크는 픽셀 공간 [4, 36, 39]에 대해 학습된 표준 diffusion 모델뿐만 아니라 autoencoder [28,35]의 잠재 공간에 대해 학습된 diffusion 모델(예: Stable Diffusion [28])에도 적용될 수 있습니다.
픽셀 공간에서 직접 학습된 diffusion 모델의 경우, ImageNet 64x64 및 CIFAR-10에 대한 우리의 실험은 제안된 distilled 모델이 4단계만 사용하여 teacher의 것과 시각적으로 비교 가능한 샘플을 생성할 수 있으며 광범위한 guidance 강도에서 4~16단계만큼 적은 단계를 사용하여 teacher 모델과 유사한 FID/IS 점수를 얻을 수 있음을 보여줍니다(그림 2 참조).
인코더의 잠재 공간에 대해 학습된 diffusion 모델[28,35]의 경우, 우리의 접근 방식은 ImageNet 256x256 및 LAION 512x512에서 최소 1~4개의 샘플링 단계(기본 모델보다 최소 10배 적은 단계)를 사용하여 기본 모델과 유사한 시각적 품질을 달성할 수 있습니다, (FID에 의해 평가된) teacher의 성과와 2-4개의 샘플링 단계만 일치시킵니다.
우리가 아는 한, 우리의 연구는 픽셀 공간과 잠재 공간 classifier-free diffusion 모델 모두에 대한 distillation의 효과를 처음으로 입증한 것입니다.
마지막으로, 우리는 텍스트 안내 이미지 인페인팅 및 텍스트 안내 이미지 편집 작업에 우리의 방법을 적용합니다 [20], 여기서 우리는 총 샘플링 단계 수를 2-4 단계로 줄여 style-transfer 및 이미지 편집 애플리케이션에서 제안된 프레임워크의 잠재력을 보여줍니다 [20, 41].
2. Background on diffusion models
데이터 분포 p_data(x), 노이즈 스케줄링 함수 α_t 및 σ_t의 샘플 x가 주어지면 가중 평균 제곱 오차를 최소화하여 매개 변수 θ를 사용하여 diffusion 모델 ^x_θ를 학습합니다 [4, 36, 39, 40]

, 여기서 λ_t = log[α_t^2 / σ_t^2]는 신호 대 잡음비 [10], q(z_t|x) = N(z_t; α_t x, σ_t^2 I)이고 ω(λ_t)는 사전 지정된 가중치 함수 [10]입니다.
diffusion 모델 ^x_θ가 학습되면 이산 시간 DDIM 샘플러[38]를 사용하여 모델에서 샘플을 추출할 수 있습니다.
구체적으로, DDIM 샘플러는 z_1 ~ N(0, I)로 시작하여 다음과 같이

총 샘플링 단계 수 N으로 업데이트됩니다.
그런 다음 ^x_θ(z_0)를 사용하여 최종 샘플이 생성됩니다.
Classifier-free guidance
Classifier-free guidance [6]는 클래스 조건적 diffusion 모델의 샘플 품질을 크게 향상시키는 것으로 나타난 효과적인 접근 방식이며, GLIDE [23], Stable Diffusion [28], DALL·E2 [26] 및 Imagen [31]을 포함한 대규모 diffusion 모델에서 널리 사용되었습니다.
구체적으로, 그것은 샘플 품질과 다양성 사이의 균형을 위해 guidance 가중치 매개변수 w ∈ R^(≥0)을 도입합니다.
샘플을 생성하기 위해 classifier-free guidance는 식 (2)의 모델 예측으로 ^x_t^w = (1+w) ^x_(c,θ) - w ^x_θ를 사용하여 각 업데이트 단계에서 c가 조건적 컨텍스트(예: 클래스 레이블, 텍스트 프롬프트)인 조건적 diffusion 모델 ^x_θ를 모두 평가합니다.
각 샘플링 업데이트는 두 가지 diffusion 모델을 평가해야 하기 때문에 classifier-free guidance를 사용한 샘플링은 종종 비용이 많이 듭니다 [6].
Progressive distillation
우리의 접근 방식은 반복 distillation을 통해 (unguided) diffusion 모델의 샘플링 속도를 향상시키는 효과적인 방법인 progressive distillation [33]에서 영감을 받았습니다.
지금까지 이 방법은 distilling classifier-free guided 모델에 직접 적용하거나 결정론적 DDIM 샘플러 외의 샘플러에 대해 연구할 수 없었습니다 [33, 38].
이 논문에서 우리는 이러한 단점을 해결합니다.
Latent diffusion models (LDMs)
Latent diffusion models (LDM) [21,24,28,35]은 잠재 표현이 일반적으로 픽셀 공간보다 낮은 차원인 사전 학습된 정규화된 오토 인코더의 잠재 공간에서 이미지를 모델링하여 diffusion 모델(픽셀 공간에서 직접 학습)의 학습 및 추론 효율성을 높입니다.
Latent diffusion 모델은 하나 이상의 초해상도 diffusion 모델에 의존하여 저차원 이미지를 원하는 목표 해상도로 스케일업하는 cascaded diffusion 접근 방식[5]의 대안으로 고려될 수 있습니다.
이 연구에서, 우리는 픽셀 공간 [4, 36, 39]과 잠재 공간 [21, 24, 28, 35] 모두에서 학습된 classifier-free guided diffusion 모델에 distillation 프레임워크를 적용할 것입니다.
3. Distilling a guided diffusion model
다음에서, 우리는 classifier-free guided diffusion 모델[6]을 샘플링하는 데 더 적은 단계가 필요한 student 모델로 distilling하기 위한 우리의 접근 방식에 대해 논의합니다.
guidance 강도에 따라 조정된 단일 distilled 모델을 사용하여 우리 모델은 광범위한 classifier-free guided 수준을 캡처할 수 있으므로 샘플 품질과 다양성 간의 균형을 효율적으로 유지할 수 있습니다.
픽셀 공간 또는 잠재 공간에서 학습된 guided 모델 [^x_(c,t), ^x_t](teacher)이 주어지면 우리의 접근 방식은 두 단계로 분해될 수 있습니다.
3.1. Stage-one distillation
첫 번째 단계에서, 우리는 학습 가능한 매개 변수 η_1을 가진 student 모델 ^x_η_1(z_t, w)을 도입하여 모든 시간 단계 t ∈ [0, 1]에서 teacher의 출력과 일치시킵니다.
student 모델은 teacher 모델이 이산인지 연속인지에 따라 연속 시간 모델[40] 또는 이산 시간 모델[4, 38]이 될 수 있습니다.
단순성을 위해, 다음 토론에서는 이산 모델에 대한 알고리즘이 거의 동일하기 때문에 student 모델과 teacher 모델이 모두 연속적이라고 가정합니다.
classifier-free guidance [6]의 핵심 기능은 "guidance strength" 매개변수에 의해 제어되는 샘플 품질과 다양성 사이에서 쉽게 절충할 수 있는 능력입니다.
이 속성은 최적의 "guidance strength"가 종종 사용자 선호도인 실제 애플리케이션[6,23,26,28,31]에서 유용성을 입증했습니다.
따라서 우리는 distilled 모델이 이 특성을 유지하기를 원합니다.
우리가 관심 있는 다양한 guidance 강도 [w_min, w_max]를 고려하여, 우리는 다음 objective

을 사용하여 student 모델을 최적화합니다, 여기서 ^x_θ^w (z_t) = (1+w) ^x_(c,θ) (z_t) - w^x_θ (z_t), z_t ~ q(z_t|x) 및 p_w (w) = U[w_min, w_max].
여기서 distilled 모델 ^x_η_1(z_t, w)도 컨텍스트 c(예: 텍스트 프롬프트)에 따라 조건화되지만, 단순성을 위해 논문에서 표기 c를 삭제합니다.
우리는 부록에서 알고리즘 1의 자세한 학습 알고리즘을 제공합니다.
guided 가중치 w를 통합하기 위해 w가 student 모델의 입력으로 공급되는 w-조건적 모델을 도입합니다.
피쳐를 더 잘 캡처하기 위해, 우리는 푸리에 임베딩을 w에 적용하고, 이는 [10, 33]에서 시간 단계가 통합된 방식과 유사한 방식으로 diffusion 모델 백본에 통합됩니다.
초기화는 성능[33]에서 핵심적인 역할을 하기 때문에, 우리는 w-conditioning과 관련하여 새로 도입된 매개 변수를 제외하고 teacher의 조건적 모델과 동일한 매개 변수로 student 모델을 초기화합니다.
우리가 사용하는 모델 아키텍처는 픽셀 공간 diffusion 모델에 [6], 잠재 공간 diffusion 모델에 [1, 28]에 사용된 것과 유사한 U-Net 모델입니다.
[6] 및 오픈 소스 Stable Diffusion 저장소에서 사용된 것과 동일한 수의 채널과 어텐션을 실험에 사용합니다.
우리는 부록에 더 자세한 내용을 제공합니다.
3.2. Stage-two distillation
두 번째 단계에서는 이산 시간 단계 시나리오를 고려하고 매번 샘플링 단계의 수를 절반으로 줄임으로써 첫 번째 단계 ^x_η_1(z_t, w)에서 학습 가능한 매개 변수 η_2를 가진 더 적은 단계의 student 모델 ^x_η_2(z_t, w)로 점진적으로 distill합니다.
N이 w ~ U[w_min, w_max] 및 t ∈ {1, ..., N}이 주어지면 [33]의 접근 방식에 따라 한 단계에서 student 모델이 teacher의 2단계 DDIM 샘플링 출력(즉, t/N에서 t - 0.5/N 및 t - 0.5/N에서 t - 1/N)과 일치하도록 학습합니다.
teacher 모델의 2N단계를 student 모델의 N단계로 distilling한 후, 우리는 N단계 student 모델을 새로운 teacher 모델로 사용하고 동일한 절차를 반복하여 teacher 모델을 N/2단계 student 모델로 distill할 수 있습니다.
각 단계에서 teacher의 매개 변수로 student 모델을 초기화합니다.
우리는 학습 알고리즘과 추가 세부 사항을 보충 자료에 제공합니다.
3.3. N-step deterministic and stochastic sampling
모델 ^x_η_2가 학습되면, 지정된 guidance 강도 w ∈ [w_min, w_max]가 주어지면, 우리는 식 (2)의 DDIM 업데이트 규칙을 통해 샘플링을 수행할 수 있습니다.
우리는 distilled 모델 ^x_η_2를 고려할 때, 초기화 z_1^w를 고려할 때 이 샘플링 절차가 결정론적이라는 것에 주목합니다.
실제로 N단계 확률적 샘플링도 수행할 수 있습니다: 우리는 원래 스텝 길이의 두 배(즉, N/2 스텝 결정론적 샘플러와 동일)로 하나의 결정론적 샘플링 단계를 적용한 다음 [9]에서 영감을 받은 프로세스인 원래 스텝 길이를 사용하여 하나의 확률적 스텝 역방향(즉, 노이즈가 있는 섭동)을 수행합니다.
z_1^w ~ N(0, I)을 사용하면 t > 1/N일 때 다음 업데이트 규칙을 사용합니다

위 방정식에서, h = t - 3/N, k = t - 2/N, s = t - 1/N 및 σ_(a|b)^2 = (1 - e^(λ_a - λ_b))σ_a^2.
t = 1/N일 때, 우리는 결정론적 업데이트 식 (2)를 사용하여 z_(1/N)^w에서 z_0^w를 얻습니다.
우리는 디노이징 단계 수가 4인 그림 5의 프로세스에 대한 예시를 제공합니다.
우리는 결정론적 샘플러와 비교하여 확률적 샘플링을 수행하려면 약간 다른 시간 단계에서 모델을 평가해야 하며 에지 사례에 대한 학습 알고리즘을 약간 수정해야 한다는 점에 주목합니다.
우리는 알고리즘과 더 자세한 내용을 보충 자료에 제공합니다.

4. Experiments
이 섹션에서는 픽셀 공간 diffusion 모델(예: DDPM [4])과 잠재 공간 diffusion 모델(예: Stable Diffusion [28])에 대한 distillation 접근 방식의 성능을 평가합니다.
우리는 텍스트 안내 이미지 편집 및 인페인팅 작업에 우리의 접근 방식을 추가로 적용합니다.
실험에 따르면 우리의 접근 방식은 모든 작업에서 2-4단계 정도만 사용하면서도 경쟁력 있는 성능을 달성할 수 있습니다.
4.1. Distillation for pixel-space guided models
이 실험에서, 우리는 픽셀 공간[4, 6, 33]에 대해 직접 학습된 클래스 조건적 diffusion 모델을 고려합니다.
Settings
이 시나리오에서 고해상도 이미지 생성은 종종 다른 초해상도 기술 [5, 31]과 결합에 의존하기 때문에 우리는 ImageNet 64x64 [30]과 CIFAR-10 [12]에 중점을 둡니다.
우리는 guidance 가중치에 대한 다양한 범위를 탐색하고 모든 범위가 유사하게 작동함을 관찰하여 실험에 [w_min, w_max] = [0, 4]를 사용합니다.
우리가 고려하는 기준은 DDPM 조상 샘플링[4]과 DDIM[38]을 포함합니다.
우리가 사용하는 teacher 모델은 1024x2단계 DDIM 모델로, 조건적과 무조건적 구성 요소 모두 1024 DDIM 디노이징 단계를 사용합니다.
guidance 가중치 w가 어떻게 통합되어야 하는지 더 잘 이해하기 위해, 우리는 또한 단일 고정 w를 기준으로 사용하여 학습된 모델을 포함합니다.
공정한 비교를 위해 모든 방법에 대해 동일한 사전 학습된 teacher 모델을 사용합니다.
[4, 6, 39]에 이어 베이스라인에 U-Net [29, 39] 아키텍처를 사용하고 2단계 student 모델에 도입된 w-embedding과 동일한 U-Net 백본을 사용합니다(섹션 3 참조).
[33]에서는 두 데이터 세트 모두에 대해 v-예측 모델을 사용합니다.

Results
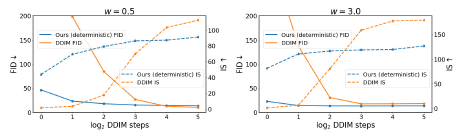
우리는 그림 6과 표 1의 ImageNet 64x64에 대한 모든 접근 방식에 대해 FID [3] 및 Inception Score(IS) [32]에서 평가된 성능을 보고하고 확장된 ImageNet 64x64 및 CIFAR-10 결과를 보완에서 제공합니다.
우리는 distilled 모델이 4-16단계만 사용하여 1024x2 샘플링 단계와 teacher guided DDIM 모델을 일치시켜 최대 256배의 속도를 달성할 수 있음을 관찰했습니다.
우리는 우리의 접근 방식을 사용하여 단일 distilled 모델이 광범위한 guidance 강도에서 teacher의 성과와 일치할 수 있음을 강조합니다.
이것은 이전의 어떤 방법으로도 달성되지 않았습니다.
4.2. Distillation for latent-space guided models
섹션 4.1에서 픽셀 공간 class-guided diffusion 모델에 대한 방법의 효과를 입증한 후, 이제 잠재 공간 diffusion 모델로 범위를 확장합니다.
다음 섹션에서는 클래스 조건적 생성, text-to-image 생성, 이미지 인페인팅 및 text-guided style-transfer [28]을 포함한 다양한 작업에 대한 잠재 diffusion에 대한 접근 방식의 효과를 보여줍니다.
다음 실험에서, 우리는 오픈 소스 잠재 공간 diffusion 모델[28]을 teacher 모델로 사용합니다.
v-예측 teacher 모델이 ε-예측 모델보다 성능이 우수한 경향이 있기 때문에 오픈 소스 ε-예측 모델을 v-예측 teacher 모델로 미세 조정합니다.
우리는 보충 자료에 더 자세한 내용을 제공합니다.
4.2.1 Class-conditional generation
이 섹션에서는 ImageNet 256x256에서 사전 학습된 클래스 조건적 잠재 diffusion 모델에 우리의 방법을 적용합니다.
우리는 512개의 샘플링 단계로 DDIM teacher 모델에서 시작하여 출력을 타겟으로 distilled 모델을 학습합니다.
우리는 512의 배치 크기를 사용하고 학습 중에 guidance 강도 w ∈ [w_min = 0, w_max = 14]를 균일하게 샘플링합니다.
Results
경험적으로, 우리는 distilled 모델이 2~4개의 샘플링 단계만 사용하면서 FID 점수 측면에서 teacher 모델의 성능(원래 1000단계에서 학습됨)과 일치할 수 있다는 것을 발견했습니다.
또한 1-4개의 샘플링 단계를 사용할 때 DDIM보다 훨씬 우수한 성능을 달성했습니다(그림 11 참조).
질적으로, 우리는 단일 디노이징 단계를 사용하여 합성된 샘플이 여전히 만족스러운 결과를 산출하는 반면 베이스라인은 의미 있는 내용을 가진 이미지를 생성하지 못한다는 것을 발견했습니다.
우리는 추가 샘플을 보충 자료로 제공합니다.
그림 6의 픽셀 기반 결과와 유사하게, 우리는 distilled 잠재 diffusion 모델에 대한 FID 및 Inception Score에 의해 측정된 샘플링 품질과 다양성 사이의 균형을 관찰합니다.
Kynkaanniemi et al [13]에 이어 부록에서 이 실험에 대한 개선된 precision와 recall 메트릭을 추가로 계산합니다.
4.2.2 Text-guided image generation
이 섹션에서는 해상도 512x512에서 LAION-5B [34]의 하위 집합에 대해 사전 학습된 텍스트 유도 Stable Diffusion 모델에 초점을 맞춥니다.
그런 다음 섹션 3에서 소개한 2단계 접근 방식을 따르고 3000 그레디언트 업데이트에서 안내된 모델을 w ∈ [w_min = 2, w_max = 14]와 512의 배치 크기를 사용하는 w-조건 모델로 distill합니다.
distilled (student) 모델에 대해 더 넓은 범위의 w를 조건화할 수 있지만, teacher 모델로 샘플링할 때 일반적으로 일반적인 guidance 범위를 초과하지 않기 때문에 유틸리티는 여전히 불분명합니다.
최종 모델은 20000 그레디언트 업데이트를 위해 학습하는 1, 2, 4단계의 낮은 단계 체제를 제외하고 단계당 2000개의 학습 단계에 대해 점진적 distillation을 적용하여 얻습니다.
부록에서 이 모델의 수렴 특성에 대한 자세한 분석.


Results
우리는 그림 4에 샘플을 제시합니다.
우리는 결과 모델을 질적, 양적으로 평가합니다.
후자의 분석을 위해, 우리는 [31]을 따르고 CLIP [25]과 FID 점수를 평가하여 각각 텍스트 이미지 정렬과 품질을 평가합니다.
우리는 평가를 위해 오픈 소스 ViT-g/14 [7] CLIP 모델을 사용합니다.
그림 10의 정량적 결과는 우리의 방법이 2단계 및 4단계 샘플링에 대한 기본 모델의 DDIM 샘플링에 비해 두 메트릭 모두에서 성능을 크게 향상시킬 수 있음을 보여줍니다.
8단계의 경우 이러한 메트릭은 큰 차이를 보이지 않습니다.
그러나 그림 7의 해당 샘플을 고려할 때 시각적 이미지 품질 측면에서 극명한 차이를 볼 수 있습니다.
원래 모델의 8단계 DDIM 샘플과 달리 증류된 샘플은 더 날카롭고 일관성이 있습니다.
우리는 FID와 CLIP가 COCO2017[14]의 평가 설정에서 이러한 차이를 완전히 포착하지 못한다는 가설을 세웁니다, 여기서 검증 세트에서 5000개의 랜덤 캡션을 사용했습니다.
또한 distilled LAION 512x512 모델에 대한 FID 및 CLIP 점수를 계산하여 표 2의 DPM [16] 및 DPM++ [18] 솔버와 비교합니다.
우리는 디노이징 단계가 2 또는 4일 때 우리의 방법이 훨씬 더 나은 성능을 달성할 수 있다는 것을 관찰합니다.
또한, 우리는 classifier-free guidance 단계를 단일 모델로 distill하기 때문에 우리의 방법의 1단계는 이미 함수 평가의 수를 2배로 감소시킨다는 것을 강조합니다.
정확한 구현(배치 vs 순차적 네트워크 평가)에 따라 기존 솔버에 비해 피크 메모리 또는 샘플링 시간이 감소합니다 [16, 18, 38].

4.2.3 Text-guided image-to-image translation
이 섹션에서는 섹션 4.2.2의 distilled 모델을 사용하여 SDEdit [20]을 사용한 text-guided image-to-image 변환에 대한 실험을 수행합니다.
SDEdit [20]에 따라 잠재 공간에서 확률적 인코딩을 수행하지만, 대신 distilled 모델의 결정론적 샘플러를 사용하여 결정론적 디코딩을 수행합니다.
우리는 다양한 종류의 입력 이미지와 텍스트를 고려하고 그림 8에서 질적인 결과를 제공합니다.
우리는 distilled 모델이 3개의 디노이징 단계를 사용하여 고품질 스타일 전송 결과를 생성한다는 것을 관찰했습니다.
우리는 보충 자료에서 샘플 품질, 제어 가능성 및 효율성 간의 균형에 대한 추가 분석을 제공합니다.

4.2.4 Image inpainting
이 섹션에서는 사전 학습된 이미지 인페인팅 잠재 diffusion 모델에 접근 방식을 적용합니다.
우리는 오픈 소스 Stable Diffusion 인페인팅 이미지 인페인팅 모델을 사용합니다.
이 모델은 위의 순수 text-to-image Stable Diffusion 모델의 미세 조정 버전으로, 마스크 및 마스크된 이미지를 처리하기 위해 추가 입력 채널이 추가되었습니다.
이전 섹션에서 사용한 것과 동일한 distillation 알고리즘을 사용합니다.
학습을 위해 512개의 DDIM 단계로 샘플링된 v-prediction teacher 모델에서 시작하여 출력을 타겟으로 사용하여 student 모델을 최적화합니다.
우리는 그림 9에 질적 결과를 제시하여 빠른 실제 이미지 편집 애플리케이션에 대한 우리 방법의 잠재력을 보여줍니다.
추가 학습 세부 사항 및 정량적 평가는 보충 자료를 참조하십시오.

4.3. Progressive distillation for encoding
이 실험에서, 우리는 teacher 모델에 대한 인코딩 프로세스를 distilling하고 [41]과 유사한 설정에서 style-transfer에 대한 실험을 수행합니다.
우리는 ImageNet 64x64에서 사전 학습된 픽셀 공간 diffusion 모델에 중점을 둡니다.
특히, 두 도메인 A와 B 사이에서 style-transfer를 수행하기 위해 도메인 A에서 학습된 diffusion 모델을 사용하여 도메인 A에서 이미지를 인코딩한 다음 도메인 B에서 학습된 diffusion 모델로 디코딩합니다.
인코딩 프로세스는 DDIM 샘플링 프로세스를 반대로 하는 것으로 이해될 수 있으므로 classifier-free guidance로 인코더와 디코더 모두에 대해 distillation을 수행하고 그림 12의 DDIM 인코더와 디코더와 비교합니다.
우리는 또한 guidance 강도를 수정하는 것이 성능에 어떻게 영향을 미칠 수 있는지 살펴보고 보충 자료에 더 자세한 정보를 제공합니다.

5. Related Work
우리의 접근 방식은 diffusion 모델의 샘플링 속도를 개선하는 기존 작업과 관련이 있습니다 [4, 37, 40].
예를 들어, denoising diffusion implicit models (DDIM [38]), probability flow sampler [40], fast SDE integrators [8]는 diffusion 모델의 샘플링 속도를 향상시키기 위해 제안되었습니다.
다른 연구에서는 higher-order solvers [17], exponential integrators [15], 샘플링 속도를 가속화하기 위한 dynamic programming based approach [43]을 개발합니다.
그러나 이러한 접근 방식 중 어떤 것도 classifier-free guided diffusion 모델을 distilling하는 방법과 비슷한 성능을 달성하지 못했습니다.
diffusion 모델을 위한 기존 distillation 기반 방법은 주로 non-classifier-free guided diffusion 모델을 위해 설계되었습니다.
예를 들어, [19]는 DDIM의 결정론적 인코딩을 반전하여 단일 단계에서 노이즈로부터 데이터를 예측할 것을 제안하고, [2]는 신경망 백본의 추가 예측 헤드에 고차 솔버를 distilling하여 더 빠른 샘플링 속도를 달성할 것을 제안합니다 [2].
점진적 distillation [33]이 아마도 가장 관련성이 높은 작업일 것입니다.
특히, 사전 학습된 diffusion 모델을 동일한 모델 아키텍처를 가진 더 적은 단계의 studnet 모델로 점진적으로 distill할 것을 제안합니다.
그러나 이러한 접근 방식 중 어떤 것도 직접 적용할 수 없거나 classifier-free guided diffusion 모델에 적용되지 않았습니다.
또한 단일 distilled 모델을 사용하여 다양한 guidance 강도를 포착할 수 없습니다.
반대로, 모델 아키텍처에 guidance 강도를 통합하고 2단계 절차를 사용하여 모델을 학습함으로써, 우리의 접근 방식은 단일 모델을 사용하여 광범위한 guidance 강도에 대한 teacher 모델의 성능을 일치시킬 수 있습니다.
우리의 방법을 사용하면 하나의 단일 모델이 샘플 품질과 다양성 사이의 균형을 포착하여 사용자가 종종 guidance 강도를 지정하는 classifier-free guided diffusion 모델의 실제 적용을 가능하게 합니다.
게다가, 위의 distillation 접근법은 잠재 공간 text-to-image 모델에 적용되거나 효과를 보여주지 않았습니다.
마지막으로, 대부분의 빠른 샘플링 접근법 [33, 38, 40]은 샘플링 속도를 향상시키기 위해 결정론적 샘플링 체계를 사용하는 것만 고려합니다.
이 연구에서, 우리는 distilled 모델에서 샘플을 추출하기 위한 효과적인 확률적 샘플링 접근법을 추가로 개발합니다.
6. Conclusion
본 논문에서, 우리는 guided diffusion 모델에 대한 distillation 접근법을 제안합니다 [6].
우리의 2단계 접근 방식을 통해 대중적이지만 상대적으로 비효율적인 guided diffusion 모델의 속도를 크게 높일 수 있습니다.
우리는 우리의 접근 방식이 classifier-free guided 픽셀 공간 및 잠재 공간 diffusion 모델의 추론 비용을 최소 크기의 순서로 줄일 수 있음을 보여줍니다.
경험적으로, 우리는 우리의 접근 방식이 2단계만으로 시각적으로 매력적인 결과를 생성할 수 있으며, 최소 4~8단계로 teacher와 비슷한 FID 점수를 달성할 수 있음을 보여줍니다.
또한 text-guided image-to-image 변환 및 인페인팅 작업에 대한 distillation 접근 방식의 실용적인 적용을 보여줍니다.
classifier-free guided diffusion 모델의 추론 비용을 크게 줄임으로써 우리의 방법이 창의적인 응용 프로그램뿐만 아니라 이미지 생성 시스템의 더 광범위한 채택을 촉진하기를 바랍니다.
향후 연구에서, 우리는 2단계 및 1단계 샘플링 체제에서 성능을 더욱 향상시키는 것을 목표로 합니다.
A. Results overview
이 섹션에서는 픽셀 공간 및 잠재 공간 diffusion 모델에 대해 달성한 속도 향상에 대한 개요 표를 제공합니다(표 3 참조).
또한 텍스트 유도 이미지 생성 모델의 추가 샘플과 그림 13 및 그림 14의 DDM [38], DPM [17] 및 DPM++ [18] 솔버와의 비교를 제공합니다.
부록 B의 픽셀 공간 distillation과 부록 C의 잠재 공간 distillation에 대한 더 많은 실험 세부 정보를 제공합니다.
B. Pixel-space distillation
B.1. Teacher model
우리가 사용하는 모델 아키텍처는 [6]에서 사용된 것과 유사한 U-Net 모델입니다.
모델은 [33]에서 논의된 대로 v를 예측하도록 매개 변수화되었습니다.
우리는 [6]과 동일한 학습 설정을 사용합니다.

B.2. Stage-one distillation
우리가 사용하는 모델 아키텍처는 [6]에서 사용된 것과 유사한 U-Net 모델입니다.
우리는 ImageNet 64x64 및 CIFAR-10 모두에 대해 [6]에서 사용된 것과 동일한 수의 채널과 어텐션을 사용합니다.
섹션 3에서 언급한 바와 같이, 우리는 또한 모델이 입력되도록 합니다.
특히, 우리는 모델 백본과 결합하기 전에 w에 푸리에 임베딩을 적용합니다.
우리가 w를 통합하는 방식은 [10, 33]에서 사용된 것과 같이 시간 단계가 모델에 통합되는 방식과 동일합니다.
우리는 [33]에서 논의된 것처럼 v를 예측하도록 모델을 매개변수화합니다.
우리는 알고리즘 1을 사용하여 distilled 모델을 학습합니다.
우리는 SNR loss [10, 33]를 사용하여 모델을 학습합니다.
ImageNet 64x64의 경우, 우리는 EMA 감소가 0.99999인 학습률 3e-4를 사용합니다.
CIFAR-10의 경우, 우리는 EMA 감소가 0.99999인 학습률 1e - 3을 사용합니다.
우리는 w-임베딩과 관련된 매개변수를 제외하고 teacher 모델의 매개변수로 student 모델을 초기화합니다.

B.3. Stage-two distillation for deterministic sampler
우리는 Stage 1에서 사용된 것과 동일한 모델 아키텍처를 사용합니다(부록 B.2 참조).
우리는 알고리즘 2를 사용하여 distilled 모델을 학습합니다.
우리는 먼저 Stage-1의 student 모델을 teacher 모델로 사용합니다.
우리는 1024개의 DDIM 샘플링 단계에서 시작하여 Stage-1의 student 모델을 점진적으로 하나의 스텝 모델로 distill합니다.
우리는 샘플링 단계의 수가 절반으로 줄어들고 student 모델이 새로운 teacher 모델이 되기 전에 100,000개의 파라미터 업데이트를 위해 모델을 학습하는 1~2스텝과 동일한 샘플링 단계를 제외하고 50,000개의 파라미터 업데이트를 위해 student 모델을 학습합니다.
각 샘플링 스텝에서 우리는 teacher 모델의 파라미터로 student 모델을 초기화합니다.
우리는 SNR truncation loss [10, 33]를 사용하여 모델을 학습합니다.
각 스텝에 대해 우리는 각 파라미터 업데이트 동안 학습률을 1e - 4에서 0으로 선형적으로 제거합니다.
우리는 학습을 위해 EMA 붕괴를 사용하지 않습니다.
우리의 학습 설정은 [33]의 설정을 밀접하게 따릅니다.

B.4. Stage-two distillation for stochastic sampling
알고리즘 3을 사용하여 distilled 모델을 학습합니다.
우리는 ImageNet 64x64 및 CIFAR-10 모두에 대해 부록 B.3에 설명된 Stage-2 distillation과 동일한 모델 아키텍처 및 학습 설정을 사용합니다: 여기서 주요한 차이점은 우리의 distillation 타겟이 결정론적 샘플러보다 두 배 큰 샘플링 단계를 밟는 것에 해당한다는 것입니다.
우리는 그림 15에서 다양한 유도 강도 w를 가진 샘플에 대한 시각화를 제공합니다.
B.5. Baseline samples
우리는 그림 16과 그림 17에서 DDIM 베이스라인에 대한 추가 샘플을 제공합니다.
B.6. Extra distillation results
우리는 그림 22b, 그림 22a 및 표 4의 ImageNet 64x64 및 CIFAR-10에 대한 방법 및 베이스라인에 대한 FID 및 IS 결과를 제공합니다.
또한 그림 18과 그림 19의 두 데이터 세트에 대한 FID 및 IS 트레이드오프 곡선을 시각화하여 ImageNet 64x64에 대해 안내 강도 w = {0, 0.3, 1, 2, 4}를 선택하고 CIFAR-10에 대해 w = {0, 0.1, 0.2, 0.3, 0.5, 1, 2, 4}를 선택합니다.
B.7. Style transfer
우리는 이 실험을 위해 ImageNet 64x64에 초점을 맞추고 있습니다.
[41]에서 논의된 바와 같이, 도메인 A에서 diffusion 모델 학습을 사용하여 이미지를 인코딩(역 DDIM 수행)한 다음 도메인 B에서 학습된 diffusion 모델로 DDIM을 사용하여 디코딩함으로써 도메인 A와 B 사이의 Style transfer를 수행할 수 있습니다.
우리는 알고리즘 4를 사용하여 모델을 학습합니다.
우리는 부록 B.3에서 논의된 것과 동일한 w 조건 모델 아키텍처 및 학습 설정을 사용합니다.