2023. 5. 30. 17:56ㆍDiffusion
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, Mark Chen
Abstract
Diffusion 모델은 최근 고품질 합성 이미지를 생성하는 것으로 나타났는데, 특히 충실도를 위해 다양성을 절충하는 지침 기술과 결합할 때 그렇습니다.
텍스트-조건적 이미지 합성 문제에 대한 diffusion 모델을 탐색하고 두 가지 다른 지침 전략을 비교합니다: CLIP 지침 및 classifier-free 지침.
우리는 후자가 인간 평가자가 사진 현실성과 캡션 유사성 모두를 위해 선호한다는 것을 발견하고 종종 사진 현실성 샘플을 생산합니다.
classifier-free 지침을 사용하는 35억 매개 변수 텍스트 조건적 diffusion 모델의 샘플은 DALL-E의 것보다 인간 평가자가 선호합니다.
심지어 DALL-E의 것은 값비싼 CLIP 재랭킹을 사용하는 경우에도 마찬가지입니다.
또한 이미지 인페인팅을 수행하도록 모델을 미세 조정할 수 있어 강력한 텍스트 기반 이미지 편집이 가능합니다.
1. Introduction
삽화, 그림 및 사진과 같은 이미지는 종종 텍스트를 사용하여 쉽게 설명할 수 있지만, 만들기 위해서는 전문적인 기술과 몇 시간의 노동이 필요할 수 있습니다.
따라서, 자연어로 사실적인 이미지를 생성할 수 있는 도구는 인간이 풍부하고 다양한 시각적 콘텐츠를 전례 없이 쉽게 만들 수 있도록 지원할 수 있습니다.
자연어를 사용하여 이미지를 편집할 수 있기 때문에 반복적인 정교함과 세분화된 제어가 가능하며, 이 두 가지 모두 실제 애플리케이션에 중요합니다.
최근의 텍스트 조건적 이미지 모델은 자유 형식 텍스트 프롬프트에서 이미지를 합성할 수 있으며 의미론적으로 타당한 방식으로 관련이 없는 개체를 구성할 수 있습니다(Xu et al., 2017; Zhu et al., 2019; Tao et al., 2020; Ramesh et al., 2021; Zhang et al., 2021).
그러나 아직 해당 텍스트 프롬프트의 모든 측면을 캡처하는 사실적인 이미지를 생성할 수 없습니다.
반면에, 무조건적인 이미지 모델은 때때로 인간이 실제 이미지 (Zhou et al., 2019)와 구별할 수 없을 정도로 충분한 충실도로 사실적인 이미지 (Brock et al., 2018; Karras et al., 2019a;b; Razavi et al., 2019)를 합성할 수 있습니다.
이러한 연구 라인 내에서 diffusion 모델(Sohl-Dickstein et al., 2015; Song & Ermon, 2020b)은 여러 이미지 생성 벤치마크에서 SOTA 샘플 품질을 달성하면서 유망한 생성 모델군으로 부상했습니다(Ho et al., 2020; Dhariwal & Nichol, 2021; Ho et al.).
클래스-조건적 설정에서 사진 현실주의를 달성하기 위해, Dhariwal & Nichol(2021)은 diffusion 모델이 분류기의 레이블을 조건화할 수 있는 기술인 classifier guidance를 사용하여 증강된 diffusion 모델을 제공합니다.
classifier는 먼저 노이즈가 있는 이미지에 대해 학습되며, diffusion 샘플링 프로세스 동안 classifier의 그레디언트가 샘플을 레이블 쪽으로 안내하는 데 사용됩니다.
Ho & Salimans(2021)는 레이블이 있는 diffusion 모델의 예측 사이를 보간하는 일종의 지침인 classifier-free guidance를 사용하여 별도로 학습된 classifier 없이 유사한 결과를 달성했습니다.
사실적인 샘플을 생성하는 유도 diffusion 모델의 능력과 자유 형식 프롬프트를 처리하는 text-to-image 모델의 능력에 자극을 받아, 우리는 유도 diffusion을 텍스트 조건적 이미지 합성 문제에 적용합니다.
먼저 텍스트 인코더를 사용하여 자연어 설명을 조건화하는 35억 매개 변수 diffusion 모델을 학습합니다.
다음으로 텍스트 프롬프트로 diffusion 모델을 안내하는 두 가지 기술을 비교합니다: CLIP guidance 및 classifier-free guidance.
인간 및 자동화된 평가를 사용하여 classifier-free guidance가 더 높은 품질의 이미지를 생성한다는 것을 발견했습니다.
우리는 classifier-free guidance로 생성된 모델의 샘플이 사실적이고 광범위한 세계 지식을 반영한다는 것을 발견했습니다.
인간 심사위원들에 의해 평가될 때, 우리의 샘플은 사진 현실성을 평가할 때 DALL-E (Ramesh et al., 2021)의 샘플보다 87% 선호됩니다, 그리고 캡션 유사성을 평가할 때 69%의 시간을 차지합니다.
우리 모델은 다양한 텍스트 프롬프트를 제로샷으로 렌더링할 수 있지만 복잡한 프롬프트에 대한 현실적인 이미지를 생성하는 데 어려움을 겪을 수 있습니다.
따라서 우리는 제로샷 생성 외에도 편집 기능을 모델에 제공하여 인간이 더 복잡한 프롬프트와 일치할 때까지 모델 샘플을 반복적으로 개선할 수 있습니다.
특히, 우리는 자연어 프롬프트를 사용하여 기존 이미지를 사실적으로 편집할 수 있음을 발견하고 이미지 인페인팅을 수행하도록 모델을 미세 조정합니다.
모델에서 생성된 편집은 설득력 있는 그림자 및 반사를 포함하여 주변 컨텍스트의 스타일과 조명과 일치합니다.
이러한 모델의 미래 응용 프로그램은 인간이 전례 없는 속도와 용이성으로 매력적인 사용자 지정 이미지를 만드는 데 잠재적으로 도움이 될 수 있습니다.
우리는 우리의 결과 모델이 설득력 있는 허위 정보 또는 딥페이크를 생성하는 데 필요한 노력을 크게 줄일 수 있다는 것을 관찰합니다.
향후 연구를 지원하면서 이러한 사용 사례로부터 보호하기 위해 필터링된 데이터 세트에 대해 학습된 더 작은 diffusion 모델과 노이즈가 있는 CLIP 모델을 출시합니다.
우리는 우리의 시스템을 GLIDE라고 부르는데, GLIDE는 Guided Language to Image Diffusion for Generation and Editing를 나타냅니다.
우리는 우리의 작은 필터링 모델을 GLIDE(필터링된)라고 부릅니다.
2. Background
다음 섹션에서는 평가할 최종 모델의 구성 요소에 대해 개략적으로 설명합니다: diffusion, classifier-free guidance, 및 CLIP guidance.
2.1. Diffusion Models
우리는 Sohl-Dickstein et al.(2015)에 의해 도입되고 Song & Ermon(2020b); Ho et al. (2020)에 의해 개선된 가우시안 diffusion 모델을 고려합니다.
데이터 분포 x_0 ~ q(x_0)의 샘플이 주어지면 샘플에 가우시안 노이즈를 점진적으로 추가하여 잠재 변수 x_1, ..., x_T의 마르코프 체인을 생성합니다:

각 단계에서 추가된 노이즈의 크기 1 - α_t가 충분히 작으면 posterior q(x_(t-1)|x_t)는 대각선 가우시안에 의해 잘 근사됩니다.
또한 체인 전체에 추가된 총 노이즈의 크기 1 - α_1... α_T가 충분히 클 경우 x_T는 N(0, I)에 의해 잘 근사됩니다.
이러한 특성은 모델 p_θ(x_(t-1)|x_t)를 학습하여 실제 posterior를 근사화할 것을 제안합니다:

가우시안 노이즈 x_T ~ N(0, I)으로 시작하여 단계 x_(T-1), x_(T-2), ..., x_0의 순서로 노이즈를 점진적으로 줄여 샘플 x_0 ~ p_θ(x_0)를 생성하는 데 사용할 수 있습니다.
log p_θ(x_0)에 다루기 쉬운 변동 하한이 존재하지만 VLB의 항을 다시 가중치하는 surrogate objective를 최적화하면 더 나은 결과가 발생합니다.
이 surrogate objective를 계산하기 위해 가우시안 노이즈 ε을 x_0에 적용하여 샘플 x_θ ~ q(x_t|x_0)을 생성한 다음 표준 평균 제곱 오류 loss를 사용하여 추가 노이즈를 예측하도록 모델 ε_θ를 학습합니다:

Ho et al. (2020)은 ε_θ(x_t, t)에서 μ_θ(x_t)를 도출하고 ∑_θ를 상수로 고정하는 방법을 보여줍니다.
또한 score 함수 ∇_x_t log p(x_t) ∝ ε_θ(x_t, t)를 사용하여 이전 디노이징 score-matching 기반 모델(Song & Ermon, 2020b;a)과 동등함을 보여줍니다.
후속 작업에서 Nichol & Dhariwal(2021)은 모델이 더 적은 diffusion 단계로 고품질 샘플을 생산할 수 있도록 하는 ∑_θ 학습 전략을 제시합니다.
우리는 이 논문에서 모델을 학습하는 데 이 기술을 채택합니다.
diffusion 모델은 또한 이미지 초해상도에도 성공적으로 적용되었습니다(Nichol & Dhariwal, 2021; Saharia et al., 2021b).
표준 diffusion 공식에 따라 고해상도 이미지 y_0은 일련의 단계에서 점진적으로 노이즈가 발생합니다.
그러나 p_θ(y_(t-1)|y_t, x) 채널 차원에서 x(바이큐빅 업샘플링)를 연결하여 모델에 제공되는 다운샘플링된 입력 x에 대한 추가 조건입니다.
이러한 모델의 결과는 FID, IS 및 인간 비교 점수에서 이전 방법을 능가합니다.
2.2. Guided Diffusion
Dhariwal & Nichol(2021)은 클래스 조건적 diffusion 모델의 샘플이 종종 classifier guidance로 개선될 수 있다는 것을 발견했습니다, 여기서 평균 μ_θ(x_t|y)와 분산 ∑_θ(x_t|y)를 갖는 클래스 조건적 diffusion 모델은 classifier에 의해 예측된 타겟 클래스 y의 로그 확률 log p_θ(y|x_t)의 그래디언트에 의해 추가적으로 교란됩니다.
결과적으로 새로운 섭동 평균 ^μ_θ(x_t|y)는

에 의해 주어집니다.
계수 s를 guidance 척도라고 하며, Dhariwal & Nichol(2021)은 s를 증가시키면 다양성을 희생하여 샘플 품질이 향상된다는 것을 발견했습니다.
2.3. Classifier-free guidance
Ho & Salimans(2021)는 최근 별도의 classifier 모델을 학습시킬 필요가 없는 diffusion 모델을 안내하는 기술인 classifier-free guidance를 제안했습니다.
classifier-free guidance를 위해 클래스 조건적 diffusion 모델 ε_θ(x_t|y)의 레이블 y는 학습 중 고정 확률로 Null 레이블 ø로 대체됩니다.
샘플링 중에 모델의 출력은 다음과 같이 ε_θ(x_t|y) 방향으로 더 외삽되고 ε_θ(x_t|ø)에서 멀리 떨어져 있습니다:

여기서 s ≥ 1은 guidance 척도입니다.
이 함수 형태는 암시적 classifier

에서 영감을 얻었으며, 이 classifier의 그래디언트는 실제 점수 ε*로 기록될 수 있습니다
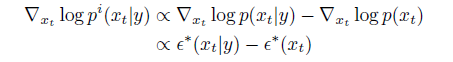
일반 텍스트 프롬프트로 classifier-free guidance를 구현하기 위해 학습 중에 텍스트 캡션을 빈 시퀀스(ø이라고도 함)로 바꾸기도 합니다.
그런 다음 수정된 예측 ^ε를 사용하여 캡션 c로 안내합니다:

classifier-free guidance에는 두 가지 매력적인 특성이 있습니다.
첫째, 별도의(때로는 더 작은) 분류 모델의 지식에 의존하지 않고 단일 모델이 지침을 제공하는 동안 자체 지식을 활용할 수 있습니다.
둘째, classifier(예: 텍스트)로 예측하기 어려운 정보를 조건화할 때 지침을 단순화합니다.
2.4. CLIP Guidance
Radford et al. (2021)은 CLIP을 텍스트와 이미지 간의 공동 표현을 학습하기 위한 확장 가능한 접근 방식으로 도입했습니다.
CLIP 모델은 두 개의 개별 조각으로 구성됩니다: 이미지 인코더 f(x) 및 캡션 인코더 g(c).
학습 중, (x, c) 쌍의 배치는 큰 데이터 세트에서 샘플링되며, 모델은 이미지 x가 주어진 캡션 c와 쌍을 이루는 경우 높은 도트 곱 f(x) · g(c) 또는 이미지와 캡션이 학습 데이터의 다른 쌍에 해당하는 경우 낮은 도트 곱을 장려하는 대조적인 교차 엔트로피 loss를 최적화합니다.
CLIP은 이미지가 캡션에 얼마나 가까운지에 대한 score를 제공하기 때문에, 여러 연구에서 GAN과 같은 생성 모델을 사용자 정의 텍스트 캡션으로 조정하기 위해 사용했습니다(Galatolo et al., 2021; Patashnik et al., 2021; Murdock, 2021; Gal et al., 2021).
동일한 아이디어를 diffusion 모델에 적용하기 위해 classifier guidance에서 classifier를 CLIP 모델로 대체할 수 있습니다.
특히, 우리는 이미지에 대한 이미지 및 캡션 인코딩의 도트 곱 그래디언트로 역 프로세스 평균을 교란합니다:

classifier guidance와 유사하게, 역 프로세스에서 올바른 그래디언트를 얻기 위해 노이즈가 있는 이미지 x_t에 대해 CLIP을 학습해야 합니다.
실험 전반에 걸쳐 노이즈를 인식하도록 명시적으로 학습된 CLIP 모델을 사용하며, 이를 노이즈가 있는 CLIP 모델이라고 합니다.
이전 연구 Crowson(2021a;b)은 노이즈가 있는 이미지에 대해 학습되지 않은 공개 CLIP 모델을 여전히 diffusion 모델을 안내하는 데 사용할 수 있음을 보여주었습니다.
부록 D에서 우리는 노이즈가 있는 CLIP guidance가 데이터 확대 또는 지각 loss와 같은 추가적인 트릭을 요구하지 않고 이 접근 방식에 유리하게 수행된다는 것을 보여줍니다.
우리는 공개 CLIP 모델을 사용한 guidance가 샘플 추출 중에 마주치는 노이즈가 있는 중간 이미지가 모델에 대한 분포를 벗어났기 때문에 샘플 품질에 악영향을 미친다는 가설을 세웠습니다.
3. Related Work
많은 연구가 텍스트 조건적 이미지 생성 문제에 접근했습니다.
Xu et al. (2017); Zhu et al. (2019); Tao et al. (2020); Zhang et al. (2021); Ye et al. (2021)은 공개적으로 사용 가능한 이미지 캡션 데이터 세트를 사용하여 텍스트 조건화로 GAN을 학습합니다.
Rameshe et al. (2021)은 Van den Oord et al. (2017)의 접근 방식을 기반으로 텍스트에 조건화된 이미지를 합성하며, 여기서 자기 회귀 생성 모델은 이산 잠재 코드 위에서 학습됩니다.
우리의 연구와 동시에 Gu et al. (2021)은 이산 잠재 코드 위에 텍스트 조건적 이산 diffusion 모델을 학습하여 결과 시스템이 경쟁력 있는 이미지 샘플을 생성할 수 있음을 발견합니다.
여러 작품이 diffusion 모델로 그림 속 이미지를 탐구했습니다.
Meng et al. (2021)은 diffusion 모델이 이미지의 인페인트 영역에서만 가능할 뿐만 아니라 이미지에 대한 대략적인 스케치(또는 색상 세트)에 따라 조정될 수 있다는 것을 발견했습니다.
Saharia et al.(2021a)은 인페인팅 작업에 대해 직접 학습할 때 diffusion 모델이 가장자리 아티팩트 없이 이미지의 인페인트 영역에서 원활하게 수행될 수 있음을 발견했습니다.
CLIP은 이전에 이미지 생성을 안내하는 데 사용되었습니다.
Galatolo et al. (2021), Patashnik et al. (2021); Murdock (2021); Gal et al. (2021)은 CLIP을 사용하여 GAN 생성을 텍스트 프롬프트로 안내합니다.
온라인 AI 생성 예술 커뮤니티는 CLIP 유도 무노이즈 diffusion을 사용하여 유망한 초기 결과를 산출했습니다(Crowson, 2021a;b).
Kim & Ye(2021)는 원본 이미지의 DDIM(Song et al., 2020a) 잠재를 재구성하면서 CLIP loss를 타겟으로 diffusion 모델을 미세 조정하여 텍스트 프롬프트를 사용하여 이미지를 편집합니다.
Zhou et al. (2021)은 교란된 CLIP 이미지 임베딩에 대해 조건화된 GAN 모델을 학습하여 CLIP 텍스트 임베딩에 이미지를 조건화할 수 있는 모델을 생성합니다.
이러한 작업 중 어느 것도 노이즈가 있는 CLIP 모델을 탐색하지 않으며, 결과적으로 데이터 증가 및 지각 loss에 의존하는 경우가 많습니다.
여러 작품이 텍스트 기반 이미지 편집을 탐구했습니다.
Zhang et al. (2020)은 이미지의 누락된 영역을 그리기 위해 텍스트 임베딩을 사용하기 위한 듀얼 어텐션 메커니즘을 제안합니다.
Stap et al. (2020)은 텍스트에 근거한 피쳐 벡터를 사용하여 얼굴의 이미지를 편집하는 방법을 제안합니다.
Bau et al. (2021)은 CLIP을 SOTA GAN 모델과 쌍을 이루어 텍스트 타겟을 사용하여 이미지를 그립니다.
Abrahami et al. (2021)은 우리의 작업과 동시에 CLIP-guided diffusion을 사용하여 텍스트에 조건적인 이미지 영역을 인페인팅합니다.
4. Training
우리의 주요 실험을 위해, 우리는 해상도를 256x256으로 높이기 위해 35억 매개 변수 텍스트 조건적 diffusion 모델과 15억 매개 변수 텍스트 조건적 업샘플링 diffusion 모델을 학습합니다.
CLIP guidance를 위해 노이즈가 많은 64x64 ViT-L CLIP 모델도 학습합니다(Dosovitskiy et al., 2020).
4.1. Text-Conditional Diffusion Models
우리는 Dhariwal & Nichol(2021)이 제안한 ADM 모델 아키텍처를 채택하지만 텍스트 조건화 정보로 이를 보완합니다.
각 노이즈가 있는 이미지 x_t와 해당 텍스트 캡션 c에 대해, 우리 모델은 p(x_(t-1)|x_t, c)를 예측합니다.
텍스트를 조건화하기 위해 먼저 일련의 K 토큰으로 인코딩하고 이러한 토큰을 트랜스포머 모델에 공급합니다(Vaswani et al., 2017).
이 트랜스포머의 출력은 두 가지 방식으로 사용됩니다:
첫째, 최종 토큰 임베딩은 ADM 모델의 클래스 임베딩 대신 사용됩니다;
둘째, 토큰 임베딩의 마지막 레이어(K 피쳐 벡터의 시퀀스)은 ADM 모델 전체의 각 어텐션 레이어의 차원에 개별적으로 투영된 다음 각 레이어의 어텐션 컨텍스트에 연결됩니다.
우리는 DALL-E와 동일한 데이터 세트에서 모델을 학습합니다(Ramesh et al., 2021).
우리는 Dhariwal & Nichol(2021)의 ImageNet 64x64 모델과 동일한 모델 아키텍처를 사용하지만 모델 폭을 512 채널로 확장하여 모델의 시각적 부분에 약 23억 개의 매개 변수를 생성합니다.
텍스트 인코딩 트랜스포머의 경우 폭 2048의 잔여 블록 24개를 사용하여 약 12억 개의 매개 변수를 생성합니다.
또한 15억 매개 변수 업샘플링 diffusion 모델을 64x64에서 256x256 해상도로 학습합니다.
이 모델은 기본 모델과 동일한 방식으로 텍스트를 조건으로 하지만 2048 대신 폭이 1024인 더 작은 텍스트 인코더를 사용합니다.
그렇지 않으면 아키텍처는 기본 채널 수를 384개로 늘린다는 점을 제외하고 Dhariwal & Nichol(2021)의 ImageNet 업샘플러와 일치합니다.
우리는 배치 크기 2048에서 2.5M 반복을 위한 기본 모델을 학습합니다.
우리는 배치 크기 512에서 1.6M 반복에 대한 업샘플링 모델을 학습합니다.
우리는 이러한 모델이 16비트 정밀도와 전통적인 loss 스케일링으로 안정적으로 학습된다는 것을 발견했습니다(Micikevicius et al., 2017).
총 학습 계산은 DALL-E 학습에 사용된 계산과 거의 같습니다.
4.2. Fine-tuning for classifier-free guidance
초기 학습 실행 후, 우리는 무조건적인 이미지 생성을 지원하기 위해 기본 모델을 미세 조정했습니다.
이 학습 절차는 텍스트 토큰 시퀀스의 20%가 빈 시퀀스로 대체된다는 점을 제외하면 사전 학습과 동일합니다.
이러한 방식으로 모델은 텍스트 조건적 출력을 생성할 수 있지만 무조건적 이미지를 생성할 수도 있습니다.
4.3. Image Inpainting
인페인팅에 diffusion 모델을 사용하는 대부분의 이전 작업은 이 작업에 대해 diffusion 모델을 명시적으로 학습하지 않았습니다(Sohl-Dickstein et al., 2015; Song et al., 2020b; Meng et al., 2021).
특히, diffusion 모델 인페인팅은 평소와 같이 diffusion 모델에서 샘플링하지만, 각 샘플링 단계 후 이미지의 알려진 영역을 q(x_t|x_0)의 샘플로 대체하여 수행할 수 있습니다.
이는 모델이 샘플링 프로세스 중에 전체 컨텍스트를 볼 수 없다는 단점이 있으며(노이즈가 발생한 버전만 해당), 때때로 초기 실험에서 원하지 않는 에지 아티팩트가 발생합니다.
더 나은 결과를 얻기 위해 Saharia et al. (2021a)와 유사하게 인페인팅을 수행하도록 모델을 명시적으로 미세 조정합니다.
미세 조정 중에 학습 예제의 랜덤 영역이 지워지고 나머지 부분은 추가 조건화 정보로 마스크 채널과 함께 모델에 제공됩니다.
모델 아키텍처를 수정하여 4개의 추가 입력 채널을 제공합니다: 두 번째 RGB 채널 세트 및 마스크 채널.
우리는 미세 조정하기 전에 이러한 새로운 채널에 대한 해당 입력 가중치를 0으로 초기화합니다.
업샘플링 모델의 경우 항상 전체 저해상도 이미지를 제공하지만 고해상도 이미지의 마스크되지 않은 영역만 제공합니다.
4.4. Noised CLIP models
Dhariwal & Nichol(2021)의 classifier guidance 기술과 더 잘 일치시키기 위해, 우리는 노이즈가 있는 이미지 x_t를 수신하고 그렇지 않으면 원래 CLIP 모델과 동일한 objective로 학습되는 이미지 인코더 f(x_t, t)를 사용하여 노이즈가 있는 CLIP 모델을 학습합니다.
우리는 이러한 모델을 기본 모델과 동일한 노이즈 스케줄로 64x64 해상도로 학습합니다.

5. Results
5.1. Qualitative Results
그림 5에서 CLIP guidance를 classifier-free guidance와 시각적으로 비교하면 classifier-free guidance의 샘플이 CLIP guidance를 사용하여 생성된 것보다 더 현실적으로 보이는 경우가 많습니다.
우리의 나머지 샘플은 classifier-free guidance를 사용하여 생산되며, 이 선택은 다음 섹션에서 정당화됩니다.
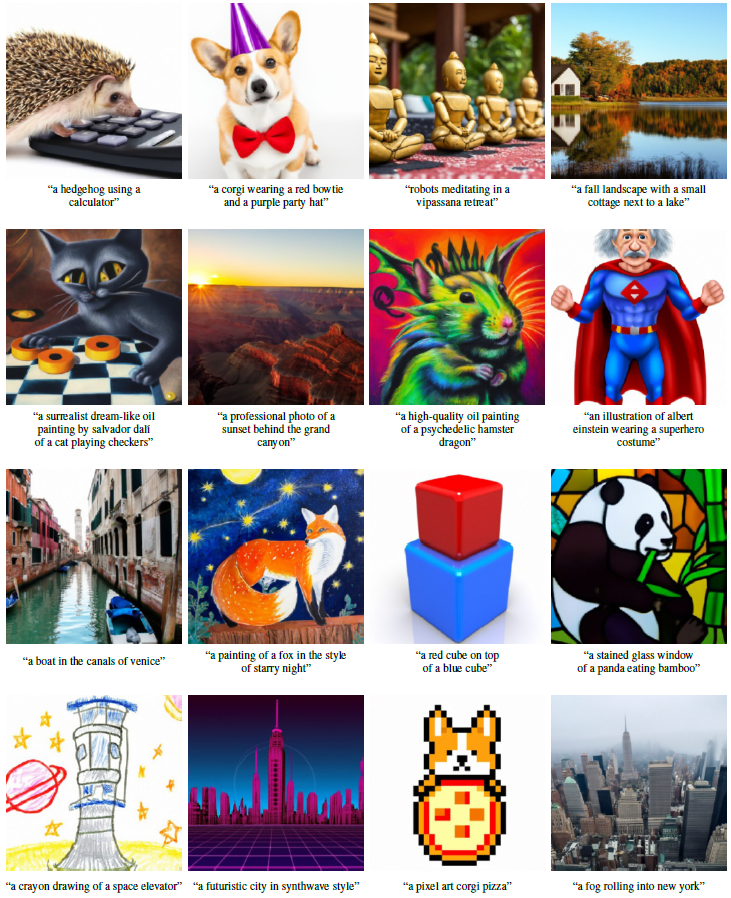
그림 1에서 우리는 classifier-free guidance를 가진 GLIDE가 다양한 프롬프트로 일반화할 수 있음을 관찰합니다.
이 모델은 종종 고품질 텍스처뿐만 아니라 사실적인 그림자와 반사를 생성합니다.
또한 특정 예술가나 그림의 스타일과 같은 다양한 스타일의 일러스트레이션 또는 픽셀 아트와 같은 일반적인 스타일의 일러스트레이션을 제작할 수 있습니다.
마지막으로 모델은 여러 개념(예: a corgi, bowtie, 및 birthday hat)을 구성하는 동시에 속성(예: colors)을 이러한 개체에 바인딩할 수 있습니다.


인페인팅 작업에서, 우리는 GLIDE가 텍스트 프롬프트를 사용하여 기존 이미지를 현실적으로 수정하고, 필요할 때 새로운 객체, 그림자 및 반사를 삽입할 수 있다는 것을 발견했습니다(그림 2).
이 모델은 객체를 그림으로 편집할 때 스타일을 일치시킬 수도 있습니다.
우리는 또한 그림 4의 SDEdit(Meng et al., 2021)을 실험하여 우리의 모델이 스케치를 현실적인 이미지 편집으로 전환할 수 있음을 발견했습니다.
그림 3에서는 GLIDE를 반복적으로 사용하여 제로샷 생성 후 일련의 인페인팅 편집을 사용하여 복잡한 장면을 생성하는 방법을 보여줍니다.

그림 5에서, 우리는 우리의 모델을 MS-COCO의 캡션에 대한 이전의 SOTA 텍스트-조건적 이미지 생성 모델과 비교하여 CLIP의 순위 변경이나 체리픽 없이 더 현실적인 이미지를 생성한다는 것을 발견했습니다.
추가 정성적 비교는 부록 C, D, E를 참조하십시오.

5.2. Quantitative Results
우리는 먼저 품질 충실도 트레이드오프의 Pareto frontier를 살펴 classifier-free guidance와 CLIP guidance 간의 차이를 평가합니다.
그림 6에서 우리는 64x64 해상도에서 제로샷 MS-COCO 생성에 대한 두 가지 접근 방식을 평가합니다.
Precision/Recall(Kynk¨a¨anniemi et al., 2019), FID(Huesel et al., 2017), Inception Score(Salimans et al., 2016), CLIP score(Radford et al., 2021)를 살펴봅니다.
두 가지 guidance 척도를 모두 늘리면 FID vs. IS, Precision vs. Recall, CLIP score vs. FID.
앞의 두 곡선에서 classifier-free guidance가 (거의) 파레토 최적임을 발견했습니다.
FID에 대해 CLIP score를 표시할 때는 정반대의 추세를 볼 수 있습니다.
특히 CLIP guidance는 classifier-free guidance보다 CLIP score를 훨씬 더 높일 수 있는 것으로 보입니다.
우리는 CLIP guidance가 프롬프트를 일치시킬 때 classifier-free guidance를 실제로 능가하는 것이 아니라 평가 CLIP 모델에 대한 적대적인 예를 찾는 것이라고 가정합니다.
이 가설을 검증하기 위해 인간 평가자를 사용하여 생성된 이미지의 샘플 품질을 판단했습니다.
이 설정에서 인간 평가자는 2개의 256x256 이미지를 제공하며, 1) 주어진 캡션과 더 잘 일치하거나 2) 더 사실적으로 보이는 샘플을 선택해야 합니다.
인간 평가자는 또한 어느 이미지도 다른 이미지보다 현저히 좋지 않다는 것을 나타낼 수 있으며, 이 경우 승리의 절반이 두 모델에 할당됩니다.


인간 평가 프로토콜을 사용하여 먼저 두 가지 접근 방식에 대한 guidance 척도를 개별적으로 스위프한 다음(그림 7), 두 가지 방법을 이전 단계의 최상의 척도와 비교합니다(표 1).
우리는 인간이 CLIP score에 동의하지 않고 해당 프롬프트와 더 일치하는 고품질 샘플을 산출하기 위한 classifier-free guidance를 찾는 것을 발견했습니다.

우리는 또한 GLIDE를 다른 텍스트 조건 생성 이미지 모델과 비교합니다.
표 2에서 우리는 모델이 이 데이터 세트에 대해 명시적으로 학습하지 않고 MS-COCO에서 경쟁력 있는 FID를 얻는 것을 발견했습니다.
또한 Ramesh et al. (2021)이 수행한 것처럼 학습 세트의 이미지와 유사한 모든 이미지를 제거한 MS-COCO 검증 세트의 하위 집합에 대해 FID를 계산합니다.
따라서 검증 배치가 21% 감소합니다.
우리는 우리의 FID가 이 경우 12.24에서 12.89로 약간 증가한다는 것을 발견했는데, 이는 더 작은 참조 배치를 사용할 때 FID 편향의 변화로 크게 설명될 수 있습니다.

마지막으로 인간 평가 프로토콜(표 3)을 사용하여 GLIDE를 DALL-E와 비교합니다.
GLIDE는 DALL-E와 거의 동일한 학습 계산으로 학습되었지만 훨씬 더 작은 모델(35억 vs. 120억 매개 변수)로 학습되었습니다.
또한 샘플링 지연 시간과 CLIP reranking이 필요하지 않습니다.
우리는 DALL-E와 GLIDE 사이의 세 가지 비교를 수행합니다.
먼저 CLIP reranking을 사용하지 않을 때 두 모델을 비교합니다.
둘째, CLIP reranking은 DALL-E에만 사용합니다.
마지막으로, 우리는 DALL-E에 대해 CLIP reranking을 사용하고 DALL-E에서 사용하는 이산 VAE를 통해 GLIDE 샘플을 투영합니다.
후자를 통해 DALL-E의 블러 샘플이 인간의 판단에 어떻게 영향을 미치는지 평가할 수 있습니다.
우리는 DALL-E 모델에 대해 두 가지 온도를 사용하여 모든 평가를 수행합니다.
우리의 모델은 (VAE 블러링을 통해) GLIDE 샘플 품질을 줄이면서 훨씬 많은 양의 테스트 시간 계산을 사용할 수 있게 함으로써 DALL-E를 선호하는 구성에서도 모든 설정에서 인간 평가자가 선호합니다.
CLIP reranking을 사용하는 DALL-E와 다양한 guidance 전략을 사용하는 GLIDE의 샘플 그리드는 부록 G를 참조하십시오.
6. Safety Considerations
우리의 모델은 가짜이지만 사실적인 이미지를 생성할 수 있으며 미숙한 사용자가 기존 이미지를 빠르게 설득력 있게 편집할 수 있습니다.
결과적으로 안전 장치 없이 모델을 출시하면 설득력 있는 허위 정보 또는 딥페이크를 만드는 데 필요한 기술이 크게 감소할 것입니다.
또한 모델의 샘플은 데이터 세트의 것을 포함하여 다양한 편향을 반영하기 때문에 이를 적용하면 의도치 않게 해로운 사회적 편견을 영구화할 수 있습니다.
이러한 모델을 출시할 때 발생할 수 있는 잠재적인 유해한 영향을 완화하기 위해 모델을 출시하기 전에 학습 이미지를 필터링했습니다.
먼저 CLIP 및 DALL-E를 학습하는 데 사용되는 데이터 세트와 크게 분리된 인터넷에서 수억 개의 이미지 데이터 세트를 수집한 다음 이 데이터에 여러 필터를 적용했습니다.
많은 사람 중심의 문제가 있는 사용 사례에서 모델의 기능을 줄이기 위해 사람이 포함된 학습 이미지를 필터링했습니다.
우리는 또한 우리의 모델이 폭력적인 이미지와 증오의 상징을 만드는 데 사용되는 것에 대한 우려가 있었습니다.
그래서 우리는 이것들 중 몇 가지도 걸러냈습니다.
데이터 필터링 프로세스에 대한 자세한 내용은 부록 F.1을 참조하십시오.
우리는 필터링된 데이터 세트에서 GLIDE (filtered)라고 하는 작은 3억 매개 변수 모델을 학습했습니다.
그런 다음 모델 가중치가 오픈 소스인 경우 GLIDE (filtered)가 오용 위험을 완화하는 방법을 조사했습니다.
일련의 적대적 프롬프트를 사용하여 모델을 레드 팀으로 구성하는 이 조사 동안, 우리는 모델이 인식 가능한 인간 이미지를 생성할 수 있는 사례를 발견하지 못했으며, 이는 우리의 데이터 필터가 충분히 낮은 거짓 음성 비율을 가지고 있음을 시사합니다.
우리는 또한 일부 형태의 편향에 대해 GLIDE (filtered)를 조사했고 데이터 세트에서 편향을 유지하고 심지어 증폭할 수 있다는 것을 발견했습니다.
예를 들어, "toys for girls"을 만들어 달라는 요청을 받았을 때, 우리 모델은 "toys for boys"보다 더 많은 분홍색 장난감과 박제 동물을 생산합니다.
이와는 별도로, 우리는 또한 "a religious place"와 같은 일반적인 문화적 이미지를 요구할 때, 우리의 모델이 종종 서양의 고정관념을 강화한다는 것을 발견했습니다.
우리는 또한 classifier-free guidance를 사용할 때 모델의 편향이 증폭된다는 것을 관찰했습니다.
마지막으로, 우리는 특정 클래스에서 이미지를 생성하는 모델의 기능을 방해했지만, 그것은 추가적인 학제간 연구를 위한 중요한 영역인 오용 가능성을 가진 인페인팅 기능을 유지합니다.
자세한 예제 및 이미지는 부록 F.2를 참조하십시오.
위의 조사에서는 GLIDE (filtered)를 자체적으로 연구하지만 진공 상태에 있는 모델은 없습니다.
예를 들어, 여러 모델을 결합하여 새로운 기능 집합을 얻을 수 있는 경우가 많습니다.
이 문제를 탐구하기 위해 GLIDE (filtered)를 공개적으로 사용 가능한 CLIP 유도 diffusion 프로그램(Crowson, 2021a)으로 바꾸고 결과 모델 쌍의 생성 기능을 연구했습니다.
우리는 일반적으로 CLIP 모델(필터링되지 않은 데이터에 대해 학습됨)이 우리의 모델이 인식 가능한 얼굴 표정이나 혐오스러운 이미지를 생성할 수 있는 반면, 동일한 CLIP 모델은 공개적으로 사용 가능한 ImageNet diffusion 모델과 결합할 때 거의 동일한 품질의 이미지를 생성한다는 것을 발견했습니다.
자세한 내용은 부록 F.2를 참조하십시오.
CLIP 유도 diffusion에 대한 추가 연구를 가능하게 하기 위해 필터링된 데이터 세트에 대해 학습된 노이즈가 있는 ViT-B CLIP 모델도 학습하고 릴리스합니다.
우리는 GLIDE (filtered)를 학습하는 데 사용되는 데이터 세트를 원래 CLIP 데이터 세트의 필터링된 버전과 결합합니다.
이 모델을 레드 팀으로 구성하기 위해 GLIDE (filtered)와 공용 64x64 ImageNet 모델을 모두 안내하는 데 사용했습니다.
우리가 시도한 프롬프트에서, 우리는 새로운 CLIP 모델이 기존의 공개 CLIP 모델에 의해 생성된 그러한 이미지의 품질보다 폭력적인 이미지나 사람들의 이미지의 품질을 크게 향상시키지 않는다는 것을 발견했습니다.
우리는 또한 학습 이미지를 직접 역류시키는 GLIDE (filtered)의 능력을 테스트했습니다.
이 실험을 위해 학습 세트에서 30K 프롬프트에 대한 이미지를 샘플링하고 CLIP 잠재 공간에서 각 생성된 이미지와 원래 학습 이미지 사이의 거리를 계산했습니다.
그런 다음 거리가 가장 작은 쌍을 검사했습니다.
모델은 우리가 검사한 어떤 쌍에서도 학습 이미지를 충실하게 재현하지 못했습니다.
7. Limitations
우리의 모델은 종종 복잡한 방식으로 이질적인 개념을 구성할 수 있지만, 때때로 매우 특이한 개체나 시나리오를 설명하는 특정 프롬프트를 캡처하지 못합니다.
그림 8에서는 이러한 실패 사례의 몇 가지 예를 제공합니다.

최적화되지 않은 모델은 단일 A100 GPU에서 하나의 이미지를 샘플링하는 데 15초가 걸립니다.
이는 단일 전진 패스로 이미지를 생성하는 관련 GAN 방법의 샘플링보다 훨씬 느리기 때문에 실시간 애플리케이션에 사용하기에 더 유리합니다.
'Diffusion' 카테고리의 다른 글
| Projected GANs Converge Faster (1) | 2024.06.15 |
|---|---|
| On Distillation of Guided Diffusion Models (0) | 2023.07.20 |
| DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation (0) | 2023.05.22 |
| Deep Unsupervised Learning using Nonequilibrium Thermodynamics (0) | 2023.03.16 |
| Generative Modeling by Estimating Gradients of the Data Distribution (1) | 2023.01.09 |