2023. 5. 22. 18:23ㆍDiffusion
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
Abstract
대규모 text-to-image 모델은 AI의 진화에서 괄목할 만한 도약을 달성하여 주어진 텍스트 프롬프트에서 고품질의 다양한 이미지 합성을 가능하게 했습니다.
그러나 이러한 모델은 주어진 참조 집합에서 subject의 외관을 모방하고 다른 맥락에서 subject의 새로운 버전을 합성할 수 있는 능력이 부족합니다.
이 연구에서, 우리는 text-to-image 디퓨전 모델의 "personalization"를 위한 새로운 접근법을 제시합니다.
특정 subject의 몇 개의 이미지만 입력하면, 우리는 사전 학습된 text-to-image 모델을 파인튜닝하여 고유 식별자를 해당 특정 subject와 결합하는 방법을 학습합니다.
subject가 모델의 출력 도메인에 포함되면 고유 식별자를 사용하여 서로 다른 장면에서 맥락화된 subject의 새로운 사실적 이미지를 합성할 수 있습니다.
모델에 임베딩된 semantic prior를 새로운 자체 클래스별 prior preservation loss와 함께 활용함으로써 우리의 기술은 참조 이미지에 나타나지 않는 다양한 장면, 포즈, 뷰 및 조명 조건에서 subject를 합성할 수 있습니다.
우리는 subject의 주요 기능을 유지하면서 subject의 재컨텍스트화, 텍스트 가이드 뷰 합성 및 예술적 렌더링을 포함하여 이전에는 사용할 수 없었던 몇 가지 작업에 우리의 기술을 적용합니다.
우리는 또한 subject 중심 생성이라는 이 새로운 작업을 위한 새로운 데이터 세트 및 평가 프로토콜을 제공합니다.
1. Introduction
여러분은 세계를 여행하는 여러분의 개나 여러분이 가장 좋아하는 가방이 파리의 가장 독점적인 쇼룸에 전시되는 것을 상상할 수 있나요?
당신의 앵무새가 삽화가 들어간 이야기책의 주인공이 되는 것은?
이러한 가상 장면을 렌더링하는 것은 특정 subject (예: 물체, 동물)의 인스턴스를 새로운 맥락에서 합성하여 자연스럽게 장면에 원활하게 혼합해야 하는 어려운 작업입니다.
최근 개발된 대규모 text-to-image 모델은 자연어로 작성된 텍스트 프롬프트를 기반으로 고품질의 다양한 이미지 합성을 가능하게 함으로써 전례 없는 기능을 보여주었습니다 [54,61].
이러한 모델의 주요 이점 중 하나는 이미지-캡션 쌍의 대규모 컬렉션에서 학습한 강력한 semantic prior입니다.
예를 들어, 그러한 prior는 이미지에서 다른 포즈와 맥락으로 나타날 수 있는 다양한 개 인스턴스와 "dog"라는 단어를 결합하는 방법을 배웁니다.
이러한 모델의 합성 기능은 전례가 없는 반면, 주어진 참조 집합에서 subject의 외관을 모방하고 다른 맥락에서 동일한subject의 새로운 버전을 합성하는 능력이 부족합니다.
주요 이유는 출력 도메인의 표현력이 제한적이기 때문입니다; 개체에 대한 가장 상세한 텍스트 설명조차도 다른 외관의 인스턴스를 생성할 수 있습니다.
또한, 텍스트 임베딩이 공유 언어-비전 공간에 있는 모델도 [52] 주어진 subject의 모양을 정확하게 재구성할 수 없고 이미지 콘텐츠의 변형만 생성합니다(그림 2).

이 연구에서, 우리는 text-to-image 디퓨전 모델의 "personalization"을 위한 새로운 접근법을 제시합니다(사용자별 이미지 생성 요구에 적응).
우리의 목표는 모델의 언어-비전 사전을 확장하여 사용자가 생성하고자 하는 특정 subject와 새로운 단어를 결합하는 것입니다.
새 사전이 모델에 포함되면 이러한 단어를 사용하여 서로 다른 장면에서 맥락화된 subject의 새로운 사실적 이미지를 합성하는 동시에 주요 식별 기능을 보존할 수 있습니다.
이 효과는 "magic photo booth"와 유사합니다—일단 subject의 몇 개의 이미지가 촬영되면 부스는 간단하고 직관적인 텍스트 프롬프트에 따라 다양한 조건과 장면에서 subject의 사진을 생성합니다 (그림 1).

좀 더 공식적으로, subject의 몇 개의 이미지(~3-5)가 주어지면, 우리의 objective는 고유한 식별자로 합성될 수 있도록 subject를 모델의 출력 영역에 이식하는 것입니다.
이를 위해 주어진 subject를 희귀 토큰 식별자로 표현하고 사전 학습된 디퓨전 기반 text-to-image 프레임워크를 파인튜닝하는 기술을 제안합니다.
우리는 고유 식별자가 포함된 입력 이미지와 텍스트 프롬프트와 subject의 클래스 이름(예: "A [V] dog")을 사용하여 text-to-image 모델을 파인튜닝합니다.
후자는 클래스별 인스턴스가 고유 식별자로 바인딩되는 동안 모델이 subject 클래스에 대한 prior 지식을 사용할 수 있도록 합니다.
모델이 클래스 이름(예: "dog")을 특정 인스턴스와 연관시키는 언어 드리프트를 방지하기 위해, 우리는 모델에 임베딩된 클래스 semantic prior를 활용하는 자동적이고 클래스별 prior preservation loss를 제안합니다, 그리고 우리의 subject와 같은 클래스의 다양한 사례를 생성하도록 장려합니다.
우리는 subject의 재텍스트화, 속성 수정, 원본 아트 렌더링 등을 포함한 수많은 텍스트 기반 이미지 생성 애플리케이션에 우리의 접근 방식을 적용하여 이전에는 불가능했던 작업의 새로운 흐름으로 가는 길을 열었습니다.
ablation 연구를 통해 방법에서 각 구성 요소의 기여도를 강조하고 대체 베이스라인 및 관련 작업과 비교합니다.
또한 다른 접근 방식과 비교하여 합성된 이미지의 subject 및 프롬프트 충실도를 평가하기 위해 사용자 연구를 수행합니다.
우리가 아는 한, 우리의 기술은 subject-중심 생성이라는 새로운 도전적인 문제를 해결하는 첫 번째 기술이며, 사용자는 subject의 몇 개의 무심코 캡처한 이미지에서 독특한 피쳐를 유지하면서 다른 맥락에서 subject의 새로운 버전을 합성할 수 있습니다.
이 새로운 작업을 평가하기 위해 서로 다른 맥락에서 캡처된 다양한 subject를 포함하는 새로운 데이터 세트를 구성하고, 생성된 결과의 subject 충실도와 프롬프트 충실도를 측정하는 새로운 평가 프로토콜을 제안합니다.
우리는 우리의 데이터 세트와 평가 프로토콜을 프로젝트 웹 페이지에서 공개적으로 사용할 수 있도록 합니다.
2. Related work
Image Composition.
이미지 합성 기술 [13, 38, 70]은 주어진 대상을 새로운 배경으로 복제하여 대상이 장면에 혼합되도록 하는 것을 목표로 합니다.
새로운 포즈에서의 구성을 고려하기 위해, 일반적으로 단단한 물체에 작용하고 더 많은 뷰가 필요한 3D 재구성 기술[6, 8, 41, 49, 68]을 적용할 수 있습니다.
일부 단점으로는 장면 통합(조명, 그림자, 접촉) 및 새로운 장면을 생성할 수 없는 경우가 있습니다.
대조적으로, 우리의 접근 방식은 새로운 포즈와 새로운 맥락에서 대상을 생성할 수 있습니다.
Text-to-Image Editing and Synthesis.
텍스트 기반 이미지 조작은 최근 CLIP [52]과 같은 image-text 표현과 결합된 GAN [9, 22, 28–30]을 사용하여 상당한 발전을 이루었으며, 텍스트 [2, 7, 21, 43, 48, 71]를 사용한 현실적인 조작을 산출했습니다.
이러한 방법은 구조화된 시나리오(예: 인간 얼굴 편집)에서 잘 작동하며 대상이 더 다양한 데이터 세트에서 어려움을 겪을 수 있습니다.
Crowson et al. [14]은 VQ-GAN[18]을 사용하고 이러한 우려를 완화하기 위해 더 다양한 데이터를 학습합니다.
다른 연구[4, 31]는 최근 diffusion 모델[25, 25, 45, 58, 60, 62–66]을 활용하여 매우 다양한 데이터 세트에서 SOTA 생성 품질을 달성하며 종종 GAN을 능가합니다.
텍스트만을 필요로 하는 대부분의 작업이 전역 편집으로 제한되는 [14, 33]에 비해 Bar-Tal et al. [5]는 마스크를 사용하지 않고 텍스트 기반의 로컬화된 편집 기법을 제안하여 인상적인 결과를 보여주었습니다.
이러한 편집 방법의 대부분은 지정된 이미지의 전역 속성 또는 로컬 편집을 허용하지만, 새 컨텍스트에서 지정된 대상의 새로운 버전을 생성할 수 있는 방법은 없습니다.
text-to-image 합성에 대한 연구도 존재합니다 [14, 16, 19, 24, 27, 35, 36, 50, 51, 55, 58, 67, 74].
Imagen [61], DALL-E2 [54], Parti [72], CogView2 [17] 및 Stable Diffusion[58]과 같은 최근의 large text-to-image 모델은 전례 없는 의미 생성을 보여주었습니다.
이러한 모델은 생성된 이미지에 대한 세부적인 제어를 제공하지 않으며 텍스트 안내만 사용합니다.
구체적으로, 합성된 이미지 전체에서 대상의 정체성을 일관되게 보존하는 것은 어렵거나 불가능합니다.
Controllable Generative Models.
생성 모델을 제어하기 위한 다양한 접근 방식이 있으며, 그 중 일부는 대상 중심의 프롬프트 안내 이미지 합성을 위한 실행 가능한 방향으로 입증될 수 있습니다.
Liu et al. [39]은 참조 이미지 또는 텍스트에 의해 안내되는 이미지 변화를 허용하는 diffusion 기반 기술을 제안합니다.
대상 수정을 극복하기 위해, 몇몇 작업[3, 44]은 수정된 영역을 제한하기 위해 사용자가 제공한 마스크를 가정합니다.
Inversion [12, 15, 54]은 컨텍스트를 수정하는 동안 대상을 보존하는 데 사용할 수 있습니다.
프롬프트-to-프롬프트 [23]을 사용하면 입력 마스크 없이 로컬 및 전역 편집이 가능합니다.
이러한 방법은 대상의 정체성을 보존하는 새로운 샘플 생성에 미치지 못합니다.
GANs의 맥락에서 Pivotal Tuning [57]은 반전된 잠재 코드 앵커로 모델을 미세 조정하여 실제 이미지 편집을 가능하게 하며, Nitzan et al. [46]은 약 100개의 이미지가 필요하고 얼굴 영역으로 제한된 개인화된 prior를 학습하기 위해 이 작업을 얼굴에 대한 GAN 미세 조정으로 확장했습니다.
Casanova et al. [11]은 고유한 대상과 씨름할 수 있고 모든 대상 세부 사항을 보존하지는 않지만 인스턴스의 변형을 생성할 수 있는 인스턴스 조건적 GAN을 제안합니다.
마지막으로, Gal et al. [20]의 동시 작업은 동결된 text-to-image 모델의 임베딩 공간에 새로운 토큰을 통해 객체 또는 스타일과 같은 시각적 개념을 표현하여 작은 개인화된 토큰 임베딩을 생성하는 방법을 제안합니다.
이 방법은 동결된 diffusion 모델의 표현력에 의해 제한되지만, 우리의 미세 조정 접근 방식은 모델의 출력 도메인 내에 대상을 포함시킬 수 있어 주요 시각적 피쳐를 보존하는 대상의 새로운 이미지를 생성할 수 있습니다.
3. Method
텍스트 설명 없이 특정 대상의 일부(일반적으로 3-5개)만 무심코 캡처한 이미지가 주어지면, 우리의 목표는 높은 세부 충실도와 텍스트 프롬프트에 의해 안내되는 변형으로 대상의 새로운 이미지를 생성하는 것입니다.
예를 들어, 대상 위치 변경, 색상 또는 모양과 같은 대상 속성 변경, 대상의 포즈, 뷰 수정 및 기타 의미론적 수정이 있습니다.
우리는 입력 이미지 캡처 설정에 어떠한 제한도 가하지 않으며 대상 이미지는 다양한 컨텍스트를 가질 수 있습니다.
다음으로 text-to-image diffusion 모델(섹션 3.1)에 대한 배경을 제공한 다음, 고유 식별자를 몇 개의 이미지(섹션 3.2)에 설명된 대상과 결합하는 미세 조정 기술을 제시하고, 마지막으로 미세 조정된 모델(섹션 3.3)에서 언어 표류를 극복할 수 있는 클래스별 prior-preservation loss를 제안합니다.
3.1. Text-to-Image Diffusion Models
diffusion 모델은 가우시안 분포에서 샘플링된 변수의 점진적 디노이징을 통해 데이터 분포를 학습하도록 학습된 확률론적 생성 모델입니다.
특히, 우리는 텍스트 인코더 Γ와 텍스트 프롬프트 P를 사용하여 생성된 초기 노이즈 맵 ε ~ N(0, I)과 조건적 벡터 c = Γ(P)가 주어지면 이미지 x_gen = ^x_θ(ε, c)를 생성하는 사전 학습된 text-to-image diffusion 모델 ^x_θ에 관심이 있습니다.
그들은 가변 노이즈 이미지 또는 잠재 코드 z_t := α_t x + σ_t ε를 디노이즈하기 위해 제곱 오류 loss를 사용하여 학습됩니다:
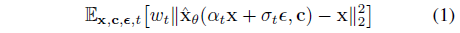
, 여기서 x는 ground truth 이미지이고, c는 조건적 벡터(예: 텍스트 프롬프트에서 얻은 것)이며, α_t, σ_t, ω_t는 노이즈 스케줄과 샘플 품질을 제어하는 항이며 diffusion 프로세스 시간 t ~ U([0, 1])의 함수입니다.
보충 자료에 더 자세한 설명이 나와 있습니다.
3.2. Personalization of Text-to-Image Models
우리의 첫 번째 작업은 모델의 출력 도메인에 대상 인스턴스를 이식하여 대상의 다양한 새로운 이미지에 대해 모델을 쿼리할 수 있도록 하는 것입니다.
한 가지 자연스러운 아이디어는 대상의 퓨샷 데이터 세트를 사용하여 모델을 미세 조정하는 것입니다.
퓨샷 시나리오에서 GAN과 같은 생성 모델을 미세 조정할 때는 과적합 및 모드 붕괴를 유발할 수 있을 뿐만 아니라 타겟 분포를 충분히 포착하지 못할 수 있으므로 세심한 주의가 필요했습니다.
이러한 함정을 피하기 위한 기술에 대한 연구가 있었지만 [37, 42, 47, 56, 69], 비록 우리의 작업과는 대조적으로, 이 작업 라인은 주로 타겟 분포와 유사하지만 대상 보존의 요구 사항이 없는 이미지를 생성하는 것을 추구합니다.
이러한 함정과 관련하여, 우리는 식 1의 diffusion loss를 사용하여 세심한 미세 조정 설정을 고려할 때, large text-to-image diffusion 모델이 작은 학습 이미지 세트에 prior 또는 과적합 없이 새로운 정보를 도메인에 통합하는 데 탁월한 것으로 보인다는 특이한 발견을 관찰합니다.
Designing Prompts for Few-Shot Personalization
우리의 목표는 diffusion 모델의 "dictionary"에 새로운 (unique identifier, subject) 쌍을 "implant"하는 것입니다.
주어진 이미지 세트에 대한 자세한 이미지 설명을 쓰는 오버헤드를 피하기 위해 우리는 더 간단한 접근 방식을 선택하고 대상의 모든 입력 이미지에 "[identifier] [class noun]", 여기서 [identifier]는 대상과 연결된 고유 식별자이고 [class noun]는 대상의 coarse 클래스 설명자(예: cat, dog, watch, etc.)입니다.
클래스 설명자는 사용자가 제공하거나 분류기를 사용하여 얻을 수 있습니다.
우리는 클래스의 prior를 우리의 고유한 대상에 연결하기 위해 문장에서 클래스 설명자를 사용하고 잘못된 클래스 설명자를 사용하거나 클래스 설명자가 없는 것은 학습 시간과 언어 드리프트를 증가시키는 동시에 성과를 감소시킨다는 것을 발견합니다.
본질적으로, 우리는 특정 클래스에 앞서 모델의 prior를 활용하고 대상의 고유 식별자를 내장하여 서로 다른 맥락에서 대상의 새로운 포즈와 관절을 생성하기 전에 시각을 활용할 수 있도록 하려고 합니다.
Rare-token Identifiers
우리는 일반적으로 기존의 영어 단어(예: "unique", "special")를 차선이라고 생각합니다, 왜냐하면 모델은 원래 의미에서 그것들을 분리하고 우리의 대상을 참조하기 위해 그것들을 다시 얽는 법을 배워야 하기 때문입니다.
이것은 언어 모델과 diffusion 모델 모두에서 약한 prior를 하는 식별자의 필요성을 동기화합니다.
이렇게 하는 위험한 방법은 영어에서 임의의 문자를 선택하고 연결하여 희귀 식별자(예: "xxy5syt00")를 생성하는 것입니다.
실제로 토큰화기는 각 문자를 개별적으로 토큰화할 수 있으며, diffusion 모델에 대한 prior 설정은 이러한 문자에 대해 강력합니다.
우리는 종종 이러한 토큰이 일반적인 영어 단어를 사용하는 것과 유사한 약점을 유발한다는 것을 발견합니다.
우리의 접근 방식은 어휘에서 희귀 토큰을 찾은 다음 식별자가 강력한 prior를 가질 확률을 최소화하기 위해 이러한 토큰을 텍스트 공간으로 반전시키는 것입니다.
어휘에서 희귀 토큰 검색을 수행하고 희귀 토큰 식별자 f(^V) 시퀀스를 얻습니다, 여기서 f는 토큰화자; 문자 시퀀스를 토큰에 매핑하는 함수, ^V는 토큰 f(^V)에서 파생된 디코딩된 텍스트입니다.
시퀀스는 가변 길이 k일 수 있으며 k = {1, ..., 3}의 상대적으로 짧은 시퀀스가 잘 작동함을 알 수 있습니다.
그런 다음 f(^V)에서 디토큰화기를 사용하여 어휘를 반전시킴으로써 고유 식별자 ^V를 정의하는 일련의 문자를 얻습니다.
Imagen의 경우 3개 이하의 유니코드 문자(공백 없음)에 해당하는 토큰의 균일한 랜덤 샘플링과 {5000, ..., 10000}의 T5-XXL 토큰화기 범위에서 토큰을 사용하는 것이 잘 작동한다는 것을 발견했습니다.
3.3. Class-specific Prior Preservation Loss
우리의 경험에 따르면, 최대 대상 충실도를 위한 최상의 결과는 모델의 모든 레이어를 미세 조정함으로써 달성됩니다.
여기에는 텍스트 임베딩에 따라 조정되는 미세 조정 레이어가 포함되어 언어 드리프트 문제가 발생합니다.
언어 드리프트는 언어 모델[34, 40]에서 관찰된 문제로, 대규모 텍스트 말뭉치에서 사전 학습되고 나중에 특정 작업에 대해 미세 조정된 모델은 점진적으로 언어에 대한 구문 및 의미론적 지식을 상실합니다.
우리가 아는 한, 우리는 diffusion 모델에 영향을 미치는 유사한 현상을 처음 발견했는데, 여기서 모델은 타겟 대상과 동일한 클래스의 대상을 생성하는 방법을 천천히 잊어버립니다.
또 다른 문제는 출력 다양성의 감소 가능성입니다.
text-to-image diffusion 모델은 자연스럽게 많은 양의 출력 다양성을 보유합니다.
작은 이미지 세트를 미세 조정할 때 새로운 뷰, 포즈 및 관절로 대상을 생성할 수 있기를 바랍니다.
그러나 대상에 대한 출력 포즈 및 뷰의 변동성이 감소할 위험이 있습니다(예: 퓨샷 뷰로 스냅).
우리는 특히 모델이 너무 오랫동안 학습되었을 때 종종 이러한 경우가 있다는 것을 관찰합니다.

앞에서 언급한 두 가지 문제를 완화하기 위해 다양성을 장려하고 언어 이동에 대응하는 자가성 클래스별 prior preservation loss를 제안합니다.
본질적으로, 우리의 방법은 자체 생성된 샘플로 모델을 supervise하여 퓨샷 미세 조정이 시작되면 이전 샘플을 유지하는 것입니다.
이를 통해 클래스에 대한 다양한 이미지를 미리 생성할 수 있을 뿐만 아니라 해당 클래스에 대한 지식을 대상 인스턴스에 대한 지식과 함께 사용할 수 있습니다.
구체적으로, 랜덤 초기 노이즈 z_t_1 ~ N(0, I)과 조건적 벡터 c_pr := Γ(f("a [class noun]")를 가진 frozen 사전 학습된 diffusion 모델에서 조상 샘플러를 사용하여 데이터 x_pr = ^x(z_t_1, c_pr)를 생성합니다.
loss는

가 됩니다, 여기서 두 번째 항은 자체 생성된 이미지로 모델을 supervise하는 prior-preservation 항이며, 이 항의 상대 가중치에 대한 λ 제어입니다.
그림 3은 클래스 생성 샘플과 prior preservation loss를 사용한 모델 미세 조정을 보여줍니다.
단순함에도 불구하고, 우리는 이러한 prior preservation loss가 출력 다양성을 장려하고 언어 이동을 극복하는 데 효과적이라는 것을 발견했습니다.
우리는 또한 과적합 위험 없이 더 많은 반복을 위해 모델을 학습시킬 수 있다는 것을 발견했습니다.
우리는 λ = 1과 Imagen [61]의 경우 학습 속도 10^-5, Stable Diffusion [59]의 경우 5x10^-6을 사용하여 ~1000회 반복하면 좋은 결과를 얻기에 충분하다는 것을 발견했습니다.
이 과정에서 ~1000개의 "a [class nom]" 샘플이 생성되지만 사용할 수 있는 샘플은 더 적습니다.
학습 과정은 Imagen의 경우 TPUv4 1개에서 약 5분, Stable Diffusion을 위한 NVIDIA A100에서 약 5분이 소요됩니다.
4. Experiments
이 섹션에서는 실험과 응용 프로그램을 보여줍니다.
우리의 방법은 재텍스트화, 재료 및 종과 같은 대상 속성의 수정, 예술 렌더링 및 관점 수정을 포함하여 대상 인스턴스의 텍스트 유도 의미론적 수정을 광범위하게 가능하게 합니다.
중요한 것은, 이러한 모든 수정에서 우리는 대상에게 정체성과 본질을 부여하는 고유한 시각적 피쳐를 보존할 수 있다는 것입니다.
작업이 재텍스트화인 경우 대상 피쳐는 수정되지 않지만 외관(예: 포즈)은 변경될 수 있습니다.
과제가 우리의 대상과 다른 종/객체 간의 교차와 같은 더 강력한 의미 수정인 경우, 대상의 주요 피쳐는 수정 후에 보존됩니다.
이 섹션에서는 [V]를 사용하여 대상의 고유 식별자를 참조합니다.
우리는 보충 자료에 특정 Imagen 및 Stable Diffusion 구현 세부 사항을 포함합니다.

4.1. Dataset and Evaluation
Dataset
우리는 backpacks, stuffed animals, dogs, cats, sunglasses, cartoons, etc과 같은 독특한 물건과 애완동물을 포함한 30개 대상의 데이터 세트를 수집했습니다.
우리는 각 대상를 두 가지 범주로 나눕니다: 30개의 대상 중 21개가 객체이고, 9개가 살아있는 대상/애완동물입니다.
우리는 그림 5의 각 대상에 대해 하나의 샘플 이미지를 제공합니다.
이 데이터 세트의 이미지는 작성자가 수집하거나 Unsplash[1]에서 원본으로 가져왔습니다.
또한 25개의 프롬프트를 수집했습니다: 객체에 대한 20개의 재텍스트화 프롬프트 및 5개의 속성 수정 프롬프트; 살아있는 대상/애완동물에 대해 10개의 재텍스트화, 10개의 액세서리화 및 5개의 속성 수정 프롬프트가 표시됩니다.
전체 프롬프트 목록은 보충 자료에서 확인할 수 있습니다.
평가 제품군의 경우 대상당 및 프롬프트당 총 3,000개의 이미지를 생성합니다.
이를 통해 방법의 성능과 일반화 기능을 강력하게 측정할 수 있습니다.
우리는 향후 대상 중심 생성을 평가하는 데 사용할 수 있도록 프로젝트 웹 페이지에서 데이터 세트 및 평가 프로토콜을 공개합니다.
Evaluation Metrics
평가해야 할 한 가지 중요한 측면은 대상 충실도입니다: 생성된 이미지의 대상 세부 정보 보존.
이를 위해 두 가지 메트릭을 계산합니다: CLIP-I 및 DINO [10].
CLIP-I는 생성된 이미지와 실제 이미지의 CLIP [52] 임베딩 사이의 평균 쌍별 코사인 유사성입니다.
이 메트릭은 다른 연구[20]에서 사용되었지만, 텍스트 설명이 매우 유사할 수 있는 다른 대상(예: 두 개의 다른 노란색 시계)를 구별하기 위해 구성되지 않았습니다.
제안된 DINO 메트릭은 생성된 이미지와 실제 이미지의 ViT-S/16 DINO 임베딩 사이의 평균 쌍별 코사인 유사성입니다.
이것은 우리가 선호하는 메트릭입니다, 왜냐하면 DINO는 구조에 의해 그리고 supervised 네트워크와 대조적으로 동일한 클래스의 대상 간의 차이를 무시하도록 학습되지 않았기 때문입니다.
대신, self-supervised training objecitve는 대상 또는 이미지의 고유한 피쳐를 구별하도록 장려합니다.
평가해야 할 두 번째 중요한 측면은 프롬프트와 이미지 CLIP 임베딩 사이의 평균 코사인 유사성으로 측정되는 프롬프트 충실도입니다.
이를 CLIP-T라고 합니다.
4.2. Comparisons
우리는 연구에서 제공된 하이퍼 파라미터를 사용하여 Gal et al. [20]의 최근 동시 연구인 Textual Inversion과 결과를 비교합니다.
우리는 이 작품이 대상 중심, 텍스트 안내 및 새로운 이미지를 생성하는 문헌에서 유일하게 비교 가능한 작품이라는 것을 발견했습니다.
우리는 Imagen을 사용하여 DreamBooth 이미지를 생성하고, Stable Diffusion을 사용하여 DreamBooth 이미지를 생성하며, Stable Diffusion을 사용하여 Textual Inversion을 생성합니다.
우리는 DINO 및 CLIP-I 대상 충실도 메트릭과 CLIP-T 프롬프트 충실도 메트릭을 계산합니다.
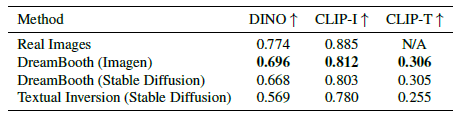
표 1에서 우리는 Textual Inversion에 대한 DreamBooth에 대한 대상 및 즉각적인 충실도 메트릭 모두에서 상당한 차이를 보여줍니다.
우리는 DreamBooth (Imagen)가 DreamBooth (Stable Diffusion)보다 대상과 즉각적인 충실도 모두에서 더 높은 점수를 달성하여 실제 이미지에 대한 대상 충실도의 상한에 접근한다는 것을 발견했습니다.
우리는 이것이 Imagen의 더 큰 표현력과 더 높은 출력 품질 때문이라고 생각합니다.
또한 사용자 연구를 수행하여 Textual Inversion (Stable Diffusion)과 DreamBooth (Stable Diffusion)를 비교합니다.
대상 충실도를 위해 72명의 사용자에게 25개의 비교 질문(질문지당 3명의 사용자)의 질문지에 답하도록 요청하여 총 1800개의 답변을 받았습니다.
샘플은 큰 풀에서 랜덤하게 선택됩니다.
각 질문은 대상에 대한 실제 이미지 세트와 각 방법(랜덤 프롬프트 포함)에 의해 해당 대상에 대해 생성된 하나의 이미지를 보여줍니다.
사용자는 다음 질문에 답해야 합니다: "두 이미지 중 참조 항목의 ID(예: 항목 유형 및 세부 정보)를 가장 잘 재현하는 이미지는 무엇입니까?"이며, "Cannot Determinate/Both Equally" 옵션이 포함되어 있습니다.
마찬가지로 프롬프트 충실도를 위해 "두 이미지 중 참조 텍스트로 가장 잘 설명되는 것은 무엇입니까?"를 묻습니다.
다수결 투표를 사용하여 결과를 평균화하고 표 2에 제시합니다.
우리는 대상 충실도와 프롬프트 충실도 모두에서 DreamBooth가 압도적으로 선호됩니다.
이는 사용자 선호도 측면에서 약 0.1의 DINO 차이와 0.05의 CLIP-T 차이가 유의한 표 1의 결과를 보여줍니다.
마지막으로, 우리는 그림 4에서 질적 비교를 보여줍니다.
우리는 DreamBooth가 대상 정체성을 더 잘 보존하고 프롬프트에 더 충실하다는 것을 관찰합니다.
우리는 보충 자료에 사용자 연구의 샘플을 보여줍니다.


4.3. Ablation Studies
Prior Preservation Loss Ablation
우리는 제안된 prior preservation loss (PPL)을 포함하거나 포함하지 않고 데이터 세트에서 15개 대상에 대해 Imagen을 미세 조정합니다.
prior preservation loss는 언어 이동과 싸우고 prior preservation을 추구합니다.
prior 클래스의 임의 대상의 생성된 이미지와 특정 대상의 실제 이미지 사이의 평균 쌍별 DINO 임베딩을 계산하여 prior preservation metric (PRES)을 계산합니다.
이 메트릭이 높을수록 클래스의 랜덤 대상이 특정 대상과 더 유사하여 prior 대상의 붕괴를 나타냅니다.
우리는 표 3에 결과를 보고하고 PPL이 언어 드리프트를 실질적으로 상쇄하고 prior 클래스의 다양한 이미지를 생성하는 능력을 유지하는 데 도움이 된다는 것을 관찰합니다.
또한 동일한 프롬프트를 가진 동일한 대상의 생성된 이미지 간의 평균 LPIPS [73] 코사인 유사성을 사용하여 다양성 메트릭(DIV)을 계산합니다.
우리는 PPL로 학습된 우리의 모델이 (약간 감소된 대상 충실도로) 더 높은 다양성을 달성한다는 것을 관찰합니다.
이는 PPL로 학습된 우리의 모델이 참조 이미지의 환경에 덜 적합하고 더 다양한 포즈와 관절로 dog를 생성할 수 있는 그림 6에서도 질적으로 관찰할 수 있습니다.


Class-Prior Ablation
클래스 명사, 랜덤으로 샘플링된 잘못된 클래스 명사 및 올바른 클래스 명사가 없는 데이터 세트 대상(5개의 피험자)의 하위 집합에서 Imagen을 미세 조정합니다.
우리의 대상에 맞는 클래스 명사를 사용하여, 우리는 그 대상에 충실하게 맞을 수 있고, 그 prior의 클래스를 활용할 수 있으며, 다양한 맥락에서 우리의 대상을 생성할 수 있습니다.
잘못된 클래스 명사(예: “can” for a backpack)가 사용되면, 우리는 우리의 대상과 prior의 클래스 사이에서 논쟁에 부딪힙니다 - 때때로 원통형 백팩을 얻거나 그렇지 않으면 모양이 잘못된 대상을 얻습니다.
클래스 명사 없이 학습하면 모델이 클래스를 prior에 활용하지 못하고 대상을 학습하고 수렴하는 데 어려움이 있으며 잘못된 샘플을 생성할 수 있습니다.
대상 충실도 결과는 표 4에 나와 있으며 제안된 접근 방식에 대해 훨씬 더 높은 대상 충실도를 가지고 있습니다.

4.4. Applications
Recontextualization
설명 프롬프트("a [V] [class noun] [context description]")를 사용하여 특정 대상에 대한 새로운 이미지를 생성할 수 있습니다(그림 7).
중요한 것은 이전에 볼 수 없었던 장면 구조와 장면에서 대상의 현실적인 통합(예: 접촉, 그림자, 반사)을 통해 새로운 포즈와 관절로 대상을 생성할 수 있다는 것입니다.

Art Renditions
"a painting of a [V] [class noun] in the style of [famous painter]" 또는 "a statue of a [V] [class noun] in the style of [famous sculptor]"이라는 프롬프트가 주어지면 우리는 대상의 예술적 표현을 생성할 수 있습니다.
소스 구조가 보존되고 스타일만 전송되는 style transfer과 달리, 우리는 대상 정체성을 유지하면서 예술 스타일에 따라 의미 있고 새로운 변형을 생성할 수 있습니다.
예를 들어, "Michelangelo"의 그림 8에 표시된 것처럼, 우리는 입력 이미지에서 볼 수 없는 새로운 포즈를 생성했습니다.

Novel View Synthesis
우리는 그 대상을 새로운 관점으로 해석할 수 있습니다.
그림 8에서 우리는 새로운 관점에서 입력 고양이의 새로운 이미지(일관된 복잡한 모피 패턴)를 생성합니다.
우리는 모델이 이 특정 고양이를 뒤, 아래 또는 위에서 보지 못했다는 것을 강조합니다.
그러나 대상의 4개의 정면 이미지만 주어진다면 이러한 새로운 관점을 생성하기 전에 클래스에서 지식을 추론할 수 있습니다.
Property Modification
대상 속성을 수정할 수 있습니다.
예를 들어, 우리는 그림 8의 맨 아래 줄에서 특정 차우차우 개와 다른 동물 종 사이의 크로스를 보여줍니다.
다음과 같은 구조의 문장으로 모델에 프롬프트를 표시합니다: "a cross of a [V] dog and a [target species]".
특히, 우리는 이 예에서 종이 바뀔 때에도 개의 정체성이 잘 보존된다는 것을 볼 수 있습니다 - 개의 얼굴은 잘 보존되고 대상 종과 혼합되는 특정한 독특한 특징을 가지고 있습니다.
재료 수정과 같은 다른 특성 수정이 가능합니다(예: 그림 7의 “a transparent [V] teapot").
일부는 다른 것보다 더 어렵고 기본 생성 모델의 prior 모델에 의존합니다.
4.5. Limitations
우리는 그림 9에서 우리 방법의 몇 가지 실패 모델을 설명합니다.
첫 번째는 프롬프트된 컨텍스트를 정확하게 생성할 수 없는 것과 관련이 있습니다.
가능한 이유는 이러한 맥락에 대한 prior의 취약성 또는 학습 세트에서 동시에 발생할 가능성이 낮아 대상과 지정된 개념을 함께 생성하는 데 어려움이 있습니다.
두 번째는 배경-외관 얽힘으로, 그림 9에서 백팩의 색상 변화와 함께 예시한 것처럼 자극된 배경으로 인해 대상의 모양이 변경됩니다.
셋째, 우리는 또한 프롬프트가 대상이 보였던 원래 설정과 유사할 때 발생하는 실제 이미지에 과적합하는 것을 관찰합니다.

다른 제한 사항은 일부 대상이 다른 대상(예: 개와 고양이)보다 배우기 쉽다는 것입니다.
더 희귀한 대상의 경우 모형이 더 많은 대상 변동을 지원할 수 없는 경우가 있습니다.
마지막으로, 대상의 충실도에도 변동성이 있으며 prior 모델의 강도와 의미 수정의 복잡성에 따라 일부 생성된 이미지에 환각 상태의 대상 피쳐가 포함될 수 있습니다.
5. Conclusions
우리는 대상의 몇 가지 이미지와 텍스트 프롬프트의 안내를 사용하여 대상의 새로운 버전을 합성하는 접근법을 제시했습니다.
우리의 핵심 아이디어는 대상을 고유 식별자로 임베딩하여 text-to-image diffusion 모델의 출력 도메인에 주어진 대상 인스턴스를 포함시키는 것입니다.
놀랍게도 - 이 미세 조정 프로세스는 3-5개의 대상 이미지만 주어지면 작동할 수 있으므로 특히 기술에 액세스할 수 있습니다.
우리는 생성된 사진 사실적 장면에서 동물과 물체로 다양한 응용 프로그램을 시연했으며, 대부분의 경우 실제 이미지와 구별할 수 없습니다.
Background
Text-to-Image Diffusion Models
Diffusion 모델은 가우시안 분포에서 샘플링된 변수의 점진적 디노이징을 통해 데이터 분포를 학습하도록 학습된 확률론적 생성 모델입니다.
구체적으로, 이것은 고정 길이 마르코프 forward 프로세스의 reverse 프로세스를 학습하는 것에 해당합니다.
간단히 말해, 조건적 diffusion 모델 ^x_θ는 squared error loss를 사용하여 다음과 같이 가변 노이즈 이미지 z_t := α_t x + σ_t ε를 디노이즈하기 위해 학습됩니다:

, 여기서 x는 ground truth 이미지, c는 조건화 벡터(예: 텍스트 프롬프트에서 얻은 값), ε ~ N(0, I)은 노이즈 항이며 α_t, σ_t, w_t는 노이즈 스케줄과 샘플 품질을 제어하는 항이며 diffusion 프로세스 시간 t ~ U([0, 1])의 함수입니다.
추론 시, 결정론적 DDIM [64] 또는 확률적 조상 샘플러 [25]를 사용하여 z_t_1 ~ N(0, I)을 반복적으로 디노이즈하여 diffusion 모델을 샘플링합니다.
중간점 z_t_1, ..., z_t_T, 여기서 1 = t_1 > ... > t_T = 0, 노이즈 수준이 감소하여 생성됩니다.
이러한 점 ^x_0^t := ^x_θ(z_t, c)는 x-predictions의 함수입니다.
최근의 SOTA text-to-image diffusion 모델은 텍스트에서 고해상도 이미지를 생성하기 위해 계단식 diffusion 모델을 사용합니다 [54, 61].
구체적으로 [61]은 64x64 출력 해상도를 가진 기본 text-to-image 모델과 64x64 → 256x256 및 256x256 → 1024x1024 텍스트 조건부 초해상도(SR) 모델 두 개를 사용합니다.
Ramesh et al. [54]은 무조건적인 SR 모델과 유사한 구성을 사용합니다.
[61]의 고품질 샘플 생성의 핵심 구성요소는 두 개의 SR 모듈에 대한 노이즈 조절 증강[26]을 사용하는 것입니다.
이는 특정 강도의 노이즈를 사용하여 중간 이미지를 손상시킨 다음 SR 모델을 손상 수준으로 조정하는 것으로 구성됩니다.
Saharia et al. [61]은 확대의 형태로 가우시안 노이즈를 선택합니다.
Stable Diffusion [59]과 같은 다른 최신 text-to-image diffusion 모델은 단일 diffusion 모델을 사용하여 고해상도 이미지를 생성합니다.
특히, forward 및 backward diffusion 프로세스는 저차원 잠재 공간에서 발생하며 인코더-디코더 아키텍처는 이미지를 잠재 코드로 변환하기 위해 큰 이미지 데이터 세트에서 학습됩니다.
추론 시간에 랜덤 노이즈 잠재 코드는 reverse diffusion 프로세스를 거치며 사전 학습된 디코더를 사용하여 최종 이미지를 생성합니다.
우리의 방법은 U-Net(그리고 아마도 텍스트 인코더)이 학습되고 디코더가 고정되는 이 시나리오에 자연스럽게 적용될 수 있습니다.
Vocabulary Encoding
text-to-image diffusion 모델에서 텍스트 조건화의 세부 사항은 시각적 품질과 의미론적 충실도에 매우 중요합니다.
Ramesh et al. [54]은 학습된 prior를 사용하여 이미지 임베딩으로 변환되는 CLIP 텍스트 임베딩을 사용하는 반면, Saharia et al. [61]은 사전 학습된 T5-XXL 언어 모델을 사용합니다[53].
우리의 작업에서는 후자를 사용합니다.
T5-XXL과 같은 언어 모델은 토큰화된 텍스트 프롬프트의 임베딩을 생성하며, 어휘 인코딩은 프롬프트 임베딩을 위한 중요한 전처리 단계입니다.
텍스트 프롬프트 P를 조건부 임베딩 c로 변환하기 위해 먼저 학습된 어휘를 사용하여 토큰화합니다.
[61]에 이어, 우리는 SentencePiece 토큰화기[32]를 사용합니다.
토큰화기 f를 사용하여 프롬프트 P를 토큰화한 후 고정 길이 벡터 f(P)를 얻습니다.
언어 모델 Γ는 임베딩 c:= Γ(f(P))를 생성하기 위해 이 토큰 식별자 벡터에 조건화됩니다.
마지막으로, text-to-image diffusion 모델은 c에 직접적으로 조건화됩니다.
'Diffusion' 카테고리의 다른 글
| On Distillation of Guided Diffusion Models (0) | 2023.07.20 |
|---|---|
| GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models (0) | 2023.05.30 |
| Deep Unsupervised Learning using Nonequilibrium Thermodynamics (0) | 2023.03.16 |
| Generative Modeling by Estimating Gradients of the Data Distribution (0) | 2023.01.09 |
| Diffusion Models Beat GANs on Image Synthesis (0) | 2023.01.06 |