2023. 1. 6. 13:12ㆍDiffusion
Diffusion Models Beat GANs on Image Synthesis
Prafulla Dhariwal, Alex Nichol
Abstract
우리는 diffusion 모델이 현재의 SOTA 생성 모델보다 우수한 이미지 샘플 품질을 달성할 수 있음을 보여준다.
우리는 일련의 ablations를 통해 더 나은 아키텍처를 찾아 무조건적 이미지 합성에서 이를 달성한다.
조건적 이미지 합성을 위해 classifier guidance를 통해 샘플 품질을 추가로 개선한다: classifier의 그레디언트를 사용하여 충실도를 위해 다양성을 교환하는 간단하고 계산 효율적인 방법.
우리는 ImageNet 128x128에서 2.97, ImageNet 256x256에서 4.59, ImageNet 512x512에서 7.72의 FID를 달성하고, 분포에 대한 더 나은 커버리지를 유지하면서 샘플당 25개의 forward 패스로도 BigGAN-deep를 일치시킨다.
마지막으로 classifier guidance가 업샘플링 diffusion 모델과 잘 결합되어 FID가 ImageNet 256x256에서 3.94로, ImageNet 512x512에서 3.85로 더욱 향상된다는 것을 발견했다.

1 Introduction
지난 몇 년 동안 생성 모델은 인간과 유사한 자연 언어[6], 고품질 합성 이미지[5, 28, 51] 및 매우 다양한 인간 음성 및 음악[64, 13]을 생성할 수 있는 능력을 얻었다.
이러한 모델은 텍스트 프롬프트에서 이미지를 생성하거나 [78, 56] 유용한 피쳐 표현을 학습하는 등 다양한 방법으로 사용할 수 있습니다[18, 10].
이러한 모델들은 이미 사실적인 이미지와 소리를 생산할 수 있지만, 현재의 SOTA를 넘어서는 개선의 여지가 여전히 많으며, 더 나은 생성 모델들은 그래픽 디자인, 게임, 음악 제작, 그리고 수많은 다른 분야에 광범위한 영향을 미칠 수 있다.
GANs [19]은 현재 FID [23], Inception Score [54] 및 Precision [32]과 같은 샘플 품질 메트릭으로 측정된 대부분의 이미지 생성 작업 [5, 68, 28]에서 SOTA 기술을 보유하고 있다.
그러나 이러한 메트릭 중 일부는 다양성을 완전히 포착하지 못하며, GAN은 SOTA likelihood-기반 모델보다 덜 다양성을 포착하는 것으로 나타났다 [51, 43, 42].
또한, GAN은 종종 학습하기가 어려우며, 신중하게 선택된 하이퍼 파라미터와 정규화기 없이는 붕괴된다[5, 41, 4].
GAN은 SOTA 기술을 보유하고 있지만, 그 단점으로 인해 새로운 도메인에 확장 및 적용이 어렵다.
그 결과, likelihood-기반 모델을 사용하여 GAN-like 샘플 품질을 달성하기 위해 많은 작업이 수행되었다[51, 25, 42, 9].
이러한 모델은 GAN보다 더 다양성을 포착하고 일반적으로 확장 및 학습이 쉽지만 시각적 샘플 품질 측면에서는 여전히 부족하다.
또한 VAE를 제외하고, 이러한 모델의 샘플링은 벽시계 시간 측면에서 GAN보다 느리다.
Diffusion 모델은 최근 고품질 이미지[56, 59, 25]를 생성하는 동시에 분포 커버리지, 고정 학습 objective 및 손쉬운 확장성과 같은 바람직한 특성을 제공하는 것으로 나타난 likelihood-기반 모델의 한 종류이다.
이러한 모델은 신호에서 노이즈를 점진적으로 제거하여 샘플을 생성하며, 학습 objective는 가중 variational lower-bound [25]로 표현할 수 있다.
이 클래스의 모델은 이미 CIFAR-10 [31]에서 SOTA [60]를 보유하고 있지만 LSUN 및 ImageNet과 같은 어려운 생성 데이터 세트에서 GAN에 비해 여전히 뒤처져 있다.
Nichol과 Dhariwal [43]은 이러한 모델이 컴퓨팅 증가로 안정적으로 개선되고 업샘플링 스택을 사용하여 어려운 ImageNet 256x256 데이터 세트에서도 고품질 샘플을 생성할 수 있음을 발견했습니다.
그러나 이 모델의 FID는 여전히 이 데이터 세트의 현재 SOTA인 BigGAN-deep [5]과 경쟁하지 않습니다.
우리는 diffusion 모델과 GAN 사이의 격차가 적어도 두 가지 요인에서 비롯된다고 가정합니다:
첫째, 최근 GAN 문헌에 사용된 모델 아키텍처가 크게 탐구되고 정제되었다는 점;
둘째, GAN이 충실도를 위해 다양성을 절충하여 고품질 샘플을 생산하지만 전체 분포를 다루지 못한다는 점이다.
우리는 먼저 모델 아키텍처를 개선한 다음 충실도를 위해 다양성을 교환하는 체계를 고안함으로써 diffusion 모델에 이러한 이점을 가져오는 것을 목표로 한다.
이러한 개선을 통해 우리는 여러 다른 메트릭 및 데이터 세트에서 GAN을 능가하는 새로운 SOTA를 달성합니다.
논문의 나머지 부분은 다음과 같이 구성되어 있다.
섹션 2에서는 Ho et al. [25]에 기반한 diffusion 모델의 간략한 배경과 Nichol 및 Dhariwal [43] 및 Song et al. [57]의 개선 사항을 설명하고 평가 설정을 설명합니다.
섹션 3에서는 FID에 상당한 향상을 주는 간단한 아키텍처 개선 사항을 소개한다.
섹션 4에서는 샘플링 중에 diffusion 모델을 guide하기 위해 classifier의 그레디언트를 사용하는 방법을 설명한다.
우리는 classifier 그레디언트의 척도인 단일 하이퍼 파라미터를 충실도를 위해 다양성을 트레이드오프하도록 조정할 수 있다는 것을 발견했고, 적대적인 예를 얻지 않고도 이 그레디언트 스케일 팩터를 몇 배 늘릴 수 있습니다 [61].
마지막으로, 섹션 5에서 우리는 개선된 아키텍처를 가진 모델이 무조건적 이미지 합성 작업에서 SOTA를 달성하고 classifier guidance를 통해 조건적 이미지 합성에서 SOTA를 달성한다는 것을 보여준다.
classifier guidance를 사용할 때, 우리는 BigGAN과 비슷한 FID를 유지하면서 25개의 forward 패스로 샘플링할 수 있다는 것을 발견했습니다.
또한 개선된 모델을 업샘플링 스택과 비교하여 두 가지 접근 방식이 보완적인 개선을 제공하고 이를 결합하면 ImageNet 256x256 및 512x512에서 최상의 결과를 얻을 수 있음을 발견했습니다.
2 Background
이 섹션에서는 diffusion 모델에 대한 간략한 개요를 제공합니다.
보다 자세한 수학적 설명은 부록 B를 참조하십시오.
높은 레벨에서 diffusion 모델은 점진적인 노이즈 프로세스를 reversing시켜 분포에서 샘플을 추출한다.
특히 샘플링은 노이즈 x_T로 시작하여 최종 샘플 x_0에 도달할 때까지 점차 노이즈가 적은 샘플 x_(T-1), x_(T-2), ...을 생성합니다.
각 타임스텝 t는 특정 노이즈 레벨에 해당하며 x_t는 타임스텝 t에 의해 신호 대 노이즈 비율이 결정되는 일부 노이즈 ε과 신호 x_0의 혼합물로 생각할 수 있습니다.
본 논문의 나머지 부분에 대해, 우리는 노이즈 ε이 자연 이미지에 잘 작동하고 다양한 파생을 단순화하는 대각 가우시안 분포에서 추출되었다고 가정합니다.
diffusion 모델은 x_t에서 조금 더 "denoised" x_(t-1)을 생성하는 방법을 학습한다.
Ho et al. [25]은 노이즈가 많은 샘플 x_t의 노이즈 성분을 예측하는 함수 ε_θ(x_t, t)로 이 모델을 매개 변수화한다.
이 모델을 학습하기 위해 미니 배치의 각 샘플은 데이터 샘플 x_0, 시간 단계 t 및 노이즈 ε를 랜덤으로 그려서 생성되며, 이를 함께 사용하면 노이즈가 있는 샘플 x_t가 생성됩니다(식 17).
학습 objective는 ||ε_θ(x_t, t) - ε||^2, 즉 실제 노이즈와 예측 노이즈 사이의 단순 평균 오차 loss다(식 26).
노이즈 예측 변수 ε_θ(x_t, t)에서 샘플을 추출하는 방법은 즉시 명확하지 않습니다.
diffusion 샘플링은 x_T에서 시작하여 x_t에서 x_(t-1)을 반복적으로 예측함으로써 진행된다는 것을 기억하십시오.
Ho et al. [25]은 합리적인 가정 하에서, 우리가 주어진 x_(t-1)의 분포 p_θ(x_(t-1)|x_t)를 대각 가우시안 N(x_(t-1); μ_θ(x_t, t), Σ_θ(x_t, t))로 모델링할 수 있음을 보여준다, 여기서 평균 μ_θ(x_t, t)는 ε_θ(x_t, t)의 함수로 계산될 수 있다(식 27).
이 가우시안 분포의 분산 ∑_θ(x_t, t)는 알려진 상수 [25]에 고정되거나 별도의 신경망 헤드 [43]로 학습될 수 있으며, 두 접근 방식 모두 총 diffusion 단계 T가 충분히 클 때 고품질 샘플을 산출합니다.
Ho et al. [25]은 denoising diffusion 모델을 VAE로 해석하여 도출할 수 있는 실제 variational lower bound L_vlb보다 단순 평균 제곱 오차 objective L_simple이 실제로 더 잘 작동한다는 것을 관찰한다.
그들은 또한 이 objective로 학습하고 해당 샘플링 절차를 사용하는 것은 Langevin dynamics를 사용하여 여러 노이즈 레벨로 학습된 디노이징 모델에서 샘플을 추출하여 고품질 이미지 샘플을 생성하는 Song and Ermon [58]의 denoising score matching 모델과 동등하다는 점에 주목한다.
우리는 종종 두 종류의 모델을 모두 지칭하기 위해 "diffusion models"을 속기로 사용한다.
2.1 Improvements
Song and Ermon [58]과 Ho et al. [25]의 획기적인 연구에 따라, 최근 여러 논문이 diffusion 모델의 개선을 제안했다.
여기서 우리는 모델에 사용되는 이러한 개선 사항 중 몇 가지를 설명합니다.
Nichol and Dariwal[43]은 분산 Σ_θ(x_t, t)를 Ho et al. [25]에서 수행한 것처럼 상수로 고정하는 것이 더 적은 diffusion 단계로 샘플링하는 데 차선적이라는 것을 발견하고 출력 v가

로 보간되는 신경망으로 매개 변수화할 것을 제안한다.
여기서 β_t와 ~β_t(식 19)는 reverse 프로세스 분산에 대한 상한 및 하한에 해당하는 Ho et al. [25]의 분산입니다.
또한 Nichol and Dariwal[43]은 가중 합계 L_simple + λ L_vlb를 사용하여 ε_θ(x_t, t)와 Σ_θ(x_t, t)를 모두 학습하기 위한 하이브리드 objective를 제안한다.
하이브리드 objective로 reverse 프로세스 분산을 학습하면 샘플 품질의 큰 하락 없이 더 적은 단계로 샘플링할 수 있다.
우리는 이 objective와 매개 변수화를 채택하고 실험 전반에 걸쳐 사용한다.
Song et al. [57]은 DDPM과 forward marginals가 동일하지만 reverse 노이즈의 분산을 변경하여 다른 reverse 샘플러를 생성할 수 있는 대체 non-Markovian 노이즈 프로세스를 공식화하는 DDIM을 제안한다.
이 노이즈를 0으로 설정하면 모든 모델 ε_θ(x_t, t)을 잠재에서 이미지로 결정론적 매핑으로 전환할 수 있으며, 이를 통해 더 적은 단계로 샘플을 추출할 수 있는 대안적인 방법을 찾을 수 있습니다.
Nichol and Dhariwal [43]이 이 체제에서 유익하다고 판단했기 때문에 50개 미만의 샘플링 단계를 사용할 때 이 샘플링 접근법을 채택한다.
2.2 Sample Quality Metrics
모델 간 샘플 품질을 비교하기 위해 다음 메트릭을 사용하여 정량적 평가를 수행한다.
이러한 메트릭은 실제로 자주 사용되고 인간의 판단과 잘 일치하지만 완벽한 프록시는 아니며 샘플 품질 평가를 위한 더 나은 메트릭을 찾는 것은 여전히 미해결 문제이다.
Inception Score (IS)는 Salimans et al. [54]에 의해 제안되었으며 모델이 전체 ImageNet 클래스 분포를 얼마나 잘 캡처하는지 측정하는 동시에 단일 클래스의 설득력 있는 예를 제공하는 개별 샘플을 생성합니다.
이 메트릭의 한 가지 단점은 전체 분포를 포함하거나 클래스 내의 다양성을 포착하는 것에 보상을 주지 않는다는 것이며, 전체 데이터 세트의 작은 부분 집합을 기억하는 모델은 여전히 높은 IS를 가질 것입니다 [3].
IS보다 다양성을 더 잘 포착하기 위해 Fréchet Inception Distance (FID)는 Inception Score보다 인간의 판단과 더 일치한다고 주장한 Heusel et al. [23]에 의해 제안되었습니다.
FID는 Inception-V3 [62] 잠재 공간에서 두 이미지 분포 사이의 거리에 대한 대칭 측정을 제공합니다.
최근, sFID는 Nash et al. [42]에 의해 표준 풀링된 피쳐가 아닌 공간 피쳐를 사용하는 FID 버전으로 제안되었습니다.
그들은 이 메트릭이 공간 관계를 더 잘 포착하여 일관된 높은 수준의 구조로 이미지 분포를 보상한다는 것을 발견했습니다.
마지막으로, Kynkäänniemi et al. [32]는 데이터 매니폴드에 속하는 모델 샘플의 분율(precision)로서 샘플 충실도를 별도로 측정하고, 샘플 매니폴드에 속하는 데이터 샘플의 분율(recall)로서 다양성을 측정하기 위해 개선된 Precision 및 Recall 메트릭을 제안했습니다.
우리는 FID[29]가 다양성과 충실도를 모두 포착하고 SOTA 생성 모델[27, 28, 5, 25]에 대한 사실상의 표준 메트릭이었기 때문에 전반적인 샘플 품질 비교를 위한 기본 메트릭으로 사용한다.
Precision 또는 IS를 사용하여 충실도를 측정하고 Recall을 사용하여 다양성 또는 분포 범위를 측정합니다.
다른 방법과 비교할 때, 우리는 가능할 때마다 공개 샘플이나 모델을 사용하여 이러한 메트릭을 다시 계산한다.
이는 두 가지 이유 때문이다:
첫째, 일부 논문[27, 28, 25]은 쉽게 사용할 수 없는 학습 세트의 임의 하위 집합과 비교하고;
둘째, 미묘한 구현 차이는 결과 FID 값[45]에 영향을 미칠 수 있다.
일관된 비교를 위해 전체 학습 세트를 참조 배치[23, 5]로 사용하고 동일한 코드베이스를 사용하여 모든 모델에 대한 메트릭을 평가한다.
3 Architecture Improvements
이 섹션에서 우리는 diffusion 모델에 최고의 샘플 품질을 제공하는 모델 아키텍처를 찾기 위해 몇 가지 아키텍처 ablation을 수행합니다.
Ho et al. [25]은 diffusion 모델을 위해 UNet 아키텍처를 도입했으며, Jolicoeur-Martineau et al. [26]은 denoising score matching에 사용된 이전 아키텍처[58, 33]보다 샘플 품질을 상당히 향상시키는 것으로 나타났다.
UNet 모델은 잔차 레이어와 다운샘플링 컨볼루션의 스택을 사용하고, 업샘플링 컨볼루션의 잔차 레이어 스택을 사용하며, 동일한 공간 크기의 레이어를 연결하는 스킵 연결을 사용한다.
또한, 그들은 단일 헤드로 16x16 해상도에서 전역 어텐션 레이어를 사용하고, 각 잔차 블록에 시간 단계 임베딩의 투영을 추가한다.
Song et al. [60]은 UNet 아키텍처에 대한 추가 변경이 CIFAR-10 [31] 및 CelebA-64 [34] 데이터 세트의 성능을 향상시켰다는 것을 발견했다.
우리는 ImageNet 128x128에서 동일한 결과를 보여주며, 아키텍처가 훨씬 크고 다양한 데이터 세트에서 더 높은 해상도로 샘플 품질에 실질적인 향상을 줄 수 있음을 발견했다.
우리는 다음과 같은 아키텍처 변화를 탐구한다:
• 모델 크기를 상대적으로 일정하게 유지하면서 depth vs. 폭을 늘립니다.
• 어텐션 헤드의 수를 늘립니다.
• 16x16에서만 어텐션을 하지 않고 32x32, 16x16 및 8x8 해상도에서 어텐션을 한다.
• 활성화 업샘플링 및 다운샘플링을 위해 [60]에 따라 BigGAN [5] 잔여 블록을 사용합니다.
• [60, 27, 28]에 이어 1/√2로 잔차 연결부의 크기를 리스케일합니다.
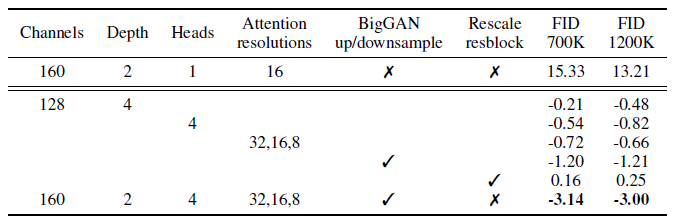
이 섹션의 모든 비교를 위해 배치 크기가 256인 ImageNet 128x128에서 모델을 학습하고 250개의 샘플링 단계를 사용하여 샘플을 추출합니다.
우리는 위의 아키텍처 변경 사항을 가진 모델을 학습하고 표 1에서 두 가지 학습 지점에서 평가된 FID에서 비교한다.
잔차 연결의 크기를 조정하는 것 외에도, 다른 모든 수정 사항은 성능을 향상시키고 긍정적인 복합 효과를 제공합니다.
우리는 그림 2에서 depth가 증가하면 성능에 도움이 되지만 학습 시간이 증가하고 더 넓은 모델과 동일한 성능에 도달하는 데 시간이 오래 걸리기 때문에 추가 실험에서 이 변경 사항을 사용하지 않기로 선택했습니다.

또한 트랜스포머 아키텍처 [66]와 더 잘 일치하는 다른 어텐션 구성을 연구합니다.
이를 위해 어텐션 헤드를 상수로 고정하거나 헤드당 채널 수를 고정하는 실험을 수행했습니다.
나머지 아키텍처에는 128개의 기본 채널, 해상도당 2개의 잔여 블록, 다중 해상도 어텐션, BigGAN 업/다운 샘플링을 사용하며 700K 반복에 대한 모델을 학습합니다.
표 2는 헤드당 더 많은 헤드 또는 더 적은 채널이 FID를 개선한다는 것을 나타내는 결과를 보여줍니다.
그림 2에서는 벽시계 시간에 64개 채널이 가장 적합하므로 헤드당 64개 채널을 기본값으로 사용합니다.
우리는 이 선택이 현대적인 트랜스포머 아키텍처와 더 잘 어울리며 최종 FID 측면에서 우리의 다른 구성과 동등하다는 점에 주목한다.

3.1 Adaptive Group Normalization
우리는 또한 adaptive instance norm [27] 및 FiLM[48]과 유사하게 group normalization 연산 [69] 후 각 잔차 블록에 시간 단계 및 클래스 임베딩을 통합하는 Adaptive Group Normalization (AdaGN)라고 하는 레이어 [43]를 실험한다.
우리는 이 레이어를 AdaGN(h, y) = y_s GroupNorm(h)+y_b로 정의하는데, 여기서 h는 첫 번째 컨볼루션에 따른 잔차 블록의 중간 활성화이며, y = [y_s, y_b]는 시간 단계 및 클래스 임베딩의 선형 투영에서 얻는다.

우리는 이미 AdaGN이 우리의 초기 diffusion 모델을 개선하는 것을 보았고, 따라서 우리의 모든 실행에 그것을 기본적으로 포함시켰다.
표 3에서, 우리는 이 선택을 명시적으로 축소하고 adaptive group normalization 레이어가 실제로 FID를 향상시켰다는 것을 발견했습니다.
두 모델 모두 해상도당 128개의 기본 채널과 2개의 잔차 블록, 헤드당 64개의 채널로 다중 해상도 어텐션, BigGAN 업/다운 샘플링을 사용하며 700K 반복 학습을 받았습니다.
이 논문의 나머지 부분에서는 이 최종적으로 개선된 모델 아키텍처를 기본값으로 사용합니다: 해상도당 2개의 잔차 블록, 헤드당 64개의 채널을 가진 다중 헤드, 32, 16 및 8개의 해상도에서의 어텐션, 업 다운 샘플링을 위한 BigGAN 잔차 블록, 잔차 블록에 타임스텝 및 클래스 임베딩을 주입하기 위한 adaptive group normalization.
4 Classifier Guidance
잘 설계된 아키텍처를 사용하는 것 외에도 조건적 이미지 합성을 위한 GAN[39, 5]은 클래스 레이블을 많이 사용한다.
이것은 종종 classifier p(y|x) [40]처럼 행동하도록 명시적으로 설계된 헤드를 가진 판별기뿐만 아니라 클래스조건적 정규화 통계[16, 11]의 형태를 취한다.
클래스 정보가 이러한 모델의 성공에 중요하다는 추가 증거로, Lucic et al. [36]은 레이블이 제한된 체제에서 작업할 때 합성 레이블을 생성하는 것이 도움이 된다는 것을 발견했다.
GAN에 대한 이러한 관찰을 고려할 때, 클래스 레이블에서 diffusion 모델을 조건화하는 다양한 방법을 탐색하는 것이 타당하다.
우리는 이미 정규화 레이어에 클래스 정보를 통합한다(섹션 3.1).
여기서, 우리는 다른 접근법을 탐구한다: diffusion 생성기를 개선하기 위해 classifier p(y|x)를 활용한다.
Sohl-Dickstein et al. [56]과 Song et al. [60]은 이를 달성하기 위한 한 가지 방법을 보여주는데, 여기서 classifier의 그래디언트를 사용하여 사전 학습된 diffusion 모델을 조건화할 수 있다.
특히 노이즈가 많은 이미지 x_t에서 classifier p_ɸ(y|x_t, t)를 학습한 다음 그레디언트 ∇_(x_t) log p(y|x_t, t)를 사용하여 임의 클래스 레이블 y로 diffusion 샘플링 프로세스를 guide할 수 있다.
이 섹션에서는 먼저 classifier를 사용하여 조건적 샘플링 프로세스를 도출하는 두 가지 방법을 검토합니다.
그런 다음 샘플 품질을 향상시키기 위해 실제로 이러한 classifier를 사용하는 방법을 설명합니다.
우리는 간결함을 위해 p_ɸ(y|x_t, t) = p_ɸ(y|x_t)와 ε_θ(x_t, t) = ε_θ(x_t)라는 표기법을 선택하며, 각 시간 단계 t에 대해 별도의 함수를 참조하고 학습 시간에 모델이 입력 t에서 조정되어야 한다는 점에 주목합니다.
4.1 Conditional Reverse Noising Process
우리는 무조건적인 reverse 노이즈 프로세스 p_θ(x_t|x_(t+1))를 가진 diffusion 모델로 시작합니다.
이를 y 레이블에 조건화하기 위해
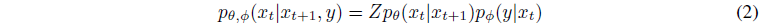
에 따라 각 transition을 샘플링하면 충분합니다, 여기서 Z는 정규화 상수입니다(부록 H의 증명).
일반적으로 이 분포에서 정확하게 샘플을 추출하는 것은 어렵지만, Sohl-Dickstein et al. [56]은 섭동된 가우시안 분포로 근사할 수 있음을 보여줍니다.
여기서는 이 파생을 검토합니다.
우리의 diffusion 모델은 가우시안 분포를 사용하여 시간 단계 x_(t+1)에서 이전 시간 단계 x_t를 예측한다는 것을 기억하십시오:

우리는 log_ɸ p(y|x_t)가 ∑^-1에 비해 낮은 곡률을 가지고 있다고 가정할 수 있습니다.
이 가정은 |∑| → 0인 무한 diffusion 단계의 한계에서 합리적입니다.
이 경우 x_t = μ 주변의 테일러 확장을

로 사용하여 log p_ɸ(y|x_t)를 근사화할 수 있습니다.
여기서 g = ∇_x_t log p_ɸ(y|x_t)|_(x_t=μ)와 C_1은 상수입니다.
이 값은

입니다.
상수 항 C_4는 식 2의 정규화 계수 Z에 해당하므로 안전하게 무시할 수 있습니다.
따라서 조건적 transition 연산자는 무조건적 transition 연산자와 유사하지만 평균이 Σ_g만큼 이동된 가우시안에 의해 근사될 수 있다는 것을 발견했습니다.
알고리즘 1은 해당 샘플링 알고리즘을 요약합니다.
섹션 4.3에서 자세히 설명하는 그레디언트에 대한 선택적 스케일 팩터 s를 포함합니다.

4.2 Conditional Sampling for DDIM
조건적 샘플링에 대한 위의 도출은 확률적 diffusion 샘플링 프로세스에만 유효하며 DDIM[57]과 같은 결정론적 샘플링 방법에는 적용할 수 없습니다.
이를 위해 diffusion 모델과 score matching 간의 연결을 활용하는 Song et al. [60]에서 채택된 score 기반 조건화 트릭을 사용합니다 [59].
특히, 샘플에 추가된 노이즈를 예측하는 모델 ε_θ(x_t)가 있다면, 이는 score 함수를 도출하는 데 사용될 수 있습니다:

이제 이것을 p(x_t)p(y|x_t)에 대한 score 함수로 대체할 수 있습니다:

마지막으로, 우리는 공동 분포의 score에 해당하는 새로운 엡실론 예측 ^ε(x_t)를 정의할 수 있습니다:

그런 다음 일반 DDIM에 사용된 것과 정확히 동일한 샘플링 절차를 사용할 수 있지만 ε_θ(x_t) 대신 수정된 노이즈 예측 ^ε_θ(x_t)를 사용할 수 있습니다.
알고리즘 2는 해당 샘플링 알고리즘을 요약합니다.

4.3 Scaling Classifier Gradients
대규모 생성 작업에 classifier guidance를 적용하기 위해 ImageNet에서 분류 모델을 학습한다.
우리의 classifier 아키텍처는 최종 출력을 생성하기 위해 8x8 레이어에 어텐션 풀 [49]이 있는 UNet 모델의 다운샘플링 트렁크일 뿐이다.
우리는 이러한 classifier를 해당 diffusion 모델과 동일한 노이즈 분포에 대해 학습시키고, 과적합을 줄이기 위해 랜덤 크롭을 추가한다.
학습 후, 우리는 알고리즘 1에서 설명한 바와 같이 식 10을 사용하여 diffusion 모델의 샘플링 과정에 classifier를 통합합니다.
무조건적 ImageNet 모델을 사용한 초기 실험에서, 우리는 classifier 그레디언트를 1보다 큰 상수 인자로 스케일링할 필요가 있다는 것을 발견했다.
1의 척도를 사용할 때, 우리는 classifier가 최종 샘플에 대해 원하는 클래스에 합리적인 확률(약 50%)을 할당하는 것을 관찰했지만, 이러한 샘플은 육안 검사에서 의도된 클래스와 일치하지 않았다.
classifier 그레디언트를 확장하면 이 문제가 해결되었고 classifier의 클래스 확률은 거의 100%로 증가했다.
그림 3는 이러한 효과의 예를 보여줍니다.

classifier 그레디언트 스케일링의 효과를 이해하려면 s·∇_x log p(y|x) = ∇_x log 1/Z p(y|x)^s, 여기서 Z는 임의의 상수이다.
결과적으로, 조건화 과정은 여전히 이론적으로 p(y|x)^s에 비례하는 재-정규화된 classifier 분포에 기초한다.
s > 1일 때, 더 큰 값이 지수에 의해 증폭되기 때문에 이 분포는 p(y|x)보다 더 샤프해진다.
다시 말해, 더 큰 그레디언트 스케일을 사용하는 것은 classifier의 모드에 더 초점을 맞추는데, 이는 잠재적으로 더 높은 품질(하지만 덜 다양한) 샘플을 생산하는 데 바람직하다.

위의 유도에서, 우리는 기본 diffusion 모델이 무조건적이고, p(x)를 모델링한다고 가정했다.
또한 조건적 diffusion 모델 p(x|y)을 학습하고 classifier guidance를 정확히 동일한 방법으로 사용할 수 있다.
표 4는 classifier guidance를 통해 무조건적 모델과 조건적 모델의 샘플 품질을 크게 향상시킬 수 있음을 보여준다.
우리는 클래스 레이블로 직접 학습하는 것이 여전히 도움이 되긴 하지만 충분히 높은 규모로 안내된 무조건적 모델이 unguided 조건적 모델의 FID에 상당히 근접할 수 있다는 것을 알 수 있다.
조건적 모델을 guiding하면 FID가 더욱 향상된다.

표 4는 또한 classifier guidance가 recall 비용으로 precision를 향상시켜 표본 충실도 vs. 다양성의 균형을 초래한다는 것을 보여준다.
우리는 이 절충안이 그림 4의 그래디언트 척도에 따라 어떻게 변하는지 명시적으로 평가한다.
우리는 그레디언트를 1.0 이상으로 부드럽게 조정하면 더 높은 precision과 IS(충실도 측정)를 위해 recall (다양성 측정)이 상쇄된다는 것을 알 수 있다.
FID와 sFID는 다양성과 충실도 모두에 의존하기 때문에, 그들의 최고의 값은 중간 지점에서 얻어진다.
우리는 또한 우리의 guidance를 그림 5의 BigGAN의 절단 트릭과 비교한다.
우리는 FID를 Inception Score와 교환할 때 classifier guidance가 BigGAN-deep보다 엄격하게 낫다는 것을 발견했다.
덜 명확한 컷은 precision/recall 트레이드오프이며, 이는 classifier guidance가 특정 precision 임계값까지만 더 나은 선택이며, 그 이후에는 더 나은 precision을 달성할 수 없다는 것을 보여준다.

5 Results
무조건적인 이미지 생성에 대한 개선된 모델 아키텍처를 평가하기 위해, 우리는 세 가지 LSUN[71] 클래스에 대해 별도의 diffusion 모델을 학습합니다: bedroom, horse, and cat.
classifier guidabce를 평가하기 위해 128x128, 256x256 및 512x512 해상도의 ImageNet [52] 데이터 세트에서 조건적 diffusion 모델을 학습합니다.

5.1 State-of-the-art Image Synthesis
표 5는 우리의 결과를 요약합니다.
우리의 diffusion 모델은 각 작업에서 최고의 FID를 얻을 수 있고, 한 작업을 제외한 모든 작업에서 최고의 sFID를 얻을 수 있습니다.
향상된 아키텍처를 통해 LSUN 및 ImageNet 64x64에서 이미 SOTA 이미지 생성을 수행했습니다.
고해상도 ImageNet의 경우 classifier guidance를 통해 모델이 최고의 GAN을 크게 능가할 수 있음을 관찰했습니다.
이러한 모델은 recall에 의해 측정된 분포의 더 높은 커버리지를 유지하면서 GAN과 유사한 지각 품질을 얻으며, 25개의 diffusion 단계만 사용하여 그렇게 할 수도 있습니다.

그림 6은 최고의 BigGAN-deep 모델의 랜덤 샘플과 최고의 diffusion 모델을 비교합니다.
샘플이 유사한 지각 품질을 가지고 있지만, diffusion 모델은 확대된 타조 머리, 단일 플라밍고, 치즈 버거의 다른 방향, 그리고 그것을 잡고 있는 사람이 없는 틴카 물고기와 같은 GAN보다 더 많은 모드를 포함합니다.
우리는 또한 부록 C의 Inception-V3 피쳐 공간에서 가장 가까운 이웃에 대해 생성된 샘플을 확인하고 부록 K-M에 추가 샘플을 보여줍니다.
5.2 Comparison to Upsampling
또한 2단계 업샘플링 스택을 사용하는 것과 guidance를 비교합니다.
Nichol and Dhariwal [43]과 Saharia et al. [53]은 저해상도 diffusion 모델과 해당 업샘플링 diffusion 모델을 결합하여 2단계 diffusion 모델을 학습합니다.
이 접근 방식에서 업샘플링 모델은 학습 세트의 이미지와 간단한 보간(예: 이중선형)을 사용하여 채널별로 모델 입력에 연결된 저해상도 이미지의 조건을 업샘플링하도록 학습됩니다.
샘플을 추출하는 동안 저해상도 모델이 샘플을 생성한 다음 업샘플링 모델이 이 샘플에 따라 조정됩니다.
이는 ImageNet 256x256의 FID를 크게 향상시키지만, 표 5에서 볼 수 있듯이 BigGAN-deep [43, 53]과 같은 SOTA 모델과 같은 성능에는 미치지 못합니다.

표 6에서 guidance와 업샘플링은 다양한 축을 따라 샘플 품질을 향상시킨다는 것을 보여줍니다.
업샘플링은 높은 recall을 유지하면서 precision을 향상시키지만 guidance는 다양성을 훨씬 더 높은 precision으로 바꿀 수 있는 노브를 제공합니다.
우리는 높은 해상도로 업샘플링하기 전에 낮은 해상도의 guidance를 사용하여 최상의 FID를 달성하며, 이러한 접근 방식이 서로를 보완한다는 것을 나타냅니다.
6 Related Work
score 기반 생성 모델은 Song과 Ermon [59]이 그레디언트를 사용하여 데이터 분포를 모델링한 다음 Langevin dynamics를 사용하여 샘플링하는 방법으로 도입했습니다[67].
Ho et al. [25]는 이 방법과 diffusion 모델 [56] 사이의 연관성을 발견했고, 이 연결을 활용하여 우수한 샘플 품질을 달성했습니다.
이 획기적인 작업이 끝난 후, 많은 연구들이 더 유망한 결과를 뒤따랐습니다; Kong et al. [30]과 Chen et al. [8]은 diffusion 모델이 오디오에 잘 작동한다는 것을 입증했습니다; Jolicoeur-Martineau et al. [26]은 GAN과 같은 설정이 이러한 모델의 샘플을 개선할 수 있다는 것을 발견했습니다; Song et al. [60]은 확률적 미분 방정식의 기법을 활용하여 score 기반 모델에서 얻은 샘플 품질을 개선하는 방법을 탐구했습니다; Song et al. [57]과 Nichol and Dhariwal [43]은 샘플링 속도를 개선하기 위한 방법을 제안했고; Nichol and Dhariwal [43]과 Saharia et al. [53]은 업샘플링 diffusion 모델을 사용한 어려운 ImageNet 생성 작업에서 유망한 결과를 보여주었습니다.
diffusion 모델과도 관련이 있고, Sohl-Dickstein et al. [56]의 연구에 따라, Goyal et al. [21]은 학습된 반복 생성 단계로 모델을 학습하는 기술을 설명했고, likelihood objective로 학습했을 때 좋은 이미지 샘플을 얻을 수 있다는 것을 발견했습니다.
diffusion 모델에 대한 이전 연구에서 누락된 한 가지 요소는 충실도를 위해 다양성을 절충하는 방법입니다.
다른 생성 기술은 이러한 균형을 위한 자연스러운 지렛대를 제공합니다.
Brock et al. [5]은 잠재 벡터가 잘린 정규 분포에서 샘플링되는 GAN에 대한 절단 트릭을 도입했습니다.
그들은 절단이 증가하면 자연스럽게 다양성은 감소하지만 충실도는 증가한다는 것을 발견했습니다.
더 최근에, Razavi et al.[51]은 classifier 거부 샘플링을 사용하여 autoregressive likelihood 기반 모델에서 불량 샘플을 걸러낼 것을 제안했고, 이 기술이 FID를 향상시킨다는 것을 발견했습니다.
대부분의 likelihood 기반 모형에서는 저온 샘플링[1]도 허용하므로 데이터 분포의 모드를 자연스럽게 강조할 수 있습니다(부록 G 참조).
다른 likelihood 기반 모델은 충실도가 높은 이미지 샘플을 생성하는 것으로 나타났습니다.
VQ-VAE [65] 및 VQ-VAE-2 [51]는 양자화된 잠재 코드 위에서 학습된 autoregressive 모델이므로 큰 이미지에서 이러한 모델을 학습하는 데 필요한 계산 리소스를 크게 줄입니다.
이러한 모델은 다양하고 고품질의 이미지를 생성하지만, 여전히 블러를 보완하기 위한 값비싼 거부 샘플링과 특별한 메트릭 없이 GAN에 미치지 못합니다.
DCTransformer [42]는 보다 지능적인 압축 방식에 의존하는 관련 방법입니다.
VAE는 또 다른 유망한 클래스의 likelihood 기반 모델이며, NVAE [63] 및 VDVAE [9]와 같은 최근 방법이 어려운 이미지 생성 도메인에 성공적으로 적용되었습니다.
에너지 기반 모델은 풍부한 이력을 가진 또 다른 종류의 likelihood 기반 모델입니다 [1, 10, 24].
EBM 분포에서 샘플링하는 것은 어려우며, Xie et al. [70]은 Langevin dynamics가 이러한 모델에서 일관성 있는 이미지를 샘플링하는 데 사용될 수 있음을 보여줍니다.
Du 및 Mordatch [15]는 이 접근 방식을 더욱 개선하여 고품질 이미지를 얻습니다.
최근 Gao et al. [18]은 diffusion 단계를 에너지 기반 모델에 통합하고, 그렇게 하면 이러한 모델의 이미지 샘플이 개선된다는 것을 발견했습니다.
다른 연구는 사전 학습된 classifier로 생성 모델을 제어했습니다.
예를 들어, 새롭게 등장한 작업 [17, 47, 2]는 사전 학습된 CLIP [49] 모델을 사용하여 텍스트 프롬프트에 대한 GAN 잠재 공간을 최적화하는 것을 목표로 합니다.
우리 연구와 더 유사한 Song et al. [60]은 classifier를 사용하여 diffusion 모델로 클래스 조건적 CIFAR-10 이미지를 생성합니다.
경우에 따라 classifier가 독립 실행형 생성 모델로 작동할 수 있습니다.
예를 들어, Santurkar et al. [55]는 강력한 이미지 classifier가 독립형 생성 모델로 사용될 수 있음을 보여주고, Grathwohl et al. [22]는 classifier와 에너지 기반 모델을 공동으로 학습시킵니다.
7 Limiations and Future Work
diffusion 모델이 생성 모델링에 매우 유망한 방향이라고 생각하지만, 다중 디노이징 단계(따라서 forward 패스)의 사용으로 인해 샘플링 시간에 GAN보다 여전히 느립니다.
이러한 방향으로 유망한 연구는 DDIM 샘플링 프로세스를 단일 단계 모델로 distill하는 방법을 탐구하는 Luhman과 Luhman[37]의 연구입니다.
단일 단계 모델의 샘플은 아직 GAN과 경쟁력이 없지만 이전의 단일 단계 likelihood 기반 모델보다 훨씬 좋습니다.
이 방향의 향후 작업은 이미지 품질을 희생하지 않고 diffusion 모델과 GAN 사이의 샘플링 속도 차이를 완전히 닫을 수 있습니다.
제안된 classifier guidance 기술은 현재 레이블이 지정된 데이터 세트로 제한되며, 레이블이 지정되지 않은 데이터 세트의 충실도를 위해 다양성을 절충하는 효과적인 전략을 제공하지 않았습니다.
미래에는 합성 레이블을 생성하기 위해 샘플을 클러스터링하거나 샘플이 실제 데이터 분포 또는 샘플링 분포에 있을 때를 예측하도록 차별적 모델을 학습함으로써 우리의 방법이 레이블이 없는 데이터로 확장될 수 있습니다.
classifier guidance의 효과는 classification 함수의 그래디언트에서 강력한 생성 모델을 얻을 수 있음을 보여줍니다.
이는 텍스트 프롬프트 [17, 47, 2]를 사용하여 GAN을 guide하는 최근 방법과 유사하게 CLIP [49]의 노이즈가 많은 버전을 사용하여 텍스트 캡션으로 이미지 생성기를 조절함으로써 사전 학습된 모델을 조건화하는 데 사용될 수 있습니다.
또한 레이블이 지정되지 않은 대규모 데이터 세트를 미래에 활용하여 바람직한 특성을 가진 classifier를 사용하여 나중에 개선할 수 있는 강력한 diffusion 모델을 사전 학습할 수 있음을 시사합니다.
8 Conclusion
우리는 고정 학습 목표를 가진 likelihood-기반 모델의 클래스인 diffusion 모델이 SOTA GAN보다 더 나은 샘플 품질을 얻을 수 있음을 보여주었다.
우리의 개선된 아키텍처는 unconditional 이미지 생성 작업에서 이를 달성하기에 충분하며, classifier guidance 기술을 사용하면 클래스-conditional 작업에서 이를 수행할 수 있다.
후자의 경우, 우리는 classifier 그레디언트의 스케일을 조정하여 충실도를 위한 다양성을 절충할 수 있다는 것을 발견했다.
이러한 guided diffusion 모델은 샘플링 중에 diffusion 모델이 여전히 여러 개의 전진 패스를 필요로 하지만 GAN과 diffusion 모델 사이의 샘플링 시간 간격을 줄일 수 있다.
마지막으로, guidance를 업샘플링과 결합하여 고해상도 conditional 이미지 합성에 대한 샘플 품질을 더욱 향상시킬 수 있다.