2024. 6. 27. 17:46ㆍDiffusion
Improving Diffusion Models for Authentic Virtual Try-on in the Wild
Yisol Choi, Sangkyung Kwak, Kyungmin Lee, Hyungwon Choi, Jinwoo Shin
Abstract
이 논문에서는 사람과 옷을 각각 묘사하는 한 쌍의 이미지가 주어지면, 큐레이팅된 옷을 입은 사람의 이미지를 렌더링하는 이 확산 모델[13, 41]은 데이터에 가우시안 노이즈를 점진적으로 추가하는 순방향 프로세스와 무작위 노이즈를 점진적으로 제거하여 샘플을 생성하는 역방향 프로세스로 구성된 생성 모델입니다. x_0이 데이터 포인트(예: 자동 인코더[37]의 출력에서 이미지 또는 잠재)라고 가정합니다. 미지 기반 virtual try-on을 고려합니다.
이전 연구에서는 virtual try-on을 위해 기존의 예시 기반 인페인팅 디퓨전 모델을 적용하여 다른 방법(예: GAN 기반)에 비해 생성된 시각적의 자연스러움을 개선했지만, 옷의 정체성을 유지하지 못했습니다.
이러한 한계를 극복하기 위해 옷의 충실도를 향상시키고 진정한 virtual try-on 이미지를 생성하는 새로운 디퓨전 모델을 제안합니다.
IDM-VTON이라는 이름의 저희 방법은 옷 이미지의 의미를 인코딩하기 위해 두 가지 모듈을 사용합니다, 디퓨전 모델의 기본 UNet이 주어지면, 1) 시각적 인코더에서 추출된 높은 레벨 피쳐의 시맨틱이 크로스 어텐션 레이어에 융합된 다음, 2) 병렬 UNet에서 추출된 낮은 레벨의 피쳐가 셀프 어텐션 레이어에 융합됩니다.
또한, 생성된 시각적의 진정성을 향상시키기 위해 옷과 사람 이미지 모두에 대한 자세한 텍스트 프롬프트를 제공합니다.
마지막으로, 저희는 충실도와 진정성을 크게 향상시키는 한 쌍의 사람-옷 이미지를 사용한 사용자 지정 방법을 제시합니다.
저희의 실험 결과는 저희의 방법이 옷 세부 사항을 보존하고 정성적으로나 정량적으로 인증된 virtual try-on 이미지를 생성하는 데 있어 이전의 접근 방식(디퓨전 기반 및 GAN 기반 모두)을 능가한다는 것을 보여줍니다.
또한, 제안된 사용자 지정 방법은 실제 시나리오에서 그 효과를 입증합니다.

1 Introduction
이미지 기반 virtual try-on (VTON)은 중요한 컴퓨터 비전 작업으로, 이미지에 의해 주어진 특정 옷을 입은 임의의 사람의 시각을 렌더링하는 것이 목표입니다.
전자 상거래 사용자에게 개인화된 쇼핑 경험을 제공할 수 있는 편리성과 기능으로 인해 입력으로 주어진 옷을 정확하게 묘사하는 진정한 virtual try-on 이미지를 합성하는 데 상당한 관심이 있습니다.
VTON의 핵심 과제는 옷의 패턴과 질감에 왜곡을 일으키지 않고 다양한 포즈나 제스처의 인체에 옷을 맞추는 것입니다 [11, 48].
생성 모델 [7, 13]의 급속한 발전으로 virtual try-on 방법이 발전되었습니다.
이미지 기반 VTON을 위한 대부분의 주요 접근 방식은 Generative Adversarial Networks [7,21](GAN)을 기반으로 하며, 여기서 별도의 워핑 모듈을 사용하여 옷을 인체로 변형하고 GAN 생성기를 사용하여 타겟 사람 [3,5,6,26,27,51]과 혼합합니다.
그러나 이러한 접근 방식은 고품질 이미지를 생성하는 데 어려움을 겪고 있으며 다양한 사람 이미지로 일반화하지 못하는 경우가 많아 옷에 바람직하지 않은 왜곡을 초래합니다.
반면, 최근에는 디퓨전 모델 [13,43]이 GAN에 비해 실제 이미지 [28,33,36,37]를 생성하는 데 우수한 성능을 보여 이러한 문제를 극복할 수 있는 잠재력을 보여줍니다.
최근의 디퓨전 기반 VTON 방법 [8,22,29]은 사전 학습된 text-to-image (T2I) 디퓨전 모델 [32,37,40]의 풍부한 생성 prior를 활용하여 try-on 이미지의 자연스러움을 향상시킵니다.
옷의 세부 사항을 식별하기 위해 pseudo-words [29]로 옷의 의미를 인코딩하거나 명시적인 워핑 네트워크 [8]를 사용합니다.
그러나 이러한 방법은 의복의 세부 사항(예: 패턴, 텍스처, 모양 또는 색상)을 보존하는 데 부족하여 실제 시나리오에 적용하는 데 방해가 됩니다.
이러한 한계를 극복하기 위해 본 논문에서는 옷 이미지의 일관성을 크게 향상시키는 동시에 실제 virtual try-on 이미지를 생성하는 Improved Diffusion Models for Virtual Try-ON (IDM-VTON)을 제안합니다.
특히, 저희는 두 가지 다른 구성 요소로 구성된 정교한 어텐션 모듈을 설계하여 디퓨전 모델에 옷 이미지를 컨디셔닝하는 새로운 접근 방식을 설계합니다:
1) 옷의 높은 레벨의 시맨틱을 인코딩하는 이미지 프롬프트 어댑터와 2) 세분화된 세부 정보를 보존하기 위해 낮은 레벨의 피쳐를 추출하는 UNet 인코더(GarmentNet)입니다.
또한 저희는 단일 옷과 인물 이미지를 사용하여 모델을 사용자 지정할 것을 제안하며, 이는 특히 야생 시나리오에서 virtual try-on 이미지의 시각적 품질을 더욱 향상시킵니다.
마지막으로, 저희는 T2I 디퓨전 모델에 대한 prior 지식을 유지하는 데 도움이 되는 옷 이미지에 대한 자세한 캡션을 제공하는 것의 중요성을 보여줍니다.
저희는 VITON-HD [3] 학습 데이터 세트에서 모델을 학습하고, VITON-HD 및 DressCode [30] 테스트 데이터 세트에서 정성적 및 정량적으로 우수한 결과를 보여줌으로써 이 방법의 효과를 입증했습니다.
또한, 실제 virtual try-on 애플리케이션을 시뮬레이션하기 위해 학습 데이터와 크게 다른 복잡한 패턴의 의류와 다양한 포즈와 제스처의 인간 이미지를 포함하는 야생 데이터 세트를 수집했습니다.
저희의 방법은 In-the-Wild 데이터 세트에서 다른 방법보다 성능이 뛰어나며, 특히 모델을 사용자 지정하면 의류의 정체성을 유지하면서도 실제 트라이온 이미지를 생성할 수 있습니다.
2 Related Works
Image-based virtual try-on.
타겟 사람과 옷을 묘사하는 한 쌍의 이미지가 주어지면 이미지 기반 virtual try-on은 타겟 사람이 주어진 옷을 입는 모습을 생성하는 것을 목표로 합니다.
작업 라인 [3, 5, 6, 26, 27, 51]은 먼저 옷을 사람의 체형으로 변형한 다음 생성기를 사용하여 변형된 옷을 사람 이미지에 적용하는 Generative Adversarial Networks (GANs) [7]을 기반으로 합니다.
많은 작업이 뒤틀린 옷과 사람 [3, 6, 20, 26] 사이의 불일치를 줄이려고 시도했지만 이러한 접근 방식은 복잡한 배경이나 복잡한 포즈를 가진 임의의 사람 이미지에 대한 일반화가 부족합니다.
디퓨전 모델이 큰 성공을 거두면서 [13, 44], 최근 연구에서는 virtual try-on을 위한 디퓨전 모델의 적용을 연구하고 있습니다.
TryOnDiffusion [58]은 두 개의 병렬 UNet을 사용하는 새로운 아키텍처를 제안하고 대규모 데이터 세트에 대한 학습을 통해 디퓨전 기반 virtual try-on의 기능을 보여주었습니다.
후속 연구에서는 virtual try-on을 예시 기반 이미지 인페인팅 문제로 간주했습니다 [53].
그들은 virtual try-on 데이터 세트 [8, 22, 29]에서 인페인팅 디퓨전 모델을 파인튜닝하여 고품질의 virtual try-on 이미지를 생성했습니다.
그러나 이러한 방법은 여전히 옷의 세심한 세부 사항을 보존하여 실제 시나리오에 적용하는 데 어려움을 겪고 있습니다.
Adding conditional control to diffusion models.
text-to-image (T2I) 디퓨전 모델 [32,37,40]은 텍스트 프롬프트에서 고품질 이미지를 생성하는 능력을 보여주었지만, 자연어의 부정확성은 이미지 합성에서 세분화된 제어가 부족합니다.
이를 위해 다양한 작업에서 T2I 디퓨전 모델에 조건부 제어를 추가할 것을 제안했습니다 [31,54,55,57].
ControlNet [55]과 T2I-Adapter [31]는 텍스트 프롬프트와 함께 디퓨전 모델을 제어하기 위해 에지, depth 및 사람의 포즈와 같은 공간 정보를 인코딩하는 추가 모듈을 파인튜닝할 것을 제안했습니다.
Image prompt adapter (IP-Adapter) [54]는 텍스트 및 시각적 프롬프트로 이미지 생성을 제어하기 위해 참조 이미지의 높은 레벨의 시맨틱을 가진 T2I 디퓨전 모델을 조건화할 것을 제안했습니다.
Customizing diffusion models.
여러 연구에서 개인 이미지가 거의 없는 디퓨전 모델을 사용자 지정할 수 있는 가능성을 입증했습니다[4,10,24,39,42].
매개변수 효율적인 파인튜닝 방법 [15,16] 및 정규화된 파인튜닝 objective [25]와 함께 T2I 디퓨전 모델은 치명적인 망각 없이 보이지 않는 예제에 적응할 수 있습니다.
또한 많은 연구에서 마스크 이미지 완성 [45] 또는 이미지 복원 [2]과 같은 다양한 작업에 대한 디퓨전 모델 사용자 지정을 연구했습니다.
이 논문에서는 먼저 virtual try-on을 위한 디퓨전 모델 사용자 지정을 제시하고, 실제 시나리오에 대한 적응을 크게 향상시킨다는 것을 보여줍니다.
3 Method
3.1 Backgrounds on Diffusion Models
디퓨전 모델 [13, 41]은 데이터에 가우시안 노이즈를 점진적으로 추가하는 순방향 프로세스와 랜덤 노이즈를 점진적으로 제거하여 샘플을 생성하는 역방향 프로세스로 구성된 생성 모델입니다.
x_0이 데이터 포인트(예: 오토인코더 [37]의 출력에서 이미지 또는 잠재)라고 가정합니다.
t = 1, ..., T에 대한 노이즈 스케줄 {α_t}_(t=1)^T, {σ_t}_(t=1)^T가 주어지면, 시간 t에서의 순방향 프로세스는 x_t = α_t x_0 + σ_t ϵ로 주어지며, 여기서 ϵ ~ N(0, I)은 가우시안 노이즈입니다.
충분히 큰 σ_T의 경우 x_T ~ N(α_T x_0, σ_T^2 I)은 순수한 랜덤 가우시안 노이즈와 구별할 수 없습니다.
그런 다음 역생성 프로세스는 x_T ~ N(0, σ_T^2 I)에서 초기화되고 x_t로 순차적으로 디노이즈되어 x_0가 데이터 분포에 따라 분포됩니다.
Text-to-image (T2I) diffusion models.
T2I 디퓨전 모델 [32, 37, 40]은 텍스트 조건부 이미지 분포를 모델링하는 디퓨전 모델로, 사전 학습된 텍스트 인코더 (예: T5 [35] 및 CLIP [34] 텍스트 인코더)를 사용한 임베딩에 의해 인코딩됩니다.
컨볼루션 UNet [38] 아키텍처는 디퓨전 기반 생성 모델 [13,44]을 위해 개발되었지만, 최근 연구에서는 UNet을 위한 트랜스포머 [47] 아키텍처를 융합할 가능성을 보여주었습니다.
디퓨전 모델을 학습하는 것은 교란된 데이터 분포의 스코어 함수(즉, denoising score matching [18])를 학습하는 것과 동일한 것으로 나타났으며, 여기서 종종 ϵ-noise prediction loss [13]에 의해 수행됩니다.
형식적으로 데이터 x_0 및 텍스트 임베딩 c가 주어지면 T2I 디퓨전 모델에 대한 학습 loss는 다음과 같이 주어집니다:

, 여기서 x_t = α_t x_0 + σ_t ϵ는 x_0의 순방향 프로세스이고 ω(t)는 각 시간 단계 t에서 가중치 함수입니다.
텍스트 조건화에 대한 더 나은 제어 가능성을 달성하기 위해 무조건적 및 조건부를 공동으로 학습하는 classifier-free guidance (CFG)[14]를 사용합니다.
학습 단계에서 텍스트 조건화는 랜덤으로 드롭아웃(즉, 입력에 null-text를 부여)되고 추론 단계에서 CFG는 텍스트 조건화의 강도를 제어하기 위해 조건적 및 무조건적 노이즈 출력을 보간합니다:

, 여기서 s ≥ 1은 텍스트 조건화를 제어하는 가이던스 척도이고, ϵ_θ(x_t; t)는 null-텍스트 임베딩을 사용한 노이즈 예측을 나타냅니다.
Image prompt adapter [54].
참조 이미지로 T2I 디퓨전 모델을 컨디셔닝하기 위해 Ye et al. [54]에서는 이미지 인코더(예: CLIP [34] 이미지 인코더)에서 추출한 피쳐를 활용하고 텍스트 컨디셔닝에 추가 크로스 어텐션 레이어를 부착하는 Image Prompt Adapter (IP-Adapter)를 제안했습니다 [37].
Q ∈ R^(N x d)는 UNet의 중간 표현에서 query 행렬이고, K_c ∈ R^(N x d), V_c ∈ R^(N x d)는 텍스트 임베딩 c의 key 및 value 행렬이며, 여기서 N은 샘플 수입니다.
크로스 어텐션 레이어의 출력은 Attention(Q, K_c, V_c) = softmax(QK_c^T/√d) · V_c에 의해 제공됩니다.
그런 다음 IP-Adapter는 이미지 임베딩 i에서 key 및 value 행렬 K_i ∈ R^(Nxd), V_i ∈ R^(Nxd)를 계산하고 다음과 같이 크로스 어텐션 레이어를 삽입합니다:
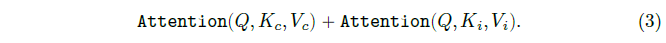
전반적으로 IP-Adapter는 원본 UNet을 동결하고 이미지 임베딩 K_i 및 V_i의 key 및 value 행렬의 (선형) 투영 레이어와 CLIP 이미지 임베딩을 매핑하는 선형 투영 레이어만 파인튜닝합니다.
3.2 Proposed Method
이제 virtual try-on을 위한 디퓨전 모델을 설계하는 방법을 제시합니다.
x_p는 사람의 이미지이고 x_g는 의복의 이미지라고 합니다.
저희의 주요 목표는 이미지 x_g에서 의복을 입은 x_p의 사람을 시각화하는 이미지 x_tr을 생성하는 것입니다.
virtual try-on은 마스크 이미지를 참조 이미지로 채우는 것을 목표로 하는 예시 기반 이미지 인페인팅 문제 [53]로 캐스팅하는 것이 일반적입니다.
여기서, 의복의 관련 정보를 추출하고 디퓨전 모델에 조건부 제어를 추가하는 것이 중요합니다.
이를 위해 저희 모델은 3가지 구성 요소로 구성됩니다; 1) 마스크된 사람 이미지를 포즈 정보로 처리하는 base UNet (TryonNet), 2) 의복의 높은 레벨 시맨틱을 추출하는 이미지 프롬프트 어댑터 (IP-Adapter), 3) 의복의 낮은 레벨 피쳐를 추출하는 의복 UNet 피쳐 인코더 (GarmentNet)입니다.
GarmentNet의 피쳐는 TryonNet의 셀프 어텐션 레이어 내에 융합된 다음 크로스 어텐션 레이어를 통해 IP-Adapter의 피쳐로 처리됩니다.
저희는 그림 2에서 저희 방법에 대한 개요를 제공하고 다음과 같이 각 구성 요소에 대한 자세한 설명을 제공합니다.
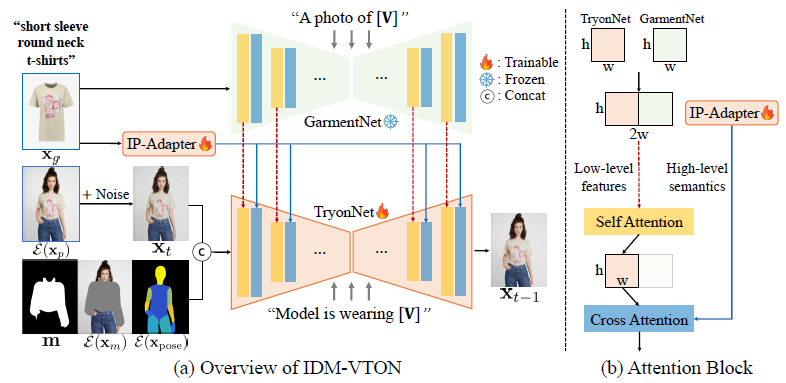
TryonNet.
base UNet 모델의 경우 디퓨전 생성 모델링이 변형 오토 인코더 E의 잠재 공간에서 수행되고 출력이 디코더 D로 전달되어 이미지를 생성하는 잠재 디퓨전 모델 [37]을 고려합니다.
base UNet에 대한 입력의 경우 다음과 같이 네 가지 구성 요소를 concat합니다: 1) 인물 이미지의 잠재, 즉 E(x_p), 2) 인물 이미지의 옷을 제거하는 (리사이징된) 마스크 m, 3) 마스크가 벗겨진 인물 이미지의 잠재 x_m = (1-m) ⊙ x_p, 즉 E(x_m), [3]에 따름, 4) 인물 이미지의 Densepose [9] x_pose의 잠재, 즉 E(x_m)의 잠재.
그런 다음 잠재가 채널 축 내에 정렬되며, 여기서 우리는 UNet의 컨볼루션 레이어를 가중치가 0인 상태로 초기화된 13개 채널로 확장합니다.
디퓨전 모델 [8, 22, 29]이 있는 virtual try-on에 대한 이전 작업과 달리, 우리는 Stable Diffusion XL(SDXL) [33] 인페인팅 모델 [46]을 활용합니다.
Image prompt adapter.
의복 이미지의 높은 레벨의 시맨틱을 조건화하기 위해 이미지 프롬프트 어댑터 (IP-Adapter) [54]를 활용합니다.
의복 이미지를 인코딩하기 위해 frozen CLIP 이미지 인코더 (즉, OpenCLIP [19] ViT-H/14)를 사용하여 피쳐를 추출하고 사전 학습된 IP-Adapter로 초기화된 피쳐 투영 레이어와 크로스 어텐션 레이어를 파인튜닝합니다.
의복의 텍스트 프롬프트를 전달하고 크로스 어텐션은 식 (3)과 같이 계산됩니다.
GarmentNet.
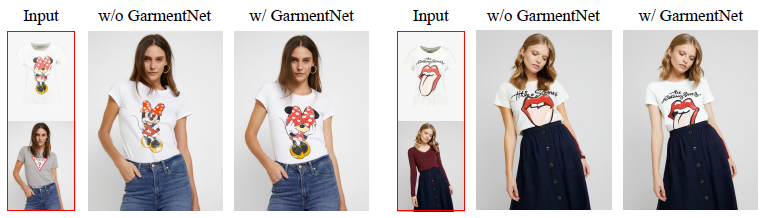
IP-Adapter를 사용하여 이미 의복 이미지를 조정했지만 복잡한 패턴이나 그래픽 인쇄가 있는 경우 의복의 세분화된 세부 정보를 보존하는 데는 부족합니다(예: 그림 6 참조).
이는 CLIP 이미지 인코더가 의복의 낮은 레벨 피쳐를 추출하는 데 부족하기 때문입니다.
이 문제를 해결하기 위해 추가 UNet 인코더(즉, 의복 UNet 인코더)를 활용하여 의복 이미지의 fine-디테일을 인코딩할 것을 제안합니다.
의복 이미지 E(x_g)의 잠재가 주어지면 (frozen) 사전 학습된 UNet 인코더를 통과하여 중간 표현을 얻고 TryonNet의 중간 표현과 concat합니다.
그런 다음 concat된 피쳐에 대한 셀프 어텐션을 계산한 다음 TryonNet의 전반부 차원만 전달합니다.
저희는 사전 학습된 text-to-image 디퓨전 모델의 풍부한 생성 prior를 활용하는 데 도움이 되는 SDXL [33]의 UNet을 GarmentNet에 사용하고 IP-Adapter의 크로스 어텐션 레이어에서 종종 무시되는 낮은 레벨 피쳐를 보완합니다.
비디오 생성을 위한 일관성을 유지하는 데 유사한 어텐션 메커니즘을 사용한 [17]에도 유사한 접근 방식이 도입되었다는 점에 주목하십시오.
Detailed captioning of garments.
대부분의 디퓨전 기반 virtual try-on 모델은 사전 학습된 text-to-image 디퓨전 모델을 활용하지만, 텍스트 프롬프트를 입력으로 받거나 [8,22], 어떤 의복 이미지에도 "upper garment"과 같은 나이브한 텍스트 프롬프트 [29]를 사용하지 않습니다.
text-to-image 디퓨전 모델의 풍부한 생성 prior를 최대한 활용하기 위해 모양이나 텍스쳐와 같은 의복의 세부 사항을 설명하는 포괄적인 캡션 [25]을 제공합니다.
그림 2와 같이, 저희는 의복 이미지에 포괄적인 캡션 (예: "short sleeve round neck t-shirts")을 제공하여 GarmentNet (예: "a photo of short sleeve round neck t-shirts")과 TryonNet (예: "model is wearing short sleeve round neck t-shirts")에 전달합니다.
이는 모델이 자연어를 사용하여 의복의 높은 레벨의 시맨틱을 인코딩하는 데 도움이 되며 이미지 기반 조건을 보완합니다(예: 그림 7 참조).
실제로 저희는 패션 이미지에 이미지 주석을 사용하고 템플릿으로 캡션을 수동으로 제공합니다(자세한 내용은 부록 참조).


Customization of IDM-VTON.
저희 모델은 의류의 세부 사항을 캡처할 수 있지만, 인물 이미지 x_p 또는 의류 이미지 x_g가 학습 분포와 다를 때 종종 어려움을 겪습니다(예: 그림 3 참조).
이를 위해 text-to-image 개인화 방법[2, 39, 45]에서 영감을 받아 의류와 인물 이미지 쌍으로 TryonNet을 파인튜닝하여 IDM-VTON의 효과적인 사용자 지정을 제안합니다.
x_p에 있는 사람이 x_g에 있는 의류를 착용하고 있는 이미지 x_p와 x_g가 있는 경우 IDM-VTON을 파인튜닝하는 것은 간단합니다.
반면 x_p만 있는 경우 의류와 흰색 배경을 세그멘트하여 x_g를 얻습니다.
경험적으로 잘 작동하는 TryonNet의 상위 블록(예: 디코더 레이어)의 어텐션 레이어만 파인튜닝한다는 점에 주목하십시오(예: 표 4 참조).
4 Experiment
4.1 Experimental Setup
Implementation details.
저희는 TryonNet에는 SDXL 마스크 인페인팅 모델 [46]을, 이미지 어댑터에는 사전 학습된 IP-Adapter [54]를, GarmentNet에는 SDXL [33]의 UNet을 사용합니다.
저희는 1024x768 해상도의 11,647개의 person-garment 이미지 쌍을 포함하는 VITON-HD [3] 학습 데이터 세트를 사용하여 모델을 학습합니다.
저희는 배치 크기가 24이고 학습률이 1e-5인 Adam [23] 최적화기를 사용하여 130 에포크 동안 모델을 학습합니다.
사용자 지정을 위해 100 단계에 대해 학습률이 1e-6인 Adam 최적화기를 사용하여 모델을 파인튜닝합니다.
Evaluation dataset.
저희는 공개 VITON-HD [3] 및 DressCode [30] 테스트 데이터 세트에서 모델을 평가합니다.
또한 모델을 실제 시나리오로 일반화하기 위해 웹에서 크롤링한 In-the-Wild 데이터 세트를 내부적으로 수집했습니다.
VITON-HD 및 DressCode에는 간단한 포즈와 탄탄한 배경의 인물 이미지가 포함되어 있지만, In-the-Wild 데이터 세트에는 복잡한 배경이 있는 다양한 포즈와 제스처의 인물 이미지가 있습니다.
또한 의류는 다양한 패턴과 로고를 가지고 있어 VITON-HD 및 DressCode보다 virtual try-on이 더 어렵습니다(예: 그림 3 참조).
또한 In-the-Wild 데이터 세트에는 의류당 여러 명의 인물 이미지가 포함되어 있으므로 각 의류로 네트워크를 사용자 지정할 때 결과를 평가할 수 있습니다.
구체적으로, 62개의 상반신 이미지와 해당 의류를 입은 312개의 인물 이미지로 구성되며, 여기에는 4-6개의 동일한 의류를 입은 인물 이미지가 있습니다.
사용자 지정 실험을 수행하기 위해 각 의류에 대해 하나의 인물 이미지를 선택하고 나머지 250개의 인물 이미지를 평가에 사용합니다.
Baselines.
저희는 저희의 방법을 GAN 기반 방법 (HR-VITON [26] 및 GP-VTON [51]) 및 디퓨전 기반 방법 (LaDI-VTON [29], DCIVON [8] 및 StableVITON [22])과 비교합니다.
HR-VITON 및 GP-VTON에는 대상자의 적합한 의복을 추정하기 위한 별도의 워핑 모듈이 있으며, 의복을 입력으로 사용하여 GAN으로 try-on 이미지를 생성합니다.
LaDI-VTON, DCI-VTON 및 StableVITON은 사전 학습된 Stable Diffusion (SD)도 활용하는 저희의 가장 관련된 베이스라인입니다.
특히 LaDI-VTON 및 DCI-VTON은 의복을 조정하기 위해 별도의 워핑 모듈을 사용하는 반면 StableVITON은 의복 조정을 위해 SD 인코더를 사용합니다.
저희는 이미지를 생성하기 위해 공식 저장소에 제공된 사전 학습된 체크포인트를 사용합니다.
공정한 비교를 위해 사용 가능한 경우 해상도 1024x768 이미지의 이미지를 생성하고, 그렇지 않으면 보간 또는 초해상도 [49]와 같은 다양한 방법을 사용하여 해상도 512x384 및 최대 1024x768의 이미지를 생성하고 가장 좋은 이미지를 보고합니다.
Evalutation metrics.
정량적 평가를 위해 LPIPS [56] 및 SSIM [50]과 같은 낮은 레벨의 재구성 점수와 CLIP [34] 이미지 유사성 점수를 사용하여 높은 레벨의 이미지 유사성을 측정합니다.
생성된 이미지의 진위를 평가하기 위해 VITON-HD 및 DressCode 테스트 데이터 세트에서 Frenchét Inception Distance (FID) [12] 점수를 계산합니다.
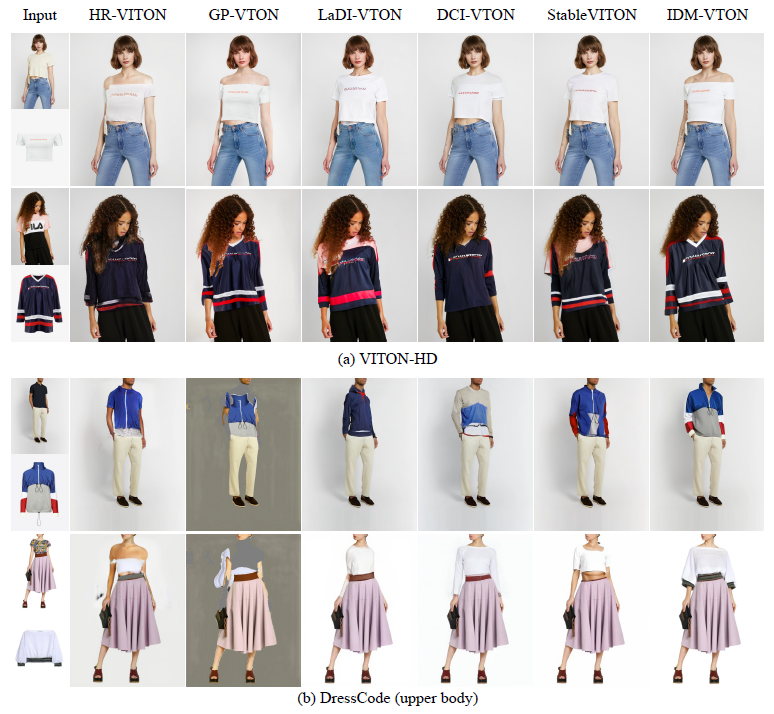
4.2 Results on Public Dataset
Qualitative results.
그림 4는 VITON-HD 및 DressCode 테스트 데이터 세트의 다른 방법과 IDM-VTON의 시각적 비교를 보여줍니다.
우리는 IDM-VTON이 낮은 레벨의 세부 정보와 높은 레벨의 시멘틱을 모두 보존하는 반면, 다른 방법들은 캡처하는 데 어려움을 겪는다는 것을 알 수 있습니다.
GAN 기반 방법(예: HR-VITON 및 GP-VTON)은 의류의 세부 정보를 캡처하는 데 비슷한 성능을 보이지만, 디퓨전 기반 방법에 비해 자연스러운 인간 이미지를 생성하는 데는 부족합니다.
반면, prior 디퓨전 기반 방법(예: LaDI-VTON, DCI-VTON 및 StableVITON)은 의류의 세부 정보(예: 첫 번째 행의 오프숄더 티셔츠 또는 VITON-HD 데이터 세트의 두 번째 행의 스웨트 셔츠의 세부 정보)를 보존하지 못합니다.
또한, IDM-VTON이 DressCode 데이터 세트에 대한 일반화에서 다른 방법보다 훨씬 우수한 성능을 보이는 것으로 나타났습니다.
특히 GAN 기반 방법은 DressCode 데이터 세트에서 성능이 떨어져 일반화 능력이 떨어지는 것으로 나타났습니다.
prior 디퓨전 기반 방법은 GAN 기반보다 자연 이미지 생성에 더 나은 이미지를 보여주지만, 생성된 이미지는 IDM-VTON에 비해 주어진 의류 이미지에 대해 낮은 일관성을 보여줍니다.
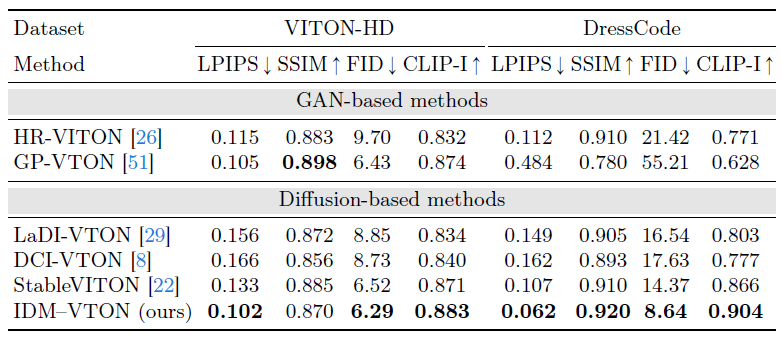
Quantitative results.
표 1은 VITON-HD 및 DressCode 테스트 데이터 세트에서 IDM-VTON (ours)과 다른 방법 간의 정량적 비교를 보여줍니다.
GAN 기반 방법과 비교할 때, IDM-VTON은 재구성 점수 (LPIPS 및 SSIM)에서 비슷한 성능을 보이고 VITON-HD 테스트 데이터 세트에서 FID 및 CLIP 이미지 유사성 점수에서 우수한 성능을 보이는 것으로 나타났습니다.
그러나 GAN 기반 방법의 성능은 그림 4에서 관찰한 DressCode 데이터 세트에서 테스트할 때 크게 저하됩니다.
우리는 IDM-VTON이 VITON-HD 및 DressCode 데이터 세트 모두에서 prior 디퓨전 기반 방법보다 일관되게 성능이 우수하다는 것을 알 수 있습니다.
4.3 Results on In-the-Wild Dataset
여기서는 다른 디퓨전 기반 VTON 방법과 비교하는 까다로운 In-the-Wild 데이터 세트에 대한 방법을 평가합니다.
또한 한 쌍의 garment-person 이미지를 사용하여 사용자 지정한 결과를 보여줍니다.
또한 StableVITON [22]에서 사용자 지정을 테스트합니다.

Qualitative results.
그림 5는 다른 베이스라인과 비교하여 IDM-VTON (ours)의 정성적 결과를 보여줍니다.
IDM-VTON은 LaDI-VTON, DCI-VTON 및 Stable VITON보다 더 많은 실제 이미지를 생성하지만 복잡한 의류 패턴을 유지하는 데 어려움을 겪고 있습니다.
IDM-VTON을 사용자 지정하면 의류(예: 로고 및 텍스트 렌더링)에 대한 높은 일관성을 가진 virtual try-on 이미지를 얻을 수 있지만 StableVITON에서는 사용자 지정이 잘 작동하지 않습니다.
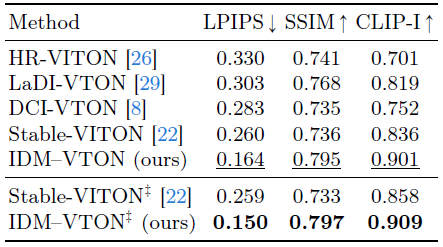
Quantitative results.
표 2에서는 IDM-VTON과 다른 방법 간의 정량적 비교를 보고합니다.
또한 사용자 지정 (즉, IDM-VTON; 및 StableVITON)을 사용하여 IDM-VTON과 StableVITON을 비교합니다.
IDM-VTON은 모든 메트릭에서 다른 방법보다 성능이 뛰어나며, 사용자 지정의 경우 StableVITON보다 성능이 뛰어납니다.
또한 사용자 지정의 IDM-VTON은 다른 방법보다 훨씬 성능이 뛰어나 일반화 기능을 보여줍니다.
4.4 Ablation Studies
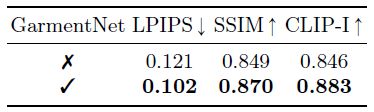
Effect of GarmentNet.
저희는 의복의 fine-디테일을 보존하는 데 GarmentNet의 효과에 대한 ablation 연구를 수행합니다.
비교를 위해 GarmentNet을 사용하지 않고 다른 모델을 학습합니다 (즉, IP-Adapter만 사용하여 의복 이미지를 인코딩).
정성적 결과는 그림 6에 나와 있습니다.
IP-Adapter만 사용하여 학습하면 의복 이미지와 시맨틱적으로 일치하는 진정한 virtual try-on 이미지를 생성할 수 있지만 GarmentNet을 사용하면 의복의 정체성(예: 티셔츠의 그래픽)을 크게 보존할 수 있음을 알 수 있습니다.
또한 LPIPS, SSIM 및 CLIP 이미지 유사성 점수를 측정하여 VITON-HD 테스트 데이터 세트에 대한 정량적 평가를 수행합니다.
표 3에서 GarmentNet을 사용하면 재구성 점수뿐만 아니라 이미지 유사성 점수가 정량적으로 향상되어 정성적 결과와 일치한다는 것을 알 수 있습니다.
Effect of detailed caption.
의류에 대한 자세한 캡션의 효과를 검증하기 위해 나이브 캡션을 사용하는 것을 제외하고 IDM-VTON과 동일한 모델을 학습하고 IDM-VTON과 비교합니다.
특히 나이브 캡션은 모든 상부 의류(예: "model is wearing an upper garment")에 대한 통합된 설명을 제공하는 반면, 자세한 캡션은 각 의류에 대한 구체적인 설명을 제공합니다.
그림 7은 나이브 캡션(왼쪽)과 자세한 캡션(오른쪽)으로 학습된 각 모델을 사용하여 생성된 virtual try-on 이미지를 보여줍니다.
저희는 자세한 캡션으로 학습된 모델이 의류에 대해 더 높은 일관성으로 이미지를 생성하는 것을 관찰했습니다(예: 목과 팔 주변의 메시).
따라서 자세한 캡션을 사용하면 text-to-image 디퓨전 모델의 생성 prior를 활용하여 이미지 기반 virtual try-on의 잠재적인 부정확성을 보완합니다.
Ablation on customization.
사용자 지정 중에는 TryonNet의 상위 블록(즉, 디코더 레이어)을 파인튜닝합니다.
여기서는 사용자 지정을 위한 파인튜닝 레이어 선택에 대한 ablation 연구를 제공합니다.
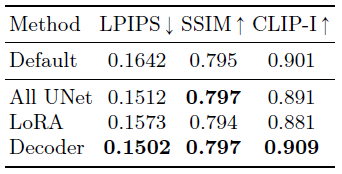
저희는 기본 IDM-VTON (사용자 지정 없음), 모든 UNet 레이어 파인튜닝, low rank adaptation (LoRA) [16] 사용 및 디코더 레이어 파인튜닝을 비교합니다.
표 4에서는 In-the-Wild 데이터 세트의 LPIPS, SSIM 및 CLIP 이미지 유사성 점수를 비교합니다.
저희는 모든 사용자 지정 방법이 기본 IDM-VTON에 비해 재구성 점수를 향상시키는 동시에 CLIP 이미지 유사성 점수에서 비슷한 성능을 보여줍니다.
저희는 디코더 레이어를 파인튜닝하면 사용자 지정 방법 중 가장 성능이 우수한 반면 모든 UNet 레이어를 파인튜닝하면 비슷한 성능을 보여줍니다.
LoRA로 파인튜닝하는 것이 더 효율적이지만 디코더 레이어를 파인튜닝하는 것보다 성능이 낮다는 것을 알 수 있습니다.
5 Conclusion
이 논문에서는 특히 야생 시나리오에서 실제 virtual try-on을 위한 새로운 디퓨전 모델 설계인 IDM-VTON을 소개합니다.
저희는 의류 이미지를 인코딩하기 위해 두 개의 개별 모듈, 즉 시각적 인코더와 병렬 UNet을 통합하여 기본 UNet에 대해 높은 레벨의 시맨틱과 낮은 레벨의 피쳐를 각각 효과적으로 인코딩합니다.
실제 시나리오에서 virtual try-on을 개선하기 위해 한 쌍의 의류-인물 이미지가 주어진 UNet의 디코더 레이어를 파인튜닝하여 모델을 사용자 지정할 것을 제안합니다.
저희는 또한 의류에 대한 자세한 자연어 설명을 활용하여 실제 virtual try-on 이미지를 생성하는 데 도움이 됩니다.
다양한 데이터 세트에 대한 광범위한 실험은 의류의 세부 사항을 보존하고 고충실도 이미지를 생성하는 데 있어 이전 작업에 비해 저희 방법의 우수성을 보여줍니다.
특히, 저희는 야생에서 virtual try-on을 하는 데 있어 저희 방법의 잠재력을 보여줍니다.
Potential negative impact.
이 논문에서는 생성 디퓨전 모델을 사용하여 virtual try-on의 성능을 향상시키는 방법을 소개합니다.
virtual try-on 기술에는 이점과 함정이 있습니다 - 이 도구는 사용자가 주어진 옷으로 효과적으로 외관을 시각화하는 데 도움이 될 수 있습니다.
그러나 사용자는 소유권을 보호할 책임이 있으며 악의적인 사용을 피할 것을 요구합니다.
Limitation.
다른 인페인팅 작업과 마찬가지로 IDM-VTON은 문신이나 피부 여드름과 같은 마스크된 영역에서 인간의 속성을 보존하기 위해 고군분투합니다.
try-on 이미지를 생성할 때 인간 이미지의 인간 속성을 조절하는 방법을 설계할 수 있습니다.
또한 포괄적인 캡션을 제공하면 T2I 디퓨전 모델에 대한 prior 지식을 충분히 활용할 수 있습니다.
텍스트 프롬프트를 통해 의복 생성을 제어하는 것과 같은 광범위한 응용 프로그램을 탐색하는 것은 향후 작업으로 남겨집니다.
'Diffusion' 카테고리의 다른 글
| Adding Conditional Control to Text-to-Image Diffusion Models (0) | 2024.07.30 |
|---|---|
| IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models (0) | 2024.07.08 |
| Projected GANs Converge Faster (0) | 2024.06.15 |
| On Distillation of Guided Diffusion Models (0) | 2023.07.20 |
| GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models (0) | 2023.05.30 |