2024. 10. 16. 11:13ㆍDeep Learning
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang
Abstract
본 논문에서는 범주 이름이나 참조 표현식과 같은 사람의 입력으로 임의의 객체를 탐지할 수 있는 트랜스포머 기반 탐지기 DINO와 grounded 사전 학습을 결합하여 Grounding DINO라는 오픈셋 객체 탐지기를 개발합니다.
오픈셋 객체 탐지의 핵심 솔루션은 오픈셋 개념 일반화를 위해 폐쇄형 탐지기에 언어를 도입하는 것입니다.
언어 및 비전 모달리티를 효과적으로 융합하기 위해 폐쇄형 탐지기를 개념적으로 세 단계로 나누고 피쳐 향상기, 언어 가이드 쿼리 선택, 모달리티 융합을 위한 크로스-모달리티 디코더를 포함하는 타이트한 융합 솔루션을 제안합니다.
먼저 객체 탐지 데이터, grounding 데이터 및 캡션 데이터를 포함한 대규모 데이터 세트에 대해 Grounding DINO를 사전 학습하고 오픈셋 객체 탐지 및 참조 객체 탐지 벤치마크 모두에서 모델을 평가합니다.
Grounding DINO는 COCO, LVIS, ODinW 및 RefCOCO/+/g의 벤치마크를 포함한 세 가지 설정 모두에서 놀라울 정도로 우수한 성능을 발휘합니다.
Grounding DINO는 COCO 제로샷 탐지 벤치마크에서 52.5 AP를 달성합니다.
평균 26.1 AP로 ODinW 제로샷 벤치마크에서 새로운 기록을 세웠습니다.
1 Introduction
Artificial General Intelligence (AGI) 시스템의 기능을 나타내는 핵심 지표는 오픈 월드 시나리오를 처리하는 숙련도입니다.
본 논문에서는 일반적으로 open-set object detection이라고 하는 작업인 사람의 언어 입력으로 지정된 임의의 객체를 감지하는 강력한 시스템을 개발하는 것을 목표로 합니다.
이 작업은 일반적인 객체 탐지기로서의 큰 잠재력으로 광범위하게 응용되고 있습니다.
예를 들어, 이미지 편집을 위한 생성 모델(그림 1(b))과 협력할 수 있습니다.

이 목표를 달성하기 위해 우리는 두 가지 원칙에 따라 강력한 오픈셋 객체 검출기 Grounding DINO를 설계합니다: DINO [57]를 기반으로 한 타이트한 모달리티 융합과 개념 일반화를 위한 대규모 grounded 사전 학습.
Tight modality fusion based on DINO.
오픈셋 감지의 핵심은 보이지 않는 객체 일반화를 위한 언어를 도입하는 것입니다 [1, 7, 25].
대부분의 기존 오픈셋 감지기는 폐쇄형 감지기를 언어 정보가 있는 오픈셋 시나리오로 확장하여 개발됩니다.
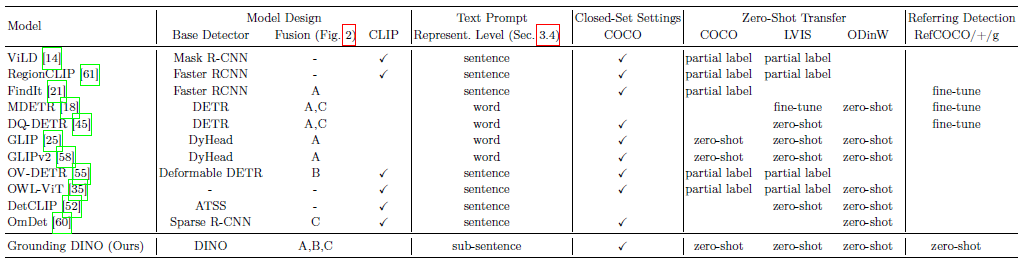
그림 2에 표시된 것처럼 폐쇄형 감지기에는 일반적으로 피쳐 추출을 위한 백본, 피쳐 향상을 위한 넥, 영역 개선(또는 상자 예측)을 위한 헤드 등 세 가지 중요한 모듈이 있습니다.
폐쇄형 감지기는 언어 인식 영역 임베딩을 학습하여 새로운 객체를 감지하도록 일반화하여 각 영역을 언어 인식 의미 공간에서 새로운 범주로 분류할 수 있습니다.
이 목표를 달성하기 위한 핵심은 넥 및/또는 헤드 출력에서 영역 출력과 언어 피쳐 간의 대조 loss를 사용하는 것입니다.

모델이 크로스-모달리티 정보를 정렬하는 데 도움이 되도록 일부 작업은 최종 loss 단계 전에 피쳐를 융합하려고 시도했습니다.
우리는 그림 2에서 물체 감지기의 변조된 설계를 요약합니다.
피쳐 융합은 세 단계로 수행할 수 있습니다: 넥 (단계 A), 쿼리 초기화 (단계 B), 헤드 (단계 C).
예를 들어, GLIP [25]는 넥 모듈 (단계 A)에서 조기 융합을 수행하고, OV-DETR [55]은 언어 인식 쿼리를 헤드 입력으로 사용합니다 (단계 B).
우리는 파이프라인에 더 많은 피쳐 융합을 도입하면 서로 다른 모달리티 피처 간의 더 나은 정렬을 촉진하여 더 나은 성능을 달성할 수 있다고 주장합니다.
개념적으로 간단하지만 이전 작업에서는 세 단계 모두에서 피쳐 융합을 수행하기 어렵습니다.
Faster RCNN과 같은 고전적인 검출기의 설계로 인해 대부분의 블록에서 언어 정보와 상호 작용하기 어렵습니다.
기존 탐지기와 달리 DINO와 같은 트랜스포머 기반 탐지기 방법은 언어 블록과 일관된 구조를 가지고 있습니다.
layer-by-layer 설계를 통해 언어 정보와 쉽게 상호 작용할 수 있습니다.
이 원칙에 따라 우리는 넥, 쿼리 초기화 및 헤드 단계의 세 가지 피쳐 융합 접근 방식을 설계합니다.
보다 구체적으로, 우리는 넥 모듈로 셀프 어텐션, text-to-image 크로스 어텐션, image-to-text 크로스 어텐션을 쌓아 피쳐 향상기를 설계합니다.
그런 다음 언어 가이드 쿼리 선택 방법을 개발하여 탐지 헤드에 대한 쿼리를 초기화합니다.
또한 이미지 및 텍스트 크로스 어텐션 레이어가 있는 헤드 단계에 대한 크로스-모달리티 디코더를 설계하여 쿼리 표현을 향상시킵니다.
Large-scale grounded pre-train for zero-shot transfer.
대부분의 기존 오픈셋 모델 [14, 21]은 개념 일반화를 위해 사전 학습된 CLIP 모델에 의존합니다.
그럼에도 불구하고 이미지-텍스트 쌍에 대해 사전 학습된 CLIP의 효율성은 RegionCLIP [61]의 RegionCLIP 연구에서 확인된 바와 같이 영역-텍스트 쌍 감지 작업에 제한적입니다.
반면, GLIP [25]는 객체 감지를 구문 grounding 작업으로 재구성하고 대규모 데이터에서 객체 영역과 언어 구문 간의 대조 학습을 도입하여 다른 방법을 제시합니다.
heterogeneous 데이터 세트에 대한 뛰어난 유연성과 폐쇄형 및 오픈셋 세트 감지에 대한 놀라운 성능을 보여줍니다.
우리는 grounding 학습 방법론을 채택하고 개선했습니다.
GLIP의 접근 방식은 모든 범주를 랜덤 순서로 문장으로 연결하는 것입니다.
그러나 직접 범주 이름 연결은 피쳐를 추출할 때 관련 없는 범주가 서로에게 미치는 잠재적 영향을 고려하지 않습니다.
이 문제를 완화하고 grounding 학습 중에 모델 성능을 개선하기 위해 문장 레벨 이하의 텍스트 피쳐를 활용하는 기술을 소개합니다.
단어 피쳐 추출 중에 관련 없는 범주 간의 어텐션을 제거합니다.
이 기술에 대한 자세한 내용은 섹션 3.4에서 확인할 수 있습니다.
우리는 대규모 데이터 세트에서 Grounding DINO를 사전 학습하고 COCO [29]와 같은 주류 객체 감지 벤치마크에서 성능을 평가합니다.
일부 연구에서는 "partial label" 프레임워크 — 데이터 하위 집합에 대한 학습 (예: 기본 범주) 및 추가 범주에 대한 테스트 — 에서 오픈셋 감지 모델을 조사했지만, 우리는 실제 적용 가능성을 향상시키기 위해 완전 제로 샷 접근 방식을 옹호합니다.
또한, 우리는 모델을 속성으로 객체를 설명하는 또 다른 중요한 시나리오 Referring Expression Comprehension (REC) [30, 34]로 확장합니다.
그림 1과 같이 폐쇄형 감지, 오픈셋 감지, 참조 객체 감지를 포함한 세 가지 설정 모두에 대한 실험을 수행하여 오픈셋 감지 성능을 종합적으로 평가합니다.
Grounding DINO는 경쟁사보다 큰 차이로 성능이 뛰어납니다.
예를 들어, Grounding DINO는 COCO 학습 데이터 없이 COCO minival에서 52.5 AP에 도달합니다.
또한 평균 AP가 26.1인 ODinW [23] 제로샷 벤치마크에 대한 새로운 SOTA 기술을 확립했습니다.
2 Related Work
Detection Tramformers.
Grouning DINO는 종단 간 트랜스포머 기반 탐지기인 DETR-like 모델 DINO [57]를 기반으로 합니다.
DETR은 [2]에서 처음 제안된 후 지난 몇 년 동안 여러 방향에서 개선되었습니다 [4, 5, 13, 17, 33, 48, 64].
DAB-DETR [31]은 보다 정확한 상자 예측을 위해 앵커 상자를 DETR 쿼리로 도입합니다.
DN-DETR [24]은 초당파적 매칭을 안정화하기 위한 쿼리-디노이징 접근 방식을 제안합니다.
DINO [57]은 대조적 디노이징을 포함한 여러 기술을 추가로 개발하여 COCO 객체 감지 벤치마크에서 새로운 기록을 세웠습니다.
그러나 이러한 탐지기는 주로 폐쇄형 감지에 초점을 맞추고 사전 정의된 범주가 제한되어 있기 때문에 새로운 클래스로 일반화하기 어렵습니다.
Open-Set Object Detection.
오픈 세트 객체 감지는 기존 바운딩 박스 주석을 사용하여 학습되며 언어 일반화의 도움으로 임의의 클래스를 감지하는 것을 목표로 합니다.
OV-DETR [56]은 CLIP 모델로 인코딩된 이미지와 텍스트 임베딩을 쿼리로 사용하여 DETR 프레임워크 [2]의 카테고리-지정 상자를 디코드합니다.
ViLD [14]는 학습된 영역 임베딩에 언어의 의미를 포함하도록 CLIP teacher 모델의 knowledge를 R-CNN-like 검출기로 distill합니다.
GLIP [12]는 객체 감지를 grounding 문제로 공식화하고 추가 grounding 데이터를 활용하여 구문 및 영역 레벨에서 정렬된 시맨틱을 학습하는 데 도움을 줍니다.
이러한 공식은 fully-supervised 감지 벤치마크에서 더 강력한 성능을 달성할 수 있음을 보여줍니다.
DetCLIP [52]는 대규모 이미지 캡션 데이터 세트를 포함하며 생성된 pseudo 레이블을 사용하여 지식 데이터베이스를 확장합니다.
생성된 pseudo 레이블은 일반화 능력을 효과적으로 확장하는 데 도움이 됩니다.
그러나 이전 작업은 부분 단계에서만 멀티모달 정보를 융합하여 최적이 아닌 언어 일반화 능력을 초래할 수 있습니다.
예를 들어, GLIP는 피쳐 향상 (단계 A)에서만 융합을 고려하고 OV-DETR은 디코더 입력 (단계 B)에서만 언어 정보를 주입합니다.
또한 REC 작업은 일반적으로 평가에서 간과되는데, 이는 오픈 세트 감지에 중요한 시나리오입니다.
우리는 표 1의 다른 오픈 세트 방법과 모델을 비교합니다.
3 Grounding DINO
Grounding DINO는 주어진 (Image, Text) 쌍에 대한 여러 쌍의 객체 상자와 명사구를 출력합니다.
예를 들어, 그림 3과 같이 모델은 입력 이미지에서 cat과 table을 찾고 입력 텍스트에서 단어 cat과 table을 해당 레이블로 추출합니다.
객체 감지 및 REC 작업은 모두 파이프라인과 정렬할 수 있습니다.
GLIP [25]에 따라 모든 범주 이름을 객체 감지 작업의 입력 텍스트로 concat합니다.
REC에는 각 텍스트 입력에 대한 바운딩 박스가 필요합니다.
점수가 가장 큰 출력 객체를 REC 작업의 출력으로 사용합니다.
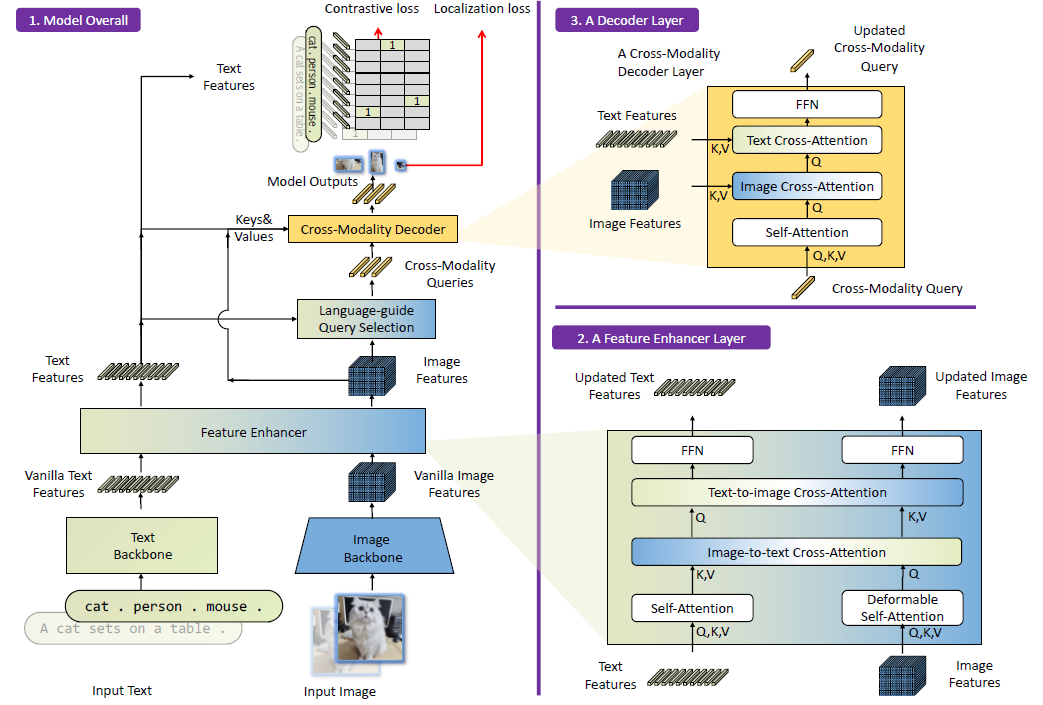
Grounding DINO는 듀얼-인코더-싱글-디코더 아키텍처입니다.
이미지 피쳐 추출을 위한 이미지 백본, 텍스트 피쳐 추출을 위한 텍스트 백본, 이미지 및 텍스트 피쳐 융합을 위한 피쳐 향상기 (섹션 3.1), 쿼리 초기화를 위한 언어-가이드 쿼리 선택 모듈 (섹션 3.2), 상자 개선을 위한 크로스-모달리티 디코더 (섹션 3.3)가 포함되어 있습니다.
각 (Image, Text) 쌍에 대해 먼저 이미지 백본과 텍스트 백본을 각각 사용하여 vanilla 이미지 피쳐와 vanilla 텍스트 피쳐를 추출합니다.
두 개의 vanilla 피쳐는 크로스-모달리티 피쳐 융합을 위해 피쳐 향상기 모듈에 입력됩니다.
크로스-모달리티 텍스트 및 이미지 피쳐를 얻은 후 언어-가이드 쿼리 선택 모듈을 사용하여 이미지 피쳐에서 크로스-모달리티 쿼리를 선택합니다.
대부분의 DETR-like 모델의 객체 쿼리와 마찬가지로 이러한 크로스-모달리티 쿼리는 크로스-모달리티 디코더에 입력되어 두 모달리티 피쳐에서 원하는 피쳐를 조사하고 자체적으로 업데이트됩니다.
마지막 디코더 레이어의 출력 쿼리는 객체 상자를 예측하고 해당 문구를 추출하는 데 사용됩니다.
3.1 Feature Extraction and Enhancer
(Image, Text) 쌍이 주어지면 Swin Transformer [32]와 같은 이미지 백본을 사용하여 멀티 스케일 이미지 피쳐를 추출하고 BERT [8]와 같은 텍스트 백본을 사용하여 텍스트 피쳐를 추출합니다.
이전 DETR-like 탐지기 [57,64]에 이어, 다양한 블록의 출력에서 멀티 스케일 피쳐를 추출합니다.
vanilla 이미지 및 텍스트 피쳐를 추출한 후, 크로스-모달리티 피쳐 융합을 위한 피쳐 향상기에 공급했습니다.
피쳐 향상기에는 다중 피쳐 향상기 레이어가 포함되어 있습니다.
그림 3 블록 2의 피쳐 향상기 레이어를 설명합니다.
변형 가능한 셀프-어텐션을 활용하여 이미지 피쳐를 향상시키고 텍스트 피쳐 향상을 위한 vanilla 셀프-어텐션을 활용합니다.
GLIP [25]에서 영감을 받아 피쳐 융합을 위한 image-to-text 간 크로스-어텐션 모듈과 text-to-image 간 크로스-어텐션 모듈을 추가합니다.
이러한 모듈은 다양한 모달리티의 피쳐를 정렬하는 데 도움이 됩니다.
3.2 Language-Guided Query Selection
Grounding DINO는 입력 텍스트로 지정된 이미지에서 객체를 감지하는 것을 목표로 합니다.
입력 텍스트를 효과적으로 활용하여 객체 감지를 가이드하기 위해 언어 가이드 쿼리 선택 모듈을 설계하여 입력 텍스트와 더 관련성이 높은 피쳐를 디코더 쿼리로 선택합니다.
이미지 피쳐를 X_I ∈ R^(N_I×d)로, 텍스트 피쳐를 X_T ∈ R^(N_T×d)로 표시합니다.
여기서 N_I는 이미지 토큰의 수, N_T는 텍스트 토큰의 수, d는 피쳐 차원에 해당합니다.
실험에서 우리는 특히 d = 256의 피쳐 차원을 활용합니다.
일반적으로 모델에서 N_I의 값은 10,000을 초과하는 반면 N_T는 256 이하로 유지됩니다.
우리의 objective는 디코더의 입력으로 사용할 인코더의 이미지 피쳐에서 N_q 쿼리를 추출하는 것입니다.
DINO 방법에 따라 N_q를 900으로 설정했습니다.
이미지 피쳐의 상위 N_q 쿼리 인덱스, I_N_q로 표시, 는 다음 식을 사용하여 선택됩니다:
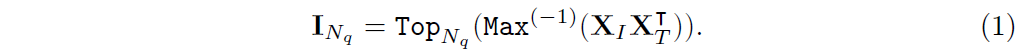
이 표현식에서 Top_N_q는 상위 N_q 인덱스를 선택하는 연산을 나타냅니다.
함수 Max^(-1)은 -1 차원을 따라 max 연산을 실행하고 기호 ⊺는 행렬 전치를 나타냅니다.
알고리즘 1의 쿼리 선택 프로세스를 PyTorch 스타일로 제시합니다.
언어 가이드 쿼리 선택 모듈은 N_q 인덱스를 출력합니다.
선택한 인덱스를 기반으로 피쳐를 추출하여 쿼리를 초기화할 수 있습니다.
DINO [57]에 이어 혼합 쿼리 선택을 사용하여 디코더 쿼리를 초기화합니다.
각 디코더 쿼리에는 두 부분이 포함되어 있습니다: 콘텐츠 부분과 위치 부분 [33] 각각.
우리는 위치 부분을 인코더 출력으로 초기화되는 동적 앵커 박스 [31]로 공식화합니다.
다른 부분인 콘텐츠 쿼리는 학습 중에 학습할 수 있도록 설정됩니다.
3.3 Cross-Modality Decoder
우리는 그림 3 블록 3과 같이 이미지 및 텍스트 모달리티 피쳐를 결합하기 위한 크로스 모달리티 디코더를 개발합니다.
각 크로스 모달리티 쿼리는 셀프 어텐션 레이어, 이미지 피쳐를 결합하기 위한 이미지 크로스 어텐션 레이어, 텍스트 피쳐를 결합하기 위한 텍스트 크로스 어텐션 레이어, 각 크로스 모달리티 디코더 레이어의 FFN 레이어에 입력됩니다.
더 나은 모달리티 정렬을 위해 쿼리에 텍스트 정보를 주입해야 하므로 각 디코더 레이어에는 DINO 디코더 레이어에 비해 텍스트 크로스 모달리티 레이어가 추가됩니다.
3.4 Sub-Sentence Level Text Feature
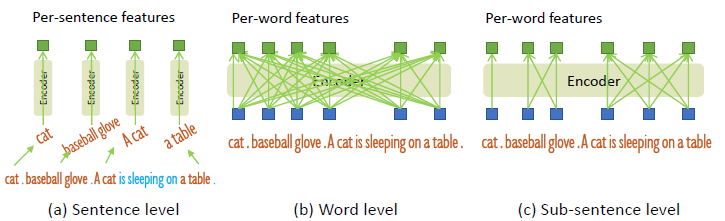
이전 연구에서는 두 가지 종류의 텍스트 프롬프트를 탐색했으며, 그림 4와 같이 문장 레벨 표현과 단어 레벨 표현으로 명명했습니다.
문장 레벨 표현 [35, 52]은 전체 문장을 하나의 피쳐로 인코딩합니다.
phrase grounding 데이터의 일부 문장에 여러 개의 phrase가 있는 경우, 이 phrase를 추출하고 다른 단어를 폐기합니다.
이러한 방식으로 문장에서 세분화된 정보를 잃으면서 단어 간의 영향을 제거합니다.
단어 레벨 표현 [12,18]을 사용하면 여러 카테고리 이름을 하나의 포워드로 인코딩할 수 있지만, 특히 입력 텍스트가 여러 카테고리 이름을 임의의 순서로 연결한 경우 카테고리 간에 불필요한 종속성이 발생합니다.
그림 4 (b)에 표시된 것처럼 일부 관련 없는 단어는 어텐션 중에 상호 작용합니다.
원치 않는 단어 상호 작용을 피하기 위해 "sub-sentence" 레벨 표현이라는 이름의 관련 없는 카테고리 이름 간의 어텐션을 차단하기 위해 어텐션 마스크를 도입합니다.
세분화된 이해를 위해 단어별 피쳐를 유지하면서 서로 다른 카테고리 이름 간의 영향을 제거합니다.
3.5 Loss Function
이전의 DETR-like 작업 [2, 24, 31, 33, 57, 64]에 이어, 바운딩 박스 회귀에 L1 loss와 GIOU [40] loss를 사용합니다.
GLIP [25]를 따르고 분류를 위해 예측된 객체와 언어 토큰 간의 대조 loss를 사용합니다.
특히, 각 쿼리에 텍스트 피쳐를 추가하여 각 텍스트 토큰에 대한 로짓을 예측한 다음 각 로짓에 대한 focal loss [28]를 계산합니다.
상자 회귀 및 분류 비용은 먼저 예측과 ground truth 간의 초당적 매칭에 사용됩니다.
그런 다음 동일한 loss 구성 요소를 가진 ground truth와 일치하는 예측 간의 최종 loss를 계산합니다.
DETR-like 모델에 따라 각 디코더 레이어와 인코더 출력 후에 auxiliary loss를 추가합니다.
4 Experiments
우리는 세 가지 설정에 대해 광범위한 실험을 수행합니다: COCO 감지 벤치마크에 대한 폐쇄 세트 설정 (섹션 C.2), 제로 샷 COCO, LVIS 및 ODinW에 대한 오픈셋 세트 설정 (섹션 4.2), RefCOCO/+/g에 대한 참조 감지 설정 (섹션 4.3).
그런 다음 Ablation을 수행하여 모델 설계의 효과를 보여줍니다 (섹션 4.5).
또한 섹션 C.1.에서 몇 가지 플러그인 모듈을 학습하여 잘 학습된 DINO를 오픈셋 시나리오로 전송하는 방법을 모색합니다.
모델 효율성 테스트는 섹션 C.4.
4.1 Implementation Details
우리는 각각 이미지 백본으로 Swin-T [32]를 사용하는 Grounding DINO T와 Swin-L [32]을 사용하는 Grounding DINO L의 두 가지 모델 변형을 학습했습니다.
우리는 Hugging Face [49]의 BERT 기반 [8]을 텍스트 백본으로 활용했습니다.
새로운 클래스에 대한 모델 성능에 더 집중함에 따라, 우리는 본문에 제로 샷 전송 및 참조 탐지 결과를 나열합니다.
기본적으로 우리는 모델에서 DINO 다음에 900개의 쿼리를 사용합니다.
최대 텍스트 토큰 수를 256으로 설정합니다.
BERT를 텍스트 인코더로 사용하여 BPE 체계 [42]로 텍스트를 토큰화합니다.
우리는 피쳐 향상기 모듈에서 6개의 피쳐 향상기 레이어를 사용합니다.
크로스 모달리티 디코더도 6개의 디코더 레이어로 구성됩니다.
우리는 이미지 크로스 어텐션 레이어서 deformable attention [64]을 활용합니다.
매칭 비용과 최종 loss에는 모두 분류 loss (또는 contrastive losses), 박스 L1 loss, GIOU [40] loss가 포함됩니다.
DINO에 따라 Hungarian 매칭 시 분류 비용, 박스 L1 비용, GIOU 비용의 가중치를 각각 2.0, 5.0, 2.0으로 설정했습니다.
해당 loss 가중치는 최종 loss 계산에서 1.0, 5.0, 2.0입니다.
Swin Transformer Tiny 모델은 총 배치 크기가 32인 16개의 Nvidia V100 GPU에서 학습됩니다.
우리는 8x에서 32x까지 세 가지 이미지 피쳐 척도를 추출합니다.
추가 피쳐 척도로 32x 피쳐 맵을 64x로 다운샘플링하기 때문에 DINO에서 "4scale"로 명명되었습니다.
Swin Transformer Large 모델의 경우 백본에서 4x에서 32x까지 네 가지 이미지 피쳐 척도를 추출합니다.
이 모델은 총 배치 크기가 64개인 64개의 Nvidia A100 GPU에서 학습됩니다.
4.2 Zero-Shot Transfer of Grounding DINO
이 설정에서는 대규모 데이터 세트에서 모델을 사전 학습하고 새로운 데이터 세트에서 모델을 직접 평가합니다.
또한 이전 작업과 모델을 보다 철저하게 비교하기 위해 파인튜닝된 결과를 나열합니다.
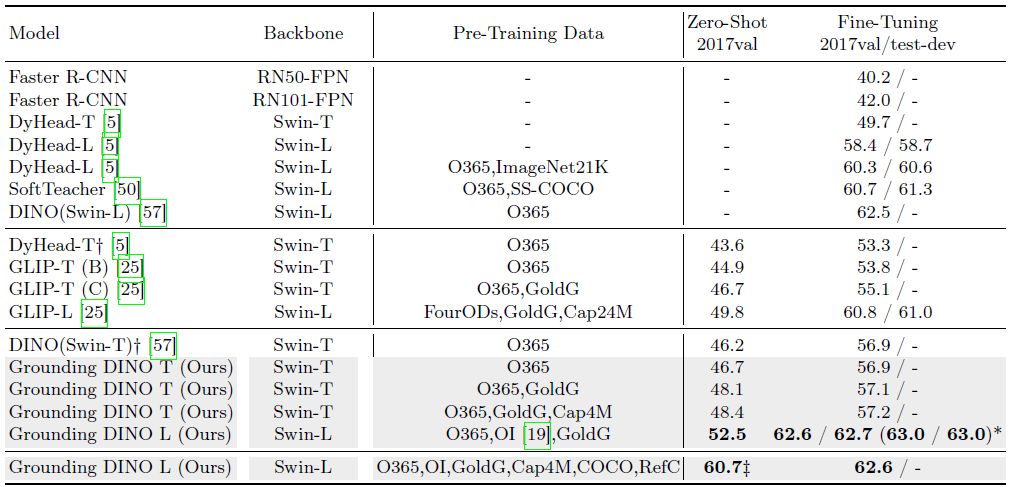
COCO Benchmark
표 2에서 Grounding DINO와 GLIP 및 DINO를 비교합니다.
대규모 데이터 세트에서 모델을 사전 학습하고 COCO 벤치마크에서 모델을 직접 평가합니다.
O365 데이터 세트 [43]가 COCO의 모든 카테고리를 거의 포함했기 때문에, 우리는 COCO에서 사전 학습된 DINO를 제로 샷 베이스라인으로 평가합니다.
그 결과 DINO가 DyHead보다 COCO 제로 샷 전송에서 더 나은 성능을 발휘하는 것으로 나타났습니다.
Grounding DINO는 동일한 설정에서 DINO 및 GLIP에 비해 +0.5AP 및 +1.8AP로 제로 샷 전송 설정에서 모든 이전 모델을 능가합니다.
Grounding 데이터는 제로 샷 전송 설정에서 1AP (48.1 vs. 46.7) 이상을 도입하여 Grounding DINO에 여전히 도움이 됩니다.
더 강력한 백본과 더 큰 데이터를 통해 Grounding DINO는 학습 중에 COCO 이미지를 보지 않고 COCO 객체 감지 벤치마크에서 52.5AP의 신기록을 세웠습니다.
Grounding DINO는 COCO minival에서 62.6 AP를 획득하여 DINO의 62.5 AP를 능가합니다.
입력 이미지를 1.5배 확대하면 이점이 줄어듭니다.
텍스트 브랜치가 다른 입력 이미지를 가진 모델 간의 격차를 확대하는 것으로 의심됩니다.
입력 크기가 큰 성능 평준화에도 불구하고 Grounding DINO는 COCO 데이터 세트에서 파인튜닝을 통해 COCO 테스트 개발에서 인상적인 63.0 AP를 얻습니다 (표 2의 괄호 안의 숫자 참조).
LVIS Benchmark
LVIS [15]는 롱테일 오브젝트에 대한 데이터 세트입니다.
평가를 위해 1000개 이상의 카테고리가 포함되어 있습니다.
우리는 모델의 제로 샷 능력을 테스트하기 위해 다운스트림 작업으로 LVIS를 사용합니다.
우리는 모델의 베이스라인으로 GLIP와 DetCLipv2를 사용합니다.
결과는 표 3에 나와 있습니다.
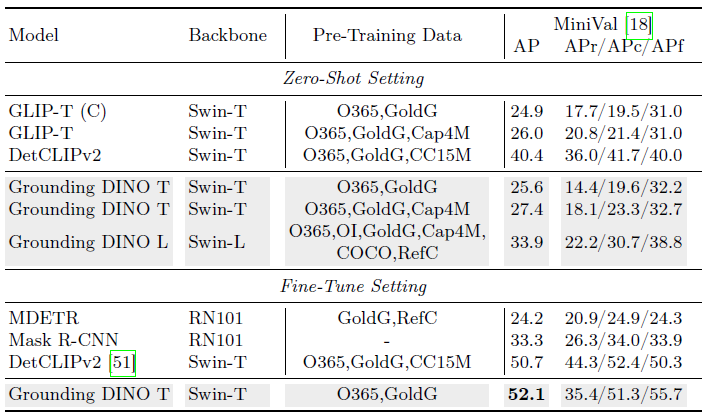
우리는 결과에서 두 가지 흥미로운 현상을 발견했습니다.
첫째, Grounding DINO는 GLIP보다 일반적인 객체보다 더 잘 작동하지만 희귀 카테고리에서는 더 나빴습니다.
LVIS에서 DETR과 유사한 모델을 검토한 결과, [9]의 표 2 및 [18]의 표 6과 같은 유사한 전체 AP에도 불구하고 이러한 모델은 종종 낮은 희귀 카테고리 AP를 보인다는 점에 주목했습니다.
저희가 아는 한, 추가 학습 데이터 없이 LVIS에서 희귀성 문제를 효과적으로 해결하는 기존 DETR과 유사한 모델은 아키텍처의 특징적인 한계일 수 있습니다.

또 다른 현상은 Grounding DINO가 GLIP보다 더 많은 데이터로 더 큰 이득을 얻는다는 것입니다.
예를 들어, Grounding DINO는 캡션 데이터 Cap4M으로 +1.8 AP 이득을 가져온 반면, GLIP는 +1.1 AP에 불과합니다.
Grounding DINO는 GLIP에 비해 확장성이 더 우수하다고 생각합니다.
대규모 학습은 향후 작업으로 남겨둘 것입니다.
GLIP보다 더 나은 결과를 얻었지만, 우리는 Grounding DINO가 대규모 데이터로 학습된 DetCLipv2보다 열등하다는 것을 발견했습니다.
이러한 성능 차이는 학습 데이터 세트와 LVIS 데이터 세트 간의 데이터 분포 차이에 기인할 수 있습니다.
Grounding DINO의 완전한 잠재력을 드러내기 위해 LVIS 데이터 세트에서 이를 파인튜닝했습니다.
표 3은 모델의 훌륭한 기능을 강조합니다.
놀랍게도 O365 및 GoldG 데이터 세트에서만 사전 학습되었음에도 불구하고 Grounding DINO는 DetCLipv2-T를 1.5AP의 차이로 능가합니다.
이 결과는 Grounding DINO가 파인튜닝 (목표 데이터 세트와 정렬) 후 더 나은 성능을 산출하는 데 도움이 되는 더 나은 객체 레벨 표현을 학습했을 수 있음을 보여줍니다.
향후 연구에서는 제로 샷 일반화 성능을 더욱 향상시키기 위해 학습 데이터의 의미론적 개념 범위를 변경하고 학습 데이터의 규모를 늘리는 등 더 많은 연구를 수행할 것입니다.
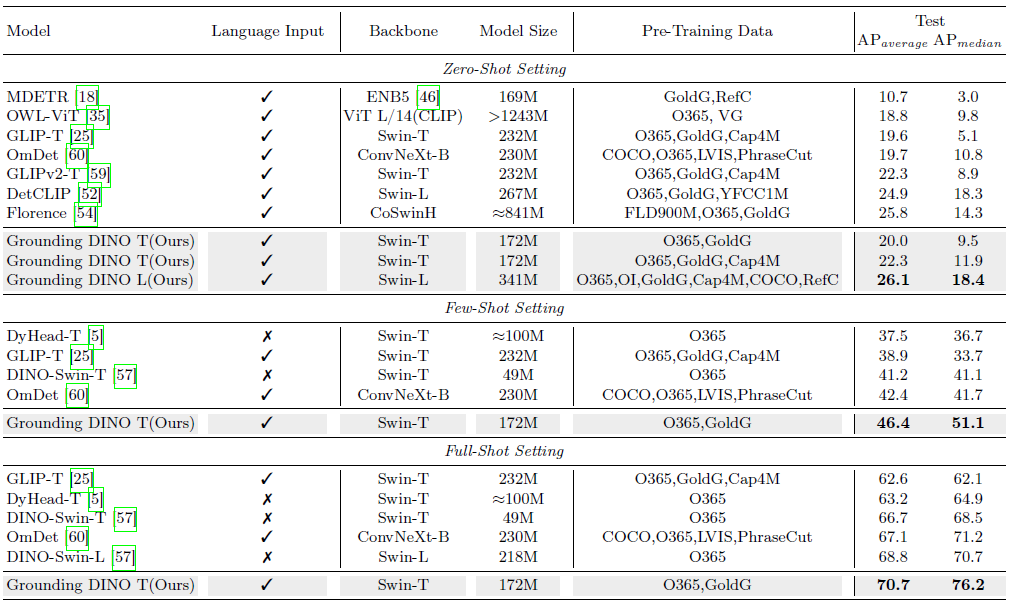
ODinW Benchmark
ODinW (Object Detection in the Wild) [23]는 실제 시나리오에서 모델 성능을 테스트하기에 더 어려운 벤치마크입니다.
평가를 위해 35개 이상의 데이터 세트를 수집합니다.
제로 샷, 퓨 샷 및 풀 샷 결과의 세 가지 설정을 표 4에 보고합니다.
Grounding DINO는 이 벤치마크에서 우수한 성능을 발휘합니다.
사전 학습을 위해 O365와 GoldG만 사용한 Grounding DINO T는 퓨 샷 및 풀 샷 설정에서 DINO를 능가합니다.
인상적으로, Swin-T 백본을 사용한 Grounding DINO는 풀 샷 설정에서 Swin-L을 사용한 DINO를 능가합니다.
제로샷 설정에서 동일한 백본에서 Grounding DINO는 GLIP를 능가합니다.
Grounding DINO와 GLIPv2-T는 유사한 AP 평균을 보여줍니다.
그러나 주요 차이점은 Grounding DINO가 GLIPv2-T를 크게 능가하는 AP_median에 있습니다(11.9 vs. 8.9).
이는 GLIPv2가 서로 다른 데이터 세트에서 더 큰 성능 분산을 보일 수 있지만, Grounding DINO가 더 일관된 성능 레벨을 유지한다는 것을 시사합니다.
GLIPv2는 마스킹 텍스트 학습 및 크로스-인스턴스 대조 학습과 같은 고급 기술을 통합하여 Grounding DINO 모델보다 더 복잡합니다.
또한, 우리 모델 (172M 파라미터)은 GLIPv2 (232M 파라미터)에 비해 더 컴팩트합니다.
이러한 요소—성능 일관성, 모델 복잡성 및 크기—를 결합하면 실제 오픈 세트 시나리오에서 우리 모델의 기능에 대한 우려를 해결할 수 있습니다.
Grounding DINO L은 26.1 AP로 ODinW 제로 샷에서 거대한 Florence 모델 [54]을 능가하는 신기록을 세웠습니다.
결과는 Grounding DINO의 일반화와 확장성을 보여줍니다.
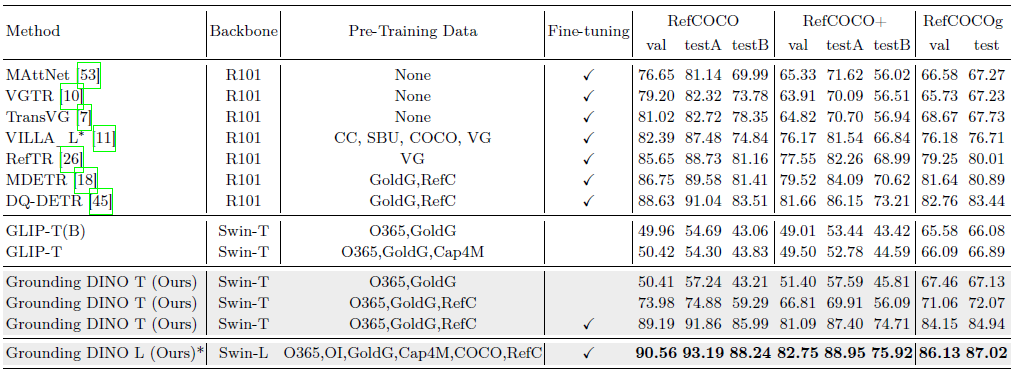
4.3 Referring Object Detection Settings
우리는 REC 작업에서 모델의 성능을 더 자세히 살펴봅니다.
우리는 GLIP [25]를 베이스라인으로 활용합니다.
우리는 RefCOCO/+/g에서 모델 성능을 직접 평가합니다.
결과는 표 5에 나와 있습니다.
Grounding DINO는 동일한 설정에서 GLIP를 능가합니다.
그럼에도 불구하고 GLIP와 Grounding DINO는 모두 REC 데이터 없이는 좋은 성능을 발휘하지 못합니다.
캡션 데이터나 더 큰 모델과 같은 더 많은 학습 데이터는 최종 성능에 도움이 되지만 상당히 미미합니다.
학습에 RefCOCO/+/g 데이터를 주입한 후, Grounding DINO는 상당한 이득을 얻습니다.
결과는 대부분의 현재 오픈 세트 물체 감지기가 보다 세분화된 감지를 위해 더 많은 주의를 기울여야 한다는 것을 보여줍니다.
4.4 Effect of RefC and COCO Data
일부 설정에서는 RefCOCO/+/g (표에서 "RefC"로 표시됨)과 COCO를 학습에 추가합니다.
표 6에서 이러한 데이터의 영향을 살펴봅니다.
결과는 RefC가 COCO 제로 샷 및 파인튜닝 성능을 개선하는 데 도움이 되지만 LVIS 및 ODinW 결과를 손상시킨다는 것을 보여줍니다.
COCO가 도입되면 COCO 결과가 크게 개선됩니다.
이는 COCO가 LVIS에서 약간의 개선을 가져오고 ODinW에서 약간 감소한다는 것을 보여줍니다.
4.5 Ablations
우리는 이 섹션에서 ablation 연구를 수행합니다.
우리는 오픈셋 객체 감지를 위한 엄격한 융합 grounding 모델과 하위 문장 레벨 텍스트 프롬프트를 제안합니다.
모델 설계의 효과를 검증하기 위해 다양한 변형에 대한 일부 융합 블록을 제거합니다.
결과는 표 7에 나와 있습니다.
모든 모델은 Swin-T 백본으로 O365에서 사전 학습됩니다.
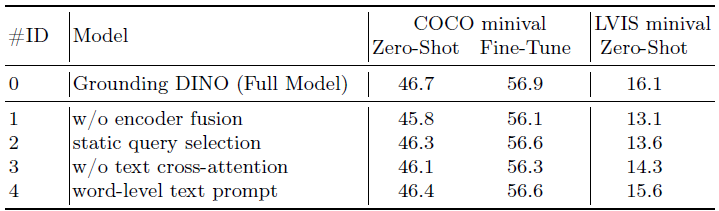
결과는 인코더 융합이 COCO 및 LVIS 데이터 세트 모두에서 모델 성능을 크게 향상시킨다는 것을 보여줍니다.
모델 #1과 베이스라인 모델 #0을 비교한 결과는 이러한 관찰을 검증합니다.
언어-가이드 쿼리 선택, 텍스트 크로스-어텐션 및 하위 문장 텍스트 프롬프트와 같은 다른 기술도 LVIS 성능에 긍정적으로 기여하여 각각 +3.0 AP, +1.8 AP, +0.5 AP의 상당한 이득을 얻었습니다.
또한 이러한 방법은 COCO 제로샷 성능을 향상시켜 그 효과를 더욱 강조합니다.
그러나 언어-가이드 쿼리 선택 및 하위 문장 텍스트 프롬프트가 COCO 파인튜닝 성능에 미치는 영향이 최소화되는 것을 관찰했습니다.
이러한 방법이 모델 파라미터를 변경하거나 계산 부담을 추가하지 않는다는 점을 고려할 때 이러한 결과는 합리적입니다.
텍스트 크로스-어텐션은 인코더 융합보다 적은 수의 파라미터를 도입했지만 인코더 융합(+0.6 vs. +0.8)에 비해 성능 개선이 적었습니다.
이 결과는 파인튜닝 성능이 모델의 파라미터에 주로 영향을 받아 모델 확장이 성능 향상을 위한 유망한 방향임을 시사합니다.
5 Conclusion
본 논문에서는 Grounding DINO 모델을 제시했습니다.
Grounding DINO는 DINO를 오픈셋 객체 감지로 확장하여 텍스트가 쿼리로 주어지면 임의의 객체를 감지할 수 있도록 합니다.
오픈셋 객체 감지기 설계를 검토하고 크로스-모달리티 정보를 더 잘 융합하기 위한 타이트한 융합 접근 방식을 제안합니다.
우리는 텍스트 프롬프트에 대한 감지 데이터를 보다 합리적인 방식으로 사용하기 위해 하위 문장 레벨 표현을 제안합니다.
결과는 모델 설계 및 융합 접근 방식의 효과를 보여줍니다.
또한 오픈셋 객체 감지를 REC 작업으로 확장하고 그에 따라 평가를 수행합니다.
우리는 파인튜닝 없이는 기존 오픈셋 감지기가 REC 데이터에 잘 작동하지 않는다는 것을 보여줍니다.
따라서 향후 연구에서 REC 제로 샷 성능에 더욱 주의를 기울일 것을 촉구합니다.
Limitations:
오픈셋 객체 감지 설정에서 뛰어난 성능을 발휘함에도 불구하고 GLIPv2와 같은 세그멘테이션 작업에는 Grounding DINO를 사용할 수 없습니다.
학습 데이터가 가장 큰 GLIP 모델보다 작기 때문에 최종 성능이 제한될 수 있습니다.
또한 경우에 따라 우리 모델은 잘못된 긍정적인 결과를 생성할 수 있으며, 환각을 줄이기 위해 더 많은 기술이나 데이터가 필요할 수 있습니다.
Social Impacts:
이 모델과 같은 딥러닝 모델을 사용하면 적대적 공격을 통해 취약점에 노출됩니다.
또한 모델 출력의 정확성과 정확성을 보장할 수 없습니다.
또한 모델의 오픈셋 탐지 기능이 불법적인 목적으로 악용될 위험도 있습니다.
'Deep Learning' 카테고리의 다른 글
| Recognize Anything: A Strong Image Tagging Model (0) | 2024.10.18 |
|---|---|
| Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks (1) | 2024.10.17 |
| Faster Segment Anything: Towards Lightweight SAM for Mobile Applications (1) | 2024.10.15 |
| Deep Generative Filter for Motion Deblurring (0) | 2024.01.02 |
| Learning bothWeights and Connections for Efficient Neural Networks (1) | 2023.05.03 |