2024. 10. 18. 16:09ㆍDeep Learning
Recognize Anything: A Strong Image Tagging Model
Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Shilong Liu, Yandong Guo, Lei Zhang
Abstract
Recognize Anything Model (RAM): a strong foundation model for image tagging을 소개합니다:
RAM은 컴퓨터 비전 분야의 대규모 모델에 상당한 진전을 이루었으며, 일반적인 카테고리를 높은 정확도로 인식하는 제로 샷 기능을 보여줍니다.
RAM은 수동 주석 대신 대규모 이미지-텍스트 쌍을 학습에 활용하여 이미지 태깅을 위한 새로운 패러다임을 도입합니다.
RAM 개발은 네 가지 주요 단계로 구성됩니다.
첫째, 자동 텍스트 시맨틱 구문 분석을 통해 주석이 없는 이미지 태그를 대규모로 얻습니다.
그런 다음 캡션과 태깅 작업을 통합하여 자동 주석을 위해 예비 모델을 학습하고, 각각 원본 텍스트와 구문 분석된 태그로 supervise합니다.
셋째, 데이터 엔진을 사용하여 추가 주석을 생성하고 잘못된 주석을 정리합니다.
마지막으로, 처리된 데이터로 모델을 재학습하고 작지만 고품질의 데이터 세트를 사용하여 파인튜닝합니다.
우리는 수많은 벤치마크에서 RAM의 태깅 기능을 평가하고 인상적인 제로 샷 성능을 관찰하여 CLIP 및 BLIP를 크게 능가합니다.
놀랍게도 RAM은 fully supervised 방식을 능가하고 Google tagging API로 경쟁력 있는 성능을 보여줍니다.
1. Introduction
대규모 웹 데이터 세트에서 학습된 Large language models (LLM)은 nature language processing (NLP)의 혁명을 촉발했습니다.
이러한 모델 [20, 5]은 인상적인 제로샷 일반화를 보여주어 학습 영역을 넘어서는 작업과 데이터 분포로 일반화할 수 있게 해줍니다.
computer vision (CV)의 경우 Segment Anything Model (SAM) [12]도 데이터 확장을 통해 놀라운 제로샷 로컬라이제이션 능력을 입증했습니다.
그러나 SAM은 로컬라이제이션과 동등한 또 다른 기본 작업인 시맨틱 레이블을 출력할 수 있는 기능이 부족합니다.
이미지 태깅이라고도 하는 다중 레이블 이미지 인식은 주어진 이미지의 여러 레이블을 인식하여 시맨틱 레이블을 제공하는 것을 목표로 합니다.
이미지 태깅은 이미지에 본질적으로 객체, 장면, 속성 및 동작을 포괄하는 여러 레이블이 포함되어 있기 때문에 중요하고 실용적인 컴퓨터 비전 작업입니다.
안타깝게도 다중 레이블 분류, 감지, 세그멘테이션 및 비전-언어 접근 방식의 기존 모델은 그림 1과 같이 범위가 제한되거나 정확도가 떨어지는 태깅에 결함이 있는 것으로 나타났습니다.

두 가지 핵심 구성 요소가 이미지 태깅의 진행을 방해합니다.
1) 문제는 대규모 고품질 데이터를 수집하는 데 있습니다.
특히, 방대한 수의 카테고리가 있는 대규모 이미지에 반자동 또는 자동 주석을 달 수 있는 보편적이고 통합된 라벨 시스템과 효율적인 데이터 주석 엔진이 부족합니다.
2) 대규모 weakly-supervised 데이터를 활용하여 개방형 어휘와 강력한 모델을 구성할 수 있는 효율적이고 유연한 모델 설계가 부족합니다.
이러한 주요 병목 현상을 해결하기 위해 본 논문에서는 이미지 태깅을 위한 강력한 기반 모델인 Recognize Anything Model (RAM)을 소개합니다.
RAM은 레이블 시스템, 데이터 세트 및 데이터 엔진을 포함한 데이터와 관련된 문제와 모델 설계의 한계를 극복합니다.
Label System:
우리는 보편적이고 통합된 라벨 시스템을 구축하는 것으로 시작합니다.
우리는 인기 있는 학술 데이터 세트(분류, 탐지, 세그멘테이션)의 카테고리와 상용 태깅 제품(Google, Microsoft, Apple)을 통합합니다.
라벨 시스템은 모든 공개 태그와 텍스트의 공통 태그를 병합하여 얻으므로 대부분의 공통 레이블을 6,449개의 적당한 양으로 커버합니다.
나머지 오픈 어휘 라벨은 오픈 세트 인식을 통해 식별할 수 있습니다.
Dataset:
레이블 시스템으로 대규모 이미지에 자동으로 주석을 붙이는 방법도 또 다른 과제입니다 [30].
공개적으로 사용 가능한 이미지-텍스트 쌍을 대규모로 활용하여 강력한 시각적 모델을 학습하는 CLIP [22] 및 ALIGN [11]에서 영감을 얻은 우리는 이미지 태깅에 유사한 데이터 세트를 채택합니다.
이러한 대규모 이미지-텍스트 데이터를 태깅에 활용하기 위해 [9, 10]을 따라 텍스트를 구문 분석하고 자동 텍스트 시맨틱 구문 분석을 통해 이미지 태그를 얻습니다.
이 프로세스를 통해 이미지-텍스트 쌍에 따라 주석이 없는 다양한 이미지 태그 컬렉션을 얻을 수 있습니다.
Data Engine:
그러나 웹의 이미지-텍스트 쌍은 본질적으로 노이즈가 많아 누락되거나 잘못된 레이블이 포함되는 경우가 많습니다.
주석의 품질을 향상시키기 위해 태깅 데이터 엔진을 설계합니다.
누락된 레이블을 처리할 때 기존 모델을 활용하여 추가 태그를 생성합니다.
잘못된 레이블과 관련하여 먼저 이미지 내의 다른 태그에 해당하는 특정 영역을 로컬라이즈합니다.
그런 다음 영역 클러스터링 기술을 사용하여 동일한 클래스 내에서 이상값을 식별하고 제거합니다.
또한 전체 이미지와 해당 영역 간에 반대되는 예측을 나타내는 태그를 필터링하여 더 깨끗하고 정확한 주석을 보장합니다.
Model:
Tag2Text [10]는 원본 이미지 인코더와 함께 경량 인식 디코더 [18]를 사용하여 이미지 태깅과 캡션을 통합하여 우수한 이미지 태깅 기능을 입증했습니다.
그러나 Tag2Text의 효과는 고정 및 미리 정의된 카테고리를 인식하는 데 제한적입니다.
반면, RAM은 시맨틱 정보를 레이블 쿼리에 통합하여 이전에 볼 수 없었던 카테고리로 일반화할 수 있습니다.
이러한 모델 설계를 통해 RAM은 모든 시각적 데이터 세트의 인식 기능을 강화하여 다양한 애플리케이션에 대한 잠재력을 강조할 수 있습니다.
대규모 고품질 image-tag-text 데이터와 캡션에 태깅을 시너지 효과적으로 통합하여 강력한 recognize anything model (RAM)을 개발합니다.
RAM은 이미지 태깅의 새로운 패러다임을 나타내며, 주석이 없는 노이즈가 많은 데이터로 학습된 일반 모델이 fully supervised 모델을 능가할 수 있음을 보여줍니다.
RAM의 장점은 다음과 같이 요약됩니다:
• 강력하고 일반적.
RAM은 그림 2와 같이 강력한 제로 샷 일반화를 통해 탁월한 이미지 태깅 기능을 제공합니다;
• 재현 가능하고 저렴.
RAM은 오픈 소스 및 주석이 없는 데이터 세트로 낮은 재현 비용이 필요합니다.
또한 가장 강력한 버전의 RAM은 3일 동안 8개의 A100 GPU만 학습하면 됩니다;
• 유연하고 다재다능.
RAM은 다양한 애플리케이션 시나리오에 맞춰 놀라운 유연성을 제공합니다.
특정 클래스를 선택하면 RAM을 직접 배포하여 특정 태깅 요구 사항을 해결할 수 있습니다.
또한 RAM은 로컬라이제이션 모델(Grounding DINO 및 SAM)과 결합하면 시각적 의미 분석을 위한 강력하고 일반적인 파이프라인을 형성합니다.
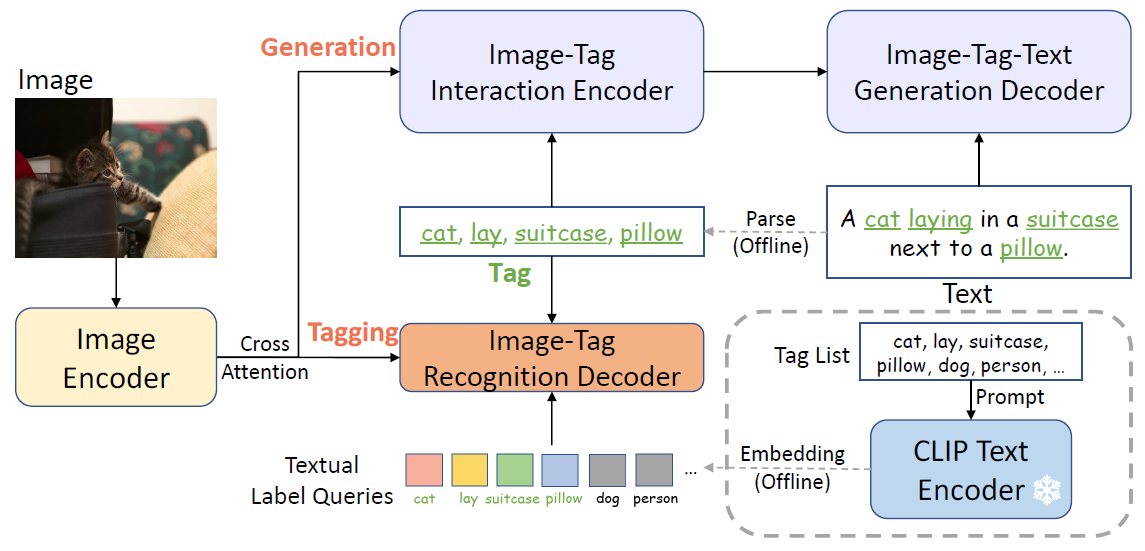
2. Recognize Anything Model
2.1. Model Architecture
그림 3과 같이 텍스트 시맨틱 구문 분석을 통해 이미지 태그를 추출하여 값비싼 수동 주석 없이 대규모 태그를 제공합니다.
RAM의 전반적인 아키텍처는 세 가지 주요 모듈로 구성된 Tag2Text [10]의 아키텍처와 유사합니다: 태깅을 위한 이미지 태그 인식 디코더 [18]와 캡션을 위한 텍스트 생성 인코더-디코더에 이어 피쳐 추출을 위한 이미지 인코더.
이미지 피쳐는 이미지-태그 상호 작용 인코더 및 인식 디코더의 크로스-어텐션 레이어에 의해 태그와 상호 작용합니다.
학습 단계에서는 인식 헤드가 텍스트에서 구문 분석된 태그를 예측하는 방법을 학습하고, 추론 단계에서는 이미지 캡션에 대한 보다 명시적인 시맨틱 가이던스를 제공하는 태그를 예측하여 image-to-tags 브리지 역할을 합니다.
Tag2Text [10]와 비교했을 때 RAM의 모델 설계의 핵심 발전은 개방형 어휘 인식의 도입입니다.
Tag2Text는 학습 중에 본 범주만 인식할 수 있는 반면, RAM은 모든 범주를 인식할 수 있습니다.
2.2. Open-Vocabulary Recognition
Textual Label Queries.
[23, 28]에서 영감을 받은 중추적인 개선 사항은 인식 디코더의 레이블 쿼리에 시맨틱 정보를 통합하여 학습 단계에서 이전에 볼 수 없었던 범주로 일반화하는 데 있습니다.
이를 위해 기성 텍스트 인코더를 활용하여 태그 목록에서 개별 태그를 인코딩하여 결과적으로 시맨틱적으로 풍부한 컨텍스트를 가진 텍스트 레이블 쿼리를 제공합니다.
반면, 원래 인식 디코드 [10, 18]에 사용된 레이블 쿼리는 랜덤으로 학습할 수 있는 임베딩으로, 보이지 않는 범주와의 의미 관계가 없기 때문에 미리 정의된 표시 범주로 제한됩니다.
Implementation Details.
우리는 비전 언어 [10]와 태깅 도메인 [18] 모두에서 나이브한 ViT보다 더 나은 성능을 보여주었기 때문에 Swin-transformer [19]를 이미지 인코더로 채택했습니다.
텍스트 생성에 사용되는 인코더-디코더는 12-레이어 트랜스포머이며 태그 인식 디코더는 2-레이어 트랜스포머입니다.
우리는 CLIP [22]의 기성 텍스트 인코더를 활용하고 프롬프트 앙상블링 [22]을 수행하여 텍스트 레이블 쿼리를 얻습니다.
또한 이미지 피쳐를 distill하기 위해 CLIP 이미지 인코더를 채택하여 이미지-텍스트 피쳐 정렬을 통해 보이지 않는 카테고리에 대한 모델의 인식 능력을 더욱 향상시킵니다.
2.3. Model Efficiency
Training Phase.
RAM은 224개의 해상도로 대규모 데이터 세트에 대해 사전 학습되고 작고 고품질 데이터 세트를 사용하여 384개의 해상도로 파인튜닝됩니다.
경험적 증거에 따르면 RAM은 종종 최소 수의 에포크(일반적으로 5 에포크 미만) 이후에 수렴을 통해 빠르게 수렴하는 것으로 나타났습니다.
이러한 가속 수렴은 제한된 계산 리소스로 RAM의 재현성을 향상시킵니다.
예를 들어, 400만 개의 이미지로 사전 학습된 RAM 버전은 1일의 계산이 필요하며, 1,400만 개의 이미지로 사전 학습된 RAM의 가장 강력한 버전은 8개의 A100 GPU에서 3일의 계산만 필요합니다.
Inference Phase.
경량 이미지-태그 인식 디코더는 이미지 태깅에 대한 RAM의 추론 효율성을 효과적으로 보장합니다.
또한 인식 디코더에서 셀프-어텐션 레이어를 제거하여 효율성을 더욱 향상시킬 뿐만 아니라 레이블 쿼리 간의 잠재적 간섭을 우회합니다.
따라서 RAM은 고정된 카테고리와 수량 대신 자동으로 인식하고자 하는 모든 카테고리와 수량에 대한 레이블 쿼리를 사용자 지정할 수 있어 다양한 시각적 작업과 데이터 세트에 걸쳐 그 유용성을 향상시킵니다.
3. Data
3.1. Label System
이 작업은 라벨 시스템 공식화를 위한 세 가지 지침 원칙을 채택합니다:
1) 이미지-텍스트 쌍에 자주 표시되는 태그는 이미지 설명에서 표현의 중요성으로 인해 더 가치가 높습니다.
2) 태그에는 다양한 도메인과 컨텍스트가 표현되어야 합니다.
태그의 개념에는 다양한 소스의 객체, 장면, 속성 및 동작이 포함되므로 복잡하고 보이지 않는 시나리오에 대한 모델 일반화에 도움이 됩니다.
3) 태그의 양은 중간 정도여야 합니다.
과도한 태그 번호는 주석 비용이 많이 들 수 있습니다.
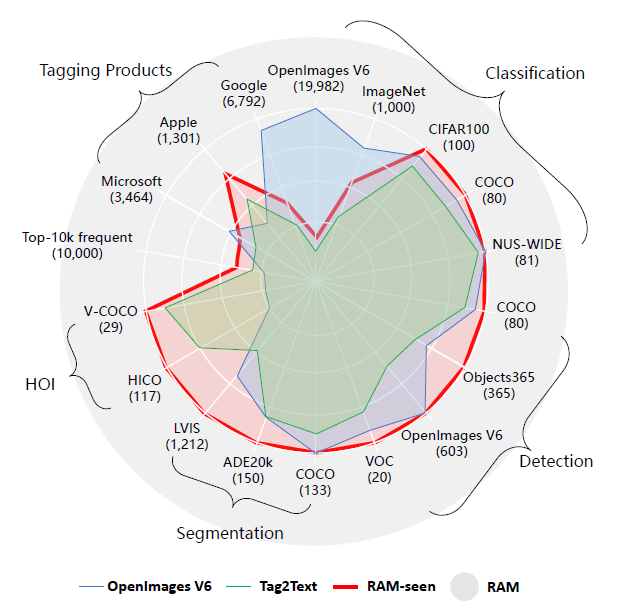
처음에는 약간의 수정이 있는 SceneGraphParser [25]를 활용하여 사전 학습 데이터 세트에서 1,400만 개의 문장을 태그로 구문 분석합니다.
그런 다음 가장 자주 발생하는 상위 10,000개의 태그에서 태그를 손으로 선택합니다.
그림 4에 나와 있는 것처럼 분류, 감지 및 세그멘테이션을 위해 수많은 인기 데이터 세트의 태그를 의도적으로 커버합니다.
대부분은 완전히 커버되지만, 비정상적인 태그 존재로 인해 ImageNet과 OpenImages V6는 예외입니다.
또한 오픈 소스 이미지를 사용하여 public API [2, 3, 1]를 통해 얻은 주요 태그 제품의 태그를 부분적으로 커버합니다.
따라서 RAM은 최대 649개의 고정 태그를 인식할 수 있으며, 이는 Tag2Text [10]보다 훨씬 많으며 더 높은 비율의 가치 있는 태그를 포함합니다.
중복성을 줄이기 위해 수동 검사, WordNet [7] 참조, 태그 번역 및 병합 등 다양한 방법론을 통해 동의어를 수집했습니다.
동일한 동의어 그룹 내의 태그에는 동일한 태그 ID가 할당되어 레이블 시스템에 4585개의 태그 ID가 할당됩니다.
3.2. Datasets
BLIP [15] 및 Tag2Text [10]와 유사하게 널리 사용되는 오픈 소스 데이터 세트에 대해 모델을 사전 학습합니다.
400만 개(400M) 이미지와 1,400만 개(14M) 이미지 설정이 채택됩니다.
4M 설정에는 사람이 주석을 단 두 개의 데이터 세트인 COCO [16](113만 개의 이미지, 557만 개의 캡션)와 Visual Genome [13] (101만 개의 이미지, 82만 개의 캡션)과 두 개의 대규모 웹 기반 데이터 세트인 개념 캡션 [6] (3M 이미지, 3M 캡션) 및 SBU 캡션 [21] (849만 개의 이미지, 849만 개의 캡션)이 포함됩니다.
14M 설정은 4M을 기반으로 하며, 개념 1,200만 개 [6](10M 이미지, 10M 캡션)가 추가됩니다.
3.3. Data Engine
주로 인터넷에서 크롤링되는 학습 데이터 세트의 오픈 소스 특성을 고려할 때, 우리는 무시할 수 없는 양의 누락 및 잘못된 레이블에 직면하게 됩니다.
이를 완화하기 위해 자동 데이터 엔진을 설계하여 추가 태그를 생성하고 잘못된 태그를 정리합니다.
Generation.
우리의 초기 단계는 Tag2Text [10]에서 사용된 접근 방식과 유사하게 이러한 캡션에서 구문 분석된 캡션과 태그를 사용하여 기본 모델을 학습하는 것입니다.
그런 다음 이 기본 모델을 활용하여 캡션과 태그를 모두 보완하여 각각 생성 및 태그 기능을 활용합니다.
원래 캡션과 태그는 생성된 캡션, 해당 구문 분석된 태그, 생성된 태그와 함께 병합되어 임시 데이터 세트를 구성합니다.
이 단계는 4M 이미지 데이터 세트의 태그 수를 1,200만 개에서 3,980만 개로 크게 확장합니다.
Cleaning.
잘못된 태그 문제를 해결하기 위해 먼저 모든 이미지 내에서 특정 카테고리에 해당하는 영역을 식별하고 자르기 위해 Grounding-Dino [29]를 사용합니다.
그런 다음 K-Means++ [4]를 기반으로 이 카테고리에서 영역을 클러스터링하고 이상값 10%와 관련된 태그를 제거합니다.
동시에 베이스라인 모델을 사용하여 이 특정 카테고리를 예측하지 않고 태그를 제거합니다.
동기는 전체 이미지가 아닌 영역을 예측함으로써 태깅 모델의 정밀도를 향상시킬 수 있다는 것입니다.
4. Experiment
4.1. Experiemental Setting
Test Benchmarks.
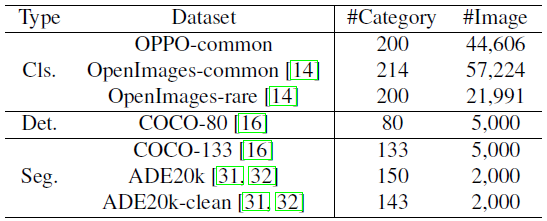
표 1에 요약된 대로 분류, 감지 및 세그멘테이션을 포함한 다양한 컴퓨터 비전 작업에 걸쳐 다양한 인기 벤치마크 데이터 세트에 대한 모델의 종합적인 평가를 수행했으며, 분류를 위해 9605개의 카테고리가 포함된 OpenImages V6 [14]를 채택했습니다.
그러나 OpenImages 데이터 세트 내에서 레이블이 누락되고 주석이 올바르지 않은 문제로 인해 두 개의 고품질 하위 집합을 큐레이팅했습니다: 주석이 잘 달린 214개의 공통 카테고리로 구성된 OpenImagescommon과 오픈셋 실험을 위한 라벨 시스템에 포함되지 않은 200개의 카테고리로 구성된 OpenImages-rare.
또한 더 나은 제로 샷 평가를 위해 높은 주석 품질을 나타내는 OPPO-common이라는 내부 테스트 세트를 사용했습니다.
탐지 및 세그멘테이션 데이터 세트의 경우 널리 알려진 COCO [16] 및 ADE20k [31, 32] 데이터 세트를 선택했습니다.
이러한 데이터 세트에서는 바운딩 박스와 마스크를 무시하고 이미지 레벨의 태깅 ground truth로서의 시맨틱 레이블에만 초점을 맞췄습니다.
ADE20k에는 "buffet"과 같이 주류 개념에서 벗어난 매우 작은 ground truth 주석과 모호한 범주가 많이 포함되어 있다는 점에 유의하는 것이 중요합니다.
따라서 몇 가지 작은 타겟과 모호한 범주를 제거하여 ADE20k-clean이라는 ADE20k의 하위 집합을 만들었습니다.
Evaluation Metrics.
모델의 성능을 평가하기 위해 다양한 평가 지표를 사용했습니다.
Mean Average Precision (mAP)는 ablation 실험 및 다른 분류 모델과의 비교 결과를 보고하는 데 사용되었습니다.
mAP를 사용할 수 없는 모델의 경우 Precision/Recall 지표를 활용하고 평가 전반에 걸쳐 비교 가능성을 보장하기 위해 다양한 모델의 임계값을 수동으로 조정했습니다.
4.2. Comparison with SOTA Models
Comparison with Multi-Label Classification Models.
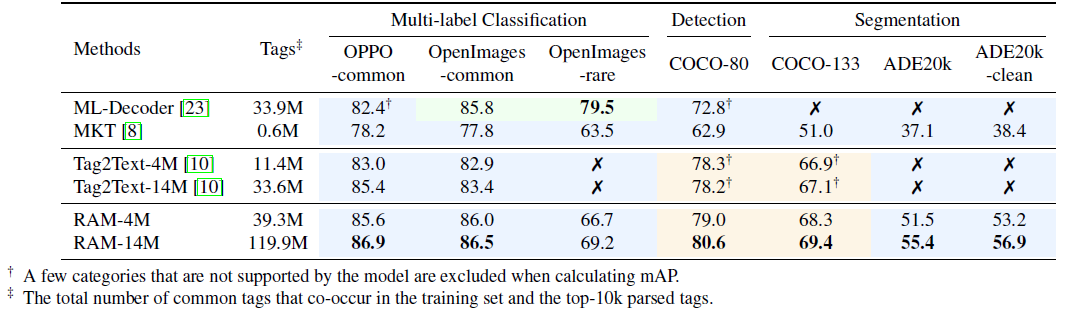
표 2와 같이 멀티 레이블 분류에서 RAM을 SOTA 모델과 비교합니다.
일반적으로 일반 모델은 일반적으로 특정 도메인에 대한 전문 지식이 부족한 반면, expert 모델은 전문 분야를 넘어 일반화하는 데 어려움을 겪습니다.
특히, supervised expert 모델인 ML-Decoder [23]는 지정된 전문 영역인 OpenImages에서 우수하지만 다른 도메인과 보이지 않는 범주로 일반화하는 데 어려움을 겪고 있습니다.
MKT [8]는 CLIP에서 지식을 전달하여 태깅을 하는 일반주의 모델이지만 모든 도메인에서 만족스러운 정확도를 달성하지는 못했습니다.
Tag2Text [10]은 제로 샷 태깅에서는 강력하지만 오픈셋 시나리오를 처리하는 기능이 부족합니다.
RAM은 인상적인 태깅 능력을 보이며 인상적인 정확도와 광범위한 커버리지를 보여줍니다.
특히 주목할 만한 점은 OpenImages 공통 데이터 세트에서 ML-Decoder를 능가하는 RAM-4M의 성능입니다.
ML-Decoder는 OpenImages의 900만 개의 주석이 달린 이미지에 의존하지만, RAM-4M은 주석이 없는 이미지-텍스트 데이터 400만 개로 구성된 학습 세트로 더 높은 정확도를 달성합니다.
이러한 개선은 400만 개의 이미지에서 파생된 3930만 개의 공통 태그를 활용하여 900만 개의 이미지에서 3390만 개의 공통 태그로만 학습된 ML-Decoder를 능가했기 때문입니다.
또한 RAM은 오픈 어휘 능력과 함께 6,400개 이상의 방대한 범위의 공통 카테고리를 활용하여 모든 공통 카테고리를 인식할 수 있습니다.
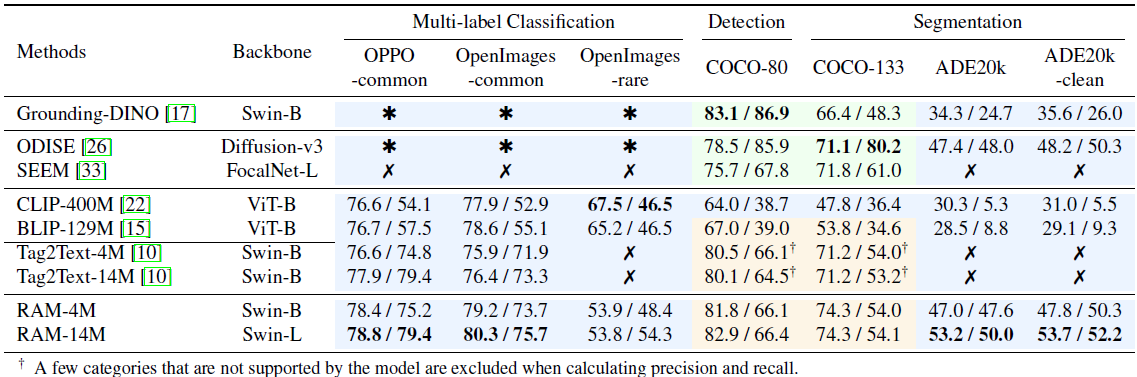
Comparison with Detection and Segmentation Models.
표 3의 비교에 따르면 supervised 탐지 및 세그멘테이션 모델은 제한된 수의 카테고리를 포함하는 COCO 데이터 세트와 같은 특정 도메인에서 우수한 성능을 발휘합니다.
그러나 이러한 모델은 더 많은 수의 카테고리를 인식하는 데 있어 어려움을 겪습니다.
한편으로는 추가 로컬라이제이션 작업을 위해 더 복잡한 네트워크와 더 큰 입력 이미지 크기가 필요하기 때문에 훨씬 더 많은 계산 오버헤드가 필요합니다.
특히 ODISE [26]는 디퓨전 모델과 큰 입력 이미지 해상도를 채택하기 때문에 추론 시간이 오래 걸립니다.
반면에 탐지 및 세그멘테이션을 위한 학습 데이터의 확장성은 제한적이어서 이러한 모델의 일반화 성능이 떨어집니다.
Grounding-DINO [17]은 일반주의 모델의 역할을 하지만 대규모 카테고리에 대해 만족스러운 성능을 달성하는 데 어려움을 겪고 있습니다.
반면 RAM은 기존 탐지 및 세그멘테이션 모델을 능가하는 인상적인 오픈 세트 기능을 보여줍니다.
RAM은 광범위한 카테고리에 걸쳐 일반화할 수 있는 기능을 보여주며, 기존 탐지 및 세그멘테이션 모델이 직면한 문제에 대한 강력한 솔루션을 제공합니다.
Compared with Vision-Language Models.
CLIP [22] 및 BLIP [15]의 오픈 세트 인식 기능에도 불구하고 이러한 모델은 정확도가 떨어집니다.
또한 이미지-텍스트 쌍에 대한 고밀도 임베딩의 코사인 유사성 계산에 의존하기 때문에 해석 가능성이 제한적입니다.
반면 RAM은 거의 모든 데이터 세트에서 20% 이상의 정확도 향상이 관찰되어 CLIP 및 BLIP를 크게 능가하는 우수한 성능을 보여줍니다.
그러나 RAM은 OpenImages-rare 데이터 세트의 경우 CLIP 및 BLIP보다 약간 더 낮은 성능을 보인다는 점에 유의할 필요가 있습니다.
이러한 불일치는 RAM에 사용되는 학습 데이터 세트가 작고 학습 중에 희귀 클래스에 대한 강조가 상대적으로 적기 때문이라고 생각합니다.
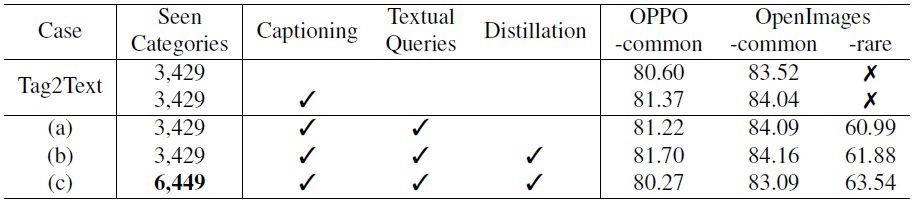
4.3. Model Ablation Study
표 4에서 우리는 Tag2Text [10]를 기반으로 RAM에 대한 다양한 모델 개선의 영향을 연구하고 다음과 같은 주요 관찰을 수행합니다.
1) 캡션과 태깅의 학습 통합은 태깅 능력을 촉진할 수 있습니다.
2) 개방형 인식 기능은 CLIP [22]의 텍스트 쿼리를 통해 달성할 수 있지만 학습에서 볼 수 있는 범주에는 거의 영향을 미치지 않습니다.
3) 라벨 시스템의 확장은 기존 범주에 미치는 영향을 최소화하며, 이는 추가 범주에 기인할 수 있습니다.
그러나 이러한 확장은 동시에 모델의 커버리지를 향상시키고 보이지 않는 범주의 개방형 집합 기능을 향상시킵니다.
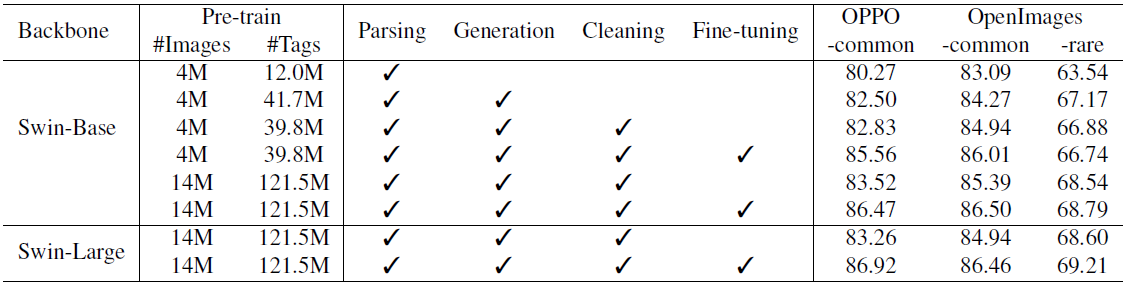
4.4. Data Engine Ablation Study
표 5에서 데이터 엔진에 대한 ablation 연구를 발표합니다.
연구 결과는 다음과 같이 요약됩니다:
1) 태그를 1,200만 개에서 4,170만 개로 더 추가하면 모든 테스트 세트에서 모델 성능이 크게 향상되어 원래 데이터 세트에서 심각한 레이블 누락 문제가 발생했음을 알 수 있습니다.
2) 일부 카테고리의 태그를 추가로 청소하면 OPPO-common 및 OpenImages 공통 테스트 세트의 성능이 약간 향상됩니다.
Grounding-Dino의 추론 속도에 제한을 받아 534개 카테고리에 대해서만 cleaning 프로세스를 수행합니다.
3) 학습 이미지를 4M에서 14M으로 확장하면 모든 테스트 세트에서 놀라운 개선 효과를 얻을 수 있습니다.
4) 더 큰 백본 네트워크를 사용하면 OpenImages 희귀도 약간 개선되고 공통 카테고리에서 성능이 약간 저하됩니다.
이러한 현상은 하이퍼 파라미터 검색에 사용할 수 있는 리소스가 부족하기 때문이라고 생각합니다.
5) COCO 캡션 데이터 세트 [16]에서 구문 분석된 태그로 파인튜닝하면 OPPO-common 및 OpenImages 공통 테스트 세트에서 놀라운 성능 향상을 보여줍니다.
COCO 캡션 데이터 세트는 각 이미지에 대해 5개의 설명 문장을 제공하며, 전체 태그 레이블 세트에 근접한 포괄적인 설명을 제공합니다.
5. Conclusion
이미지 태깅을 위해 설계된 강력한 파운데이션 모델인 Recognize Anything Model (RAM)을 제시하며, 이는 이 분야의 새로운 패러다임을 예고합니다.
RAM은 모든 카테고리를 높은 정확도로 인식하는 제로 샷 능력을 입증하여 fully supervised 모델과 CLIP 및 BLIP와 같은 기존 일반론적 접근 방식의 성능을 모두 능가합니다.
RAM은 컴퓨터 비전 분야의 대규모 모델에 상당한 발전을 이루었으며, 시각적 작업이나 데이터 세트의 인식 기능을 강화할 수 있는 잠재력을 가지고 있습니다.
RAM을 더욱 개선할 여지는 여전히 남아 있습니다.
예를 들어, 학습 데이터 세트를 1,400만 개의 이미지 이상으로 확장하여 다양한 도메인, 여러 라운드의 데이터 엔진을 더 잘 커버하고 백본 매개변수를 늘려 모델 용량을 향상시킬 수 있습니다.
Limitations.
CLIP과 유사하게 현재 버전의 RAM은 일반적인 객체와 장면을 효율적으로 인식하지만 객체 카운팅과 같은 추상적인 작업에는 어려움을 겪고 있습니다.
또한 제로샷 RAM의 성능은 자동차 모델을 구분하거나 특정 꽃 또는 새 종을 식별하는 등 세분화된 분류에서 작업별 모델에 비해 뒤처집니다.
RAM은 오픈 소스 데이터 세트에 대해 학습되어 있으며 잠재적으로 데이터 세트 편향을 반영할 수 있다는 점도 주목할 만합니다.