2025. 3. 11. 11:23ㆍ3D Vision/Urban Scene Reconstruction
Grid-guided Neural Radiance Fields for Large Urban Scenes
Linning Xu, Yuanbo Xiangli, Sida Peng, Xingang Pan, Nanxuan Zhao, Christian Theobalt, Bo Dai, Dahua Lin
Abstract
순수 MLP 기반 뉴럴 래디언스 필드 (NeRF 기반 방법)는 모델 용량이 제한되어 대규모 장면에서 블러한 렌더링으로 인해 종종 과소적합 문제를 겪습니다.
최근의 접근 방식은 장면을 지리적으로 나누고 여러 하위 NeRF를 채택하여 각 영역을 개별적으로 모델링할 것을 제안합니다, 이는 장면이 확장됨에 따라 학습 비용과 하위 NeRF의 수가 선형적으로 증가하게 만듭니다.
대안적인 해결책은 피쳐 그리드 표현을 사용하는 것입니다, 이 표현은 계산 효율성이 뛰어나고 그리드 해상도가 향상된 큰 장면으로 자연스럽게 확장될 수 있습니다.
그러나 피쳐 그리드는 제약이 적고 종종 최적의 솔루션에 도달하여 렌더링 시 노이즈 아티팩트를 생성하는 경향이 있으며, 특히 복잡한 지오메트리와 텍스처를 가진 영역에서 더욱 그렇습니다.
이 연구에서는 계산 효율성을 유지하면서 대규모 도시 장면에서 고충실도 렌더링을 실현하는 새로운 프레임워크를 제시합니다.
우리는 장면을 coarse하게 캡처하기 위해 컴팩트한 멀티-해상도 그라운드 피쳐 평면 표현을 사용하고, 공동 학습 방식으로 렌더링하기 위해 다른 NeRF 브랜치를 통한 위치 인코딩 입력으로 보완할 것을 제안합니다.
우리는 이러한 통합이 두 가지 대체 솔루션의 장점을 활용할 수 있음을 보여줍니다: 경량 NeRF는 피쳐 그리드 표현의 가이던스에 따라 사진사실적인 새로운 뷰를 세밀한 디테일로 렌더링하기에 충분합니다, 또한, 공동으로 최적화된 그라운드 피쳐 평면은 추가적인 개선을 통해 더 정확하고 컴팩트한 피쳐 공간을 형성하고 훨씬 더 자연스러운 렌더링 결과를 출력할 수 있습니다.
1. Introduction
대형 도시 장면 모델링은 최근 neural radiance fields (NeRF)의 등장으로 많은 연구 관심을 받고 있습니다 [3, 34, 56, 59, 62, 64].
이러한 모델링은 자율주행차 시뮬레이션 [23, 39, 67], 항공 측량 [6, 15], 임바디드 AI [35, 61] 등 다양한 실용적인 응용을 가능하게 합니다.
NeRF 기반 방법은 객체 수준 장면에서 인상적인 결과를 보여주었으며, MLP 아키텍처와 전역적으로 공유된 위치 인코딩을 통해 고주파의 세부 사항 덕분에 연속성 prior가 향상되었습니다.
그러나 크고 복잡한 장면을 모델링하는 데 실패하는 경우가 많습니다.
이러한 방법들은 제한된 모델 용량으로 인해 과소적합 문제를 겪고 있으며, 세부 사항 없이 블러한 렌더링만 생성합니다 [56,62,64].
BlockNeRF [58]과 MegaNeRF [62]는 도시 장면을 지리적으로 나누고 각 지역에 서로 다른 하위 NeRF를 할당하여 병렬로 학습할 것을 제안합니다.
그 결과, 타겟 장면의 규모와 복잡성이 증가하면 필연적으로 하위 NeRF의 수와 각 하위 NeRF가 각 지역의 모든 세부 사항을 완전히 포착하는 데 필요한 용량 간의 균형이 깨지게 됩니다.
또 다른 그리드 기반 표현 스트림은 피쳐 그리드를 사용하여 타겟 장면을 나타냅니다 [27, 27, 30, 36, 55, 68, 69].
이러한 방법들은 일반적으로 렌더링 중에 훨씬 빠르고 장면이 확장될 때 더 효율적입니다.
그러나 피쳐 그리드의 각 셀이 로컬 인코딩 방식으로 개별적으로 최적화되어 있기 때문에, 결과적으로 생성된 피쳐 그리드는 NeRF 기반 방법에 비해 장면 전반에 걸쳐 덜 연속적인 경향이 있습니다.
더 많은 유연성이 직관적으로 fine 디테일을 포착하는 데 도움이 되지만, 고유한 연속성이 부족하기 때문에 그림 1에서 보여준 것처럼 노이즈 아티팩트가 있는 최적이 아닌 솔루션에 취약합니다.

암시적인 신경 표현을 사용하여 대규모 도시 장면을 효과적으로 재구성하기 위해, 본 연구에서는 그리드 기반과 NeRF 기반 접근법을 공동 학습 방식 하에 통합한 통합 장면 표현을 사용하는 두 가지 브랜치 모델 아키텍처를 제안합니다.
우리의 핵심 인사이트는 이 두 가지 유형의 표현이 서로 보완적으로 사용될 수 있다는 것입니다: 피쳐 그리드는 명시적이고 독립적으로 학습된 피쳐로 로컬 장면 콘텐츠를 쉽게 맞출 수 있지만, NeRF는 모든 3D 좌표 입력에 걸쳐 공유 가능한 MLP 가중치를 통해 학습된 장면 콘텐츠에 내재된 전역 연속성을 도입합니다.
NeRF는 위치 인코딩을 푸리에 피쳐로 하여 세부 사항의 대역폭과 일치시킴으로써 고주파 장면 세부 사항을 캡처하도록 장려할 수 있습니다.
그러나 피쳐 그리드 표현과 달리 NeRF는 대형 장면 콘텐츠를 전역적으로 공유되는 잠재 좌표 공간으로 압축하는 데 효과적이지 않습니다.
구체적으로, 먼저 학습 전 단계에서 타겟 장면을 피쳐 그리드로 모델링하여 장면의 지오메트리와 외관을 대략적으로 포착합니다.
그런 다음 coarse 피쳐 그리드를 사용하여 1) NeRF의 포인트 샘플링을 가이드하여 장면 표면 주위에 집중되도록 하고, 2) NeRF의 위치 인코딩에 장면 지오메트리와 샘플링된 위치의 외관에 대한 추가 피쳐를 제공합니다.
이러한 가이던스에 따라 NeRF는 급격히 압축된 샘플링 공간에서 더 fine한 디테일을 효과적이고 효율적으로 포착할 수 있습니다.
또한, NeRF에 coarse 수준의 지오메트리와 외관 정보가 명시적으로 제공되므로, 가벼운 MLP는 전역 좌표에서 부피 밀도와 색상 값으로의 매핑을 학습하는 데 충분합니다.
coarse 피쳐 그리드는 두 번째 공동 학습 단계에서 NeRF 브랜치의 그래디언트로 더욱 최적화되며, 이를 통해 독립적으로 적용할 때 더 정확하고 자연스러운 렌더링 결과를 생성하도록 정규화됩니다.
메모리 사용량을 더욱 줄이고 대규모 도시 장면을 위한 신뢰할 수 있는 피쳐 그리드를 학습하기 위해, 우리는 3D 피쳐 그리드의 컴팩트 분해를 채택하여 표현 용량을 잃지 않고 근사화합니다.
도시 레이아웃과 같은 필수 시맨틱이 주로 그라운드 (즉, xy 평면)에 분포한다는 관찰을 바탕으로, 우리는 3D 피쳐 그리드를 장면을 가로지르는 2D 그라운드 피쳐 평면과 z축을 따라 수직으로 공유된 피쳐 벡터로 분해할 것을 제안합니다.
이점은 다양합니다:
1) 메모리가 O(N^3)에서 O(N^2)로 축소됩니다.
2) 학습된 피쳐 그리드는 매우 간결한 그라운드 피쳐 계획으로 분리되어 명확하고 유익한 장면 레이아웃을 제공하도록 강제됩니다.
광범위한 실험을 통해 통합 모델과 장면 표현의 효과가 입증되었습니다.
실제로 새로운 뷰를 렌더링할 때, 사용자는 더 빠른 렌더링 속도로 그리드 브랜치를 사용할 수 있으며, NeRF 브랜치는 더 고주파의 디테일과 공간적 부드러움을 제공하지만 상대적으로 느린 렌더링의 대가를 치르게 됩니다.
2. Related Works and Background
Large-scale Scene Reconstruction and Rendering.
이것은 컴퓨터 비전과 그래픽 분야에서 오랜 문제이며, 많은 초기 연구 [1, 17, 24, 43, 48, 52, 72]가 이 문제를 해결하려고 시도했습니다.
대부분의 이러한 방법은 3단계 파이프라인을 채택합니다.
그들은 먼저 2D 이미지에서 중요한 포인트 [19, 29]을 감지하고 포인트 설명자 [4, 47]를 구성합니다.
그런 다음 포인트 설명자를 이미지 간에 매칭하여 카메라 포즈 추정 및 3D 포인트 삼각 측량에 사용되는 2D 대응을 얻습니다.
마지막으로, 카메라 포즈와 3D 포인트는 번들 조정을 통해 투영된 포인트와 이미지 포인트 간의 차이를 최소화하도록 공동으로 최적화됩니다 [18, 60].
이러한 방법들은 대규모 장면에서 인상적인 재구성 성능을 보여주었습니다.
[28, 50]은 재구성 결과를 활용하여 장면의 자유 뷰포인트 탐색을 달성합니다.
그러나 재구성된 장면에는 종종 아티팩트나 구멍이 있어 렌더링 품질에 한계가 있습니다.
최근 방법 [26, 31, 33]은 이미지 합성의 결과를 개선하기 위해 딥러닝 기법을 활용합니다.
[33]은 복구된 포인트 클라우드를 깊은 버퍼로 래스터화한 다음 2D 컨볼루션 신경망을 사용하여 2D 이미지로 해석합니다.
최근에는 [31]이 생성 잠재 최적화 기법을 활용하여 사진 컬렉션에서 래디언스 필드를 재구성하여 사진사실적인 렌더링 결과를 얻을 수 있게 되었습니다.
[14, 51]은 각각 장면 생성 및 정적 동적 분리 작업에 대해 우리와 유사한 그라운드 평면 표현을 채택했지만, 적용 가능한 장면의 규모와 렌더링 품질은 여전히 제한적입니다.
Volumetric Scene Representations.
좌표 기반 다층 퍼셉트론은 3D 형상 모델링 [7, 10, 32, 40]과 새로운 뷰 합성 [2, 3, 34, 38]에서 인기 있는 표현이 되었습니다.
고해상도 3D 형상을 표현하기 위해 일부 방법은 연속적인 3D 좌표를 입력으로 받아 타겟 값을 예측하는 MLP 네트워크를 채택합니다 [13, 32, 40].
[11, 12, 42]는 강력한 장면 prior 학습을 위해 컨볼루션 신경망을 도입하여 좌표 기반 표현이 더 큰 장면을 처리할 수 있도록 합니다.
새로운 뷰 합성 분야에서 NeRF [34]는 3D 장면을 밀도 및 색상 필드로 표현하며, 볼륨 렌더링 기법을 통해 이미지에서 이 표현을 최적화합니다.
[20,27,46,69]는 렌더링 프로세스를 가속화하기 위해 효율적인 데이터 구조로 NeRF를 확장합니다.
[8,37,49,66]은 NeRF를 생성 모델과 결합하여 3D 인식 이미지 생성을 달성합니다.
[25, 41, 44]는 NeRF에 모션 필드를 추가하여 동적 장면을 처리할 수 있도록 합니다.
NeRF Scale-up.
앞서 언급한 NeRF 접근 방식은 주로 제한된 규모의 장면을 고려하지만, 도시와 같은 대규모 장면을 처리하기 위해 NeRF를 확장하면 더 넓은 응용이 가능할 것입니다.
[27, 62, 65]는 대규모 장면에서 NeRF의 렌더링 품질을 향상시키기 위해 노력해 왔습니다.
피쳐 그리드 방법 [22,27]은 미리 정의된 학습 가능한 피쳐 벡터 테이블에서 조회하여 입력 좌표를 고차원 공간으로 매핑하여 신경망의 근사 능력을 향상시킵니다.
PointNeRF [65]는 포인트 클라우드에서 래디언스 필드를 퇴보시키고 실내 장면의 고품질 렌더링을 달성합니다.
BungeeNeRF [64]는 장면 콘텐츠를 효율적으로 모델링하고 렌더링 품질을 향상시키는 멀티 스케일 표현을 설계합니다.
[56, 62]는 장면을 NeRF 네트워크로 개별적으로 표현되는 여러 공간 영역으로 분해합니다.
큰 장면을 처리할 때 또 다른 중요한 문제는 학습 시간을 줄이는 방법입니다.
이미지 인코더 [63,71], 오토-디코더 [16,45], 메타 학습 [5,57]과 같은 여러 기술이 최적화 프로세스를 개선하기 위해 데이터셋에서 네트워크를 사전 학습하는 데 사용됩니다.
[36, 53, 54, 68]은 학습 속도를 가속화하기 위해 그리드 표현을 추가로 탐구합니다.
TensoRF [9]는 3D 장면의 분해를 조사하여 장면을 간결하게 표현하고 빠른 학습을 달성할 수 있도록 합니다.
Instant-NGP [36]은 매우 빠른 렌더링을 가능하게 하는 피쳐 벡터의 멀티 해상도 해시 테이블을 채택합니다.
그러나 이 두 가지 방법 모두 큰 장면에 적용될 때 노이즈가 많은 피쳐 그리드로 인해 어려움을 겪는다는 것을 알 수 있습니다.
3. Grid-guided Neural Radiance Fields
NeRF 기반 표현은 포인트 좌표의 positional encoding (PE)을 8-레이어 MLP에 전달하여 포인트 밀도와 색상을 얻는다는 점을 기억하세요 [34].
이러한 모델은 PE 임베딩을 입력으로 사용하여 전체 장면 콘텐츠가 MLP 가중치로 인코딩되기 때문에 매우 컴팩트하지만, 모델 용량에 따라 확장하는 데 어려움을 겪습니다.
대조적으로, 그리드 기반 표현은 장면을 피쳐 그리드로 인코딩하며, 이는 직관적으로 실제 3D 공간과 일치하는 그리드 해상도를 가진 3D 복셀 그리드로 생각할 수 있습니다.
각 복셀은 정점에 피쳐 벡터를 저장한 다음 보간하여 쿼리 포인트 좌표에서 피쳐 값을 추출하고 작은 네트워크를 통해 포인트 밀도와 색상으로 변환할 수 있습니다.
피처 그리드는 종종 고차원 텐서로 구현되기 때문에, 더 컴팩트한 피처 그리드 표현을 얻기 위해 다양한 인수분해 방법을 적용할 수도 있습니다 [9].
대규모 도시 장면을 효과적으로 표현하기 위해 NeRF 기반 방법과 그리드 기반 방법의 전문성을 결합한 그리드 가이드 뉴럴 래디언스 필드를 제안합니다.
그리드 피쳐는 멀티 해상도 그라운드 피쳐 평면을 통해 가능한 한 많은 로컬 정보를 신뢰성 있게 캡처하도록 강제됩니다.
그런 다음 위치 인코딩된 좌표 정보가 누락된 고주파 세부 정보를 포착하여 고품질 렌더링을 생성하도록 합니다.
장면을 여러 해상도로 캡처하는 피쳐 그리드의 대략적인 구성을 통해 밀도 필드는 NeRF의 샘플링 절차를 가이드하는 데에도 사용됩니다.
NeRF 브랜치를 학습할 때 그리드 피쳐는 두 브랜치의 재구성 loss와 함께 공동으로 최적화되고 supervise됩니다.

그림 2는 우리 시스템의 전체 파이프라인을 보여줍니다.
섹션 3.1에서는 멀티 해상도 그라운드 피쳐 평면 표현의 사전 학습을 설명하고, 섹션 3.2에서는 그림 2의 NeRF 브랜치에 해당하는 뉴럴 래디언스 필드의 그리드 가이드 학습을 소개합니다; 마지막으로, 섹션 3.3에서는 NeRF 브랜치가 그리드 브랜치의 사전 학습된 그리드 피쳐를 어떻게 개선하는지 자세히 설명합니다.
3.1. Multi-resolution Feature Grid Pre-train
그림 1은 대규모 도시 장면의 대표적인 시나리오를 보여줍니다.
대형 도시 장면들이 주로 xy 평면에서 그라운드화된다는 사실에서 영감을 받아, 우리는 멀티 해상도 평면-벡터 피쳐 공간을 구성하여 주요 그라운드 피쳐 평면으로 타겟 대형 도시 장면을 표현할 것을 제안합니다.
그라운드 평면 압축을 적용하면 전체 3D 그리드에서 얻은 것에 비해 더 많은 정보를 제공하는 피쳐 평면을 얻을 수 있습니다.
이 간결한 표현은 특히 도시 장면 시나리오에 적합하며 희소 뷰 학습 데이터에 대해 견고하게 작동합니다.
다양한 작업(예: concatenation, 외적)을 고려하여 2D 그라운드 피쳐 평면에서 3D 정보를 복구할 수 있습니다.
외적 연산은 [9]에서 저차원 근사를 사용한 텐서 분해의 관점에서 채택되었으며, 이는 고품질을 유지하면서 더 압축된 메모리 사용량을 달성합니다.
부피 밀도 σ ∈ R+와 뷰 의존 색상 c ∈ R^3 그리드 평면은 외관에만 영향을 미치는 더 많은 환경적 영향을 포착하기 위해 별도로 학습됩니다.
공식적으로 그리드 기반 래디언스 필드는 다음과 같이 작성됩니다: σ,c = F_σ(G_σ(X)), F_c(G_c(X), PE(d)) 여기서 G_σ(X) ∈ R^(R_σ), G_c(X) ∈ R^(R_c)는 위치 X ∈ R^3의 두 그리드-평면에서 추출된 보간 피쳐 값입니다.
F_σ,F_c는 두 개의 작은 MLP로 구현된 두 개의 융합 함수로, concat된 밀도/외관 피쳐를 σ, c로 변환하고 d ∈ S^2를 뷰 방향으로 전환합니다.
여기서 PE는 [34]에서와 같이 위치 인코딩(sin(·), cos(·),..., sin(2^(L-1)(·), cos(2^(L-1)(·))을 나타냅니다.
그런 다음 그리드 브랜치는 ray를 따라 N개의 쿼리 샘플로 학습되어 [34]와 같이 볼륨 렌더링 과정을 거쳐 픽셀 색상을 예측합니다, 여기서 loss는 그림 2(a)와 같이 이 coarse 샘플링 단계에서 렌더링된 픽셀 색상과 실제 픽셀 색상 간의 총 제곱 오차입니다.
우리는 [9]의 방법을 따라 그라운드 피쳐 평면 R_σ 및 R_c의 채널별 외적 곱과 전역적으로 인코딩된 z축 피쳐 벡터를 사용하여 전체 밀도와 외관 그리드 피쳐를 근사합니다.
각 채널 r ∈ R_σ 및 R_c에 대해 해당 텐서 그리드의 피쳐는 다음과 같습니다: 여기서 v^z는 z축을 따라 벡터를 나타내고, M^xy는 xy 평면을 가로지르는 행렬을 나타내며, ◦는 외부 곱을 나타냅니다.
공유 z축 피쳐 벡터를 학습하는 제약 조건이 있는 경우, 최적화된 그라운드 피쳐 평면은 충분한 로컬 장면 콘텐츠를 인코딩하도록 권장되며, 이는 전역적으로 공유된 MLP 렌더러에 의해 이동될 수 있습니다.
특정 그리드 해상도 n에 대해 밀도와 외관 텐서 G_σ^n, G_c^n는 R_σ, R_c 피쳐 성분의 결합으로 얻어집니다:

, 여기서 ⊕는 R_σ 및 R_c 차원에서의 concat 연산을 나타냅니다.
다양한 정도의 장면 로컬 복잡성을 포착하기 위해, 우리는 G_σ ={G_σ^n}와 G_c={G_c^n}를 사용하는 멀티 해상도 피쳐 그리드를 학습합니다.
생성되는 멀티 해상도 피쳐 그리드는 장면을 설명하기 위해 다양한 세분화된 피쳐를 포함하고 있으며, 이는 객체가 다양한 스케일로 나타나는 도시 환경에 특히 적합합니다.
3.2. Grid-guided Neural Radiance Field
순수한 위치 입력으로부터 전체 장면을 추론하려면 처음부터 학습된 NeRF가 필요하며, 이는 PE에서 푸리에 주파수 대역만을 제공합니다.
지오메트리 및 텍스처 세부 사항에 대해 자연스럽게 다양한 세분화가 이루어지는 대규모 도시 장면의 경우, NeRF는 [58, 64]에서 지적한 바와 같이 저주파 함수를 학습하는 데 지속적으로 편향됩니다.
이 문제는 많은 양의 정보를 인코딩해야 하는 큰 장면에서 증폭됩니다.
이를 해결하기 위해, 우리는 NeRF의 샘플링 공간을 사전 학습된 피쳐 그리드 밀도로 압축하고, 사전 학습 단계에서 초기화된 coarse 그리드 피쳐로 NeRF의 순수 좌표 입력을 풍부하게 할 것을 제안합니다.
비록 정확도와 세분성이 제한적이지만, 사전 학습된 그리드 피쳐는 이미 장면의 근사치를 제공하여 1) NeRF의 포인트 샘플링을 가이드하고 2) 좌표 입력을 보완하는 중간 피쳐를 제공할 수 있습니다.
그림 2에서 볼 수 있듯이, NeRF는 전체 샘플 공간에 걸쳐 좌표를 매핑하는 대신, 이제 근사된 장면 표면에 집중하여 더 효율적이고 밀도가 높은 포인트 샘플링을 수행할 수 있으며, 위치 인코딩에서 고주파 푸리에 피쳐를 불러일으켜 더 세밀한 세부 사항을 복원할 수 있습니다.
한편, 샘플링된 ray의 점들은 멀티 해상도 피쳐 평면에 투영되어 이중 선형 보간을 통해 밀도와 외관 피쳐를 검색합니다.
추론된 그리드 피쳐는 NeRF 브랜치에 입력될 때 위치 인코딩에 concat됩니다.
포인트당 밀도와 색상 σ', c′는 NeRF 브랜치 네트워크 F′를 통해

로 예측됩니다.
멀티 해상도 피쳐 평면은 장면에 대한 정보를 여러 가지 세분화하여 제공함으로써 중요한 역할을 합니다, 이는 NeRF의 PE에 대한 피팅 부담을 덜어주어 장면의 세부 사항을 세밀하게 다듬는 데 집중할 수 있도록 합니다.
특히, 높은 그리드 해상도는 공간 내 각 복셀이 로컬 콘텐츠를 캡처하도록 보장할 수 있지만, 장면 전반에 걸친 세부 수준의 이질성 가능성과 상관없이 저장 비용에 따라 품질이 향상됩니다.
따라서 PE에서 몇 차원만 비용이 들고 학습 과정 전반에 걸쳐 장면에 맞게 조정할 수 있는 푸리에 피쳐로 고주파 디테일을 제공하는 것이 더 효율적입니다.
두 브랜치의 supervision과 두 단계의 학습이 필요하다는 점에 유의하세요:
(1) 랜덤으로 초기화된 피쳐 그리드는 유익한 장면 콘텐츠를 거의 제공하지 못하며, 두 가지 유형의 네트워크 입력 역할을 얽히게 할 수 있습니다.
(2) 학습 전 단계는 NeRF 브랜치가 포함된 단계보다 훨씬 빠르기 때문에 그리드 브랜치만으로 coarse 지오메트리를 안정적으로 구성하는 것이 더 효율적입니다.
(3) PE 입력을 공급할 때 복셀 그리드를 고정시키는 [53]과 달리, 우리는 나중에 NeRF 브랜치와의 결합 학습을 통해 피쳐 그리드가 더욱 정교해질 수 있음을 보여줄 것입니다.
또한 그리드 브랜치는 재구성 loss에 대한 supervise을 받기 때문에 그리드 브랜치가 캡처된 장면 정보를 계속 풍부하게 하여 PE 입력이 누락된 고주파 세부 사항에 집중할 수 있도록 합니다.
3.3. Refined Grid Feature Planes from NeRF
피쳐 그리드는 복셀 내의 점들의 피쳐 벡터를 얻기 위해 그라운드 피쳐 평면에서 이중 선형 보간에 의존한다는 점을 기억하세요.
이 메커니즘은 충분히 높은 그리드 해상도를 제공하면 상세한 재구성 결과를 얻을 수 있어 장면의 최상의 변화를 복원할 수 있습니다.
그러나 [36]에 나타난 바와 같이, 대규모 도시 장면에서는 해상도가 일치하는 그리드를 학습하는 것이 메모리 소모가 매우 클 수 있습니다.
게다가, 그리드 피쳐는 단순히 ground truth RGB에서의 재구성 loss만으로 복셀 내에서 정확한 변화를 포착할 인센티브가 부족합니다.
따라서 우리는 NeRF와 함께 피쳐 평면과 벡터를 공동으로 최적화하여 제공된 NeRF 입력으로부터 포인트별 가이던스를 통해 그리드 피쳐에 대한 supervision 신호를 향상시킵니다.
NeRF가 제공하는 또 다른 이점은 독립적으로 최적화된 그리드 피쳐에 대한 전역 정규화입니다.
그림 1과 그림 3은 그리드 기반 방법이 공간 연속성과 시맨틱 유사성에 대한 제약이 부족하여 노이즈 아티팩트를 겪는다는 것을 보여줍니다.
반대로 NeRF는 전체 장면 공간에 대해 공유 MLP를 사용합니다.
나중에 그리드 브랜치에서 해석된 렌더링된 새로운 뷰가 NeRF 브랜치와의 공동 학습 후 크게 개선될 수 있음을 보여드리겠습니다.

4. Experiments
4.1. Experimental Setup
Dataset.
우리의 주요 실험은 실제 도시 장면에서 수행됩니다.
이 세 장면은 rural rubble site [62] (Rubble), university campus (Campus), residential complexes (Residential) 등 다양한 도시 환경을 다룹니다.
카메라 포즈는 사진 측량 소프트웨어 ContextCapture에서 얻습니다.
일반 장면 데이터셋, 대체 카메라 포즈, 추가 개선 기법에 대한 추가 실험 및 결과는 부록과 웹페이지에서 확인할 수 있습니다.
Baselines and Implementations.
우리는 1) 전체 장면에 적용된 NeRF [34]; 2) 4개의 파티션이 있는 Mega-NeRF [62]; 3) 저순위 텐서 분해를 통해 피쳐 그리드의 메모리 사용량을 줄이고 대규모 장면 시나리오에 적합한 것으로 간주되는 TensoRF [9]와 우리의 접근 방식의 성능을 비교합니다.
NeRF와 Mega-NeRF의 경우, 12개의 레이어와 256개의 히든 유닛을 갖춘 더 큰 모델을 채택했습니다.
위치 인코딩의 가장 높은 빈도는 2^15로 설정되며, 4, 6, 8, 10 레이어에서 스킵 연결을 통해 NeRF 모델에 삽입됩니다.
학습 중에는 ray당 64개의 coarse 샘플과 128개의 fine 샘플을 사용하여 계층적 샘플링을 수행합니다.
모든 NeRF 모델은 Adam 옵티마이저 [21]를 사용하여 최적화되었으며, 학습 속도는 5e^-4에서 지수적으로 감소하고 배치 크기는 2048개로 150k번 반복 학습되었습니다.
TensoRF의 경우, 이전에 섹션 3.1에서 논의된 대규모 도시 장면에 대한 관찰에 따라 피쳐 그리드를 xy 평면 행렬과 z축 벡터 성분으로 분해하는 단순화된 버전을 평가했습니다.
밀도 및 외관 피쳐 그리드에는 각각 16/48개의 구성 요소가 사용됩니다.
초기 저해상도 그리드에서 128^3개의 복셀로 시작하여, 학습 중에 로그 공간에서 선형적으로 1024^3개로 그리드가 업샘플링됩니다.
각 차원의 그리드 해상도는 x, y, z 차원으로 스케일링됩니다.
128개의 히든 레이어와 ReLU 활성화로 구성된 2개의 완전 연결 레이어가 있는 작은 MLP가 색상 출력 헤드로 사용됩니다.
Adam 옵티마이저는 텐서 팩터의 경우 초기 러닝 레이트가 0.02이고 MLP 디코더의 경우 0.01로 채택되었습니다.
배치 크기는 4096입니다.
그 모델은 100k 번의 반복을 위해 학습되었습니다.
우리의 방법은 일치하는 그리드 해상도를 밀도/외관 그리드의 최고 해상도 피쳐 평면과 8/16 구성 요소로 사용하며, 다운샘플링된 ×4 해상도와 ×16 해상도에서 각각 두 개를 더 사용합니다.
그리드 브랜치의 MLP 헤드는 TensoRF와 동일합니다.
NeRF 브랜치는 스킵 레이어 없이 4 MLP 레이어를 사용합니다.
위치 인코딩의 최고 주파수도 2^15로 설정됩니다.
Adam 옵티마이저는 초기 학습률이 텐서 팩터의 경우 0.02, 배치 크기가 4096인 MLP 레이어의 경우 0.01로 채택되었습니다.
우리는 처음 10k회 반복을 위해 그리드 브랜치를 사전 학습하고, 또 다른 100k회 반복을 위해 공동 최적화를 수행하며, 두 단계 사이의 시간 비율은 대략 1:4입니다.
우리는 공동 학습에서 두 지점에 대해 가중 loss 1:1을 사용합니다.

4.2. Results Analysis
우리는 그림 3과 표 1에서 베이스라인과 우리의 방법의 성능을 정성적 및 정량적으로 보고합니다.
시각적 품질과 모든 지표에서 상당한 개선이 관찰될 수 있습니다.
우리의 방법은 순수한 MLP 기반 접근법 (NeRF 및 Mega-NeRF)보다 더 샤프한 지오메트리와 더 섬세한 세부 사항을 보여줍니다.
특히 NeRF의 용량과 스펙트럼 편향이 제한적이기 때문에 운동장의 식생과 줄무늬와 같은 지오메트리 및 색상의 급격한 변화를 모델링하는 데 항상 실패합니다.
Mega-NeRF 베이스라인에서 볼 수 있듯이 장면을 작은 영역으로 분할하는 것이 약간 도움이 되지만, 렌더링된 결과는 여전히 지나치게 매끄러워 보입니다.
반대로, 학습된 피쳐 그리드의 가이던스를 통해 NeRF의 샘플링 공간이 효과적이고 극적으로 근거리 장면 표면으로 압축됩니다.
그라운드 피쳐 평면에서 샘플링된 밀도와 외관 피쳐는 그림 3에 나타난 바와 같이 장면 내용을 명시적으로 나타냅니다.
정확도는 떨어지지만 이미 유용한 로컬 지오메트리와 텍스처를 제공하고 NeRF의 PE가 누락된 장면 세부 정보를 수집하도록 권장합니다.


Refined Ground Feature Planes.
그리드 기반 방법은 관측값이 적은 지역에서 노이즈를 피하기 위해 총 변동 loss 또는 L1 loss [9]와 같이 명시적으로 부과된 정규화를 필요로 하는 경우가 많습니다, 그렇지 않으면 그림 3에 나와 있는 것처럼 독립적으로 최적화된 그리드 피쳐가 쉽게 fuzzy하고 물결 모양으로 나타날 수 있습니다.
NeRF 브랜치와 공동으로 최적화함으로써 xy 평면 및 z축 인코딩이 지속적으로 개선되어 더 많은 로컬 세부 사항을 인코딩하면서도 노이즈가 줄어듭니다.
충실도의 급격한 향상은 그림 6에서 관찰할 수 있습니다.
피쳐 공간에서도 유사한 정교함을 관찰할 수 있습니다.
주거 장면의 1차원 밀도 평면을 예로 들어보겠습니다 (그림 4), 사전 학습된 xy 평면 피쳐 (그림 4(a))에서 타겟 도시 지역의 대략적인 바닥 배치를 이미 식별할 수 있지만, 장면에 널리 퍼져 있는 샤프한 모서리와 다양한 모양 및 색상과 같은 세부 사항은 여전히 누락되어 있어 세밀한 그리드 해상도를 채택하지 않으면 그리드로 표현하기 어렵습니다.
반면 NeRF는 포인트가 있는 장면 표면을 검색하여 그리드 피쳐 최적화를 위한 보다 정확하고 의미 있는 신호를 제공하고 로컬 최소값에서 이를 향상시킵니다.
사전 학습된 피쳐 평면에서 또 다른 눈에 띄는 아티팩트는 그리드 변동으로 인한 연속적인 영역 (예: 토지, 외관)의 노이즈로, NeRF와 공동으로 최적화한 후 크게 완화됩니다.
이는 NeRF가 장면을 연속적으로 표현하기 때문일 수 있으며, 이는 좌표 간의 더 강한 상관관계를 구성하여 피쳐 그리드에 암묵적인 정규화를 부과합니다.
결과적으로 정제된 피쳐 평면 (그림 4(b))은 콘텐츠 유사 그리드를 함께 클러스터링할 수 있는 더 깨끗한 실루엣을 가진 매끄러운 그리드 피쳐를 보여줍니다 (예: 건물, 복층, 도로).

Compact Representations.
큰 장면을 모델링하기 위해 무거운 프레임워크를 설계하는 것은 본능적이지만, 우리의 원칙은 품질을 크게 저하시키지 않으면서도 컴팩트하고 효율적으로 유지하는 것입니다.
이를 염두에 두고, 우리는 전체 3D 피쳐 그리드를 간결한 평면-벡터 표현으로 모델링했습니다.
그림 5에서 우리는 대규모 도시 장면 재구성 (PSNR: (TensoRF) 21.075 vs. (Ours) 20.915)에서 유사한 성능을 보이며, TensoRF의 VM 분해 [9]에서 학습한 2D 그라운드 평면이 우리보다 더 퍼지하고 덜 정보적인 것으로 보이며, 우리의 표현은 TensoRF (4e8)에 비해 매개변수(3e8)를 덜 사용한다는 것을 보여줍니다.
또한, 순수 복셀 기반 표현이 고품질 렌더링을 얻기 위해서는 그리드 해상도가 매우 중요하다는 점을 기억하세요, 우리의 방법은 더 이상의 업샘플링 없이 큰 장면의 사실적 렌더링을 실현합니다.
프레임워크에 세밀한 피쳐 평면을 제공하는 것은 유익하지만, NeRF와의 통합은 장면 세부 사항을 캡처하기 위해 그리드 해상도에 의존하는 것을 크게 완화합니다.
NeRF의 관점에서 볼 때, 우리는 PE로 학습된 그리드 피쳐를 취함으로써 큰 장면을 처리하기에 상대적으로 작은 MLP가 충분하며, 그림 3과 같이 확장된 NeRF와 Mega-NeRF [62]보다 우수한 결과를 달성한다는 것을 보여줍니다.
4.3. Ablations
ablation은 1) 다양한 모델 구성의 영향을 검증하기 위해 수행됩니다: 그리드 브랜치의 경우, 우리는 다양한 해상도의 단일 해상도 피쳐 그리드로 전환합니다; NeRF 브랜치의 경우, NeRF가 장면 세부 사항을 복구하는 데 도움이 되는 모델 용량과 PE의 주파수 대역폭을 검사합니다; 모델 아키텍처 외에도, 2) 그리드 피쳐로 NeRF의 순수한 조정된 입력을 풍부하게 하는 효능, 그리고 3) 피쳐 그리드를 향상시키기 위한 supervision 신호로서의 NeRF의 효능도 조사합니다.

Model configuration.
그리드 브랜치의 경우, 그림 7에서 단일 해상도 피쳐 그리드를 채택하면 성능이 저하된다는 것을 보여줍니다.
구체적으로, 저해상도 (512^2) 그리드 브랜치의 결과는 이미 사전 학습 중에 블러 아티팩트를 겪고 있습니다.
후반부에 NeRF 지점을 추가하면 외관과 옥상에 더 많은 디테일을 만들 수 있지만 전반적으로 명확한 디테일이 부족합니다.
반면에, 고해상도(2048^2) 그리드 브랜치의 결과는 학습 전 단계에서 블러하고 노이즈가 많으며, NeRF에 의해 상당 부분 완화되지만 도로나 벽과 같은 연속적인 지역에서는 여전히 불안정합니다.
기존 작품 [9, 36, 53]은 일반적으로 그리드 피쳐를 이동하기 위해 작은 MLP를 렌더러로 채택합니다.
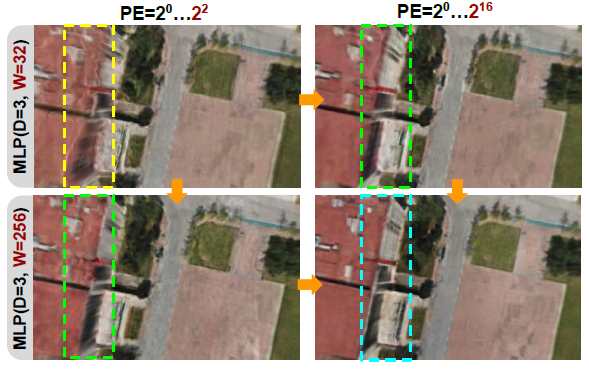
그림 8에서 우리는 우리의 시나리오에서 작은 모델 용량 (D=3,W=32)을 가진 NeRF가 이러한 복잡한 장면의 그리드 피쳐를 이동하기에 불충분하여 부정확한 지오메트리를 제공하고 많은 장면 세부 사항을 누락시킨다는 것을 보여줍니다.
이 상황에서는 PE에서 주파수 대역폭을 나이브하게 증가시키는 것이 거의 도움이 되지 않습니다.
MLP (D=3, W=256)를 확장하면 상당한 개선을 관찰할 수 있으며, 이를 통해 PE를 통해 더 높은 주파수 입력을 부과하면 더 많은 장면 세부 정보를 복구하는 데 도움이 될 수 있습니다.
Efficacy of grid features to NeRF.
우리는 그리드 피쳐를 조정하고 그리드 지점의 supervision 없이 NeRF에 그리드 피쳐를 간단히 공급하는 것부터 시작합니다.
NeRF는 이미 그리드 피쳐에 인코딩된 로컬 기능의 이점을 누릴 수 있으며, PSNR이 약 1dB 향상되었습니다.
피쳐 그리드를 조정하면 PSNR에서 약 2.5dB의 이득을 얻을 수 있습니다.
Efficacy of NeRF supervision to feature grid.
그림 7에 나타난 바와 같이, NeRF는 그리드 해상도가 불충분할 때 더 많은 세부 사항을 복구하고, 정규화되지 않은 기능을 전역적으로 원활하게 처리하여 더 일관된 렌더링 결과를 생성하는 데 도움을 줍니다.
고해상도 그리드에서 NeRF를 결합하면 Campus 장면에서 PSNR을 약 2dB까지 높일 수 있습니다.
5. Discussion and Conclusion
이 연구에서는 대규모 도심 장면 렌더링을 목표로 하며, MLP 기반 NeRF와 명시적으로 구성된 피쳐 그리드를 통합하여 지역 및 전역 장면 정보를 효과적으로 인코딩하는 새로운 프레임워크를 제안합니다.
우리의 방법은 대규모 장면에 적용될 때 SOTA 방법의 다양한 단점을 극복합니다.
우리 모델은 매우 대규모 도시 장면에서도 높은 시각적 충실도 렌더링을 달성하며, 이는 실제 응용 시나리오에 매우 중요합니다.
우리는 주로 대규모 도시 장면 시나리오에 맞춘 그라운드 피쳐 평면 표현을 조사하지만, 다른 그리드 기반 표현에도 우리의 두 가지 설계를 고려할 수 있습니다, 이는 학습된 피쳐 값을 더 연속성 있게 조정하여 추가적인 정규화 역할을 합니다.
그럼에도 불구하고, 우리 모델은 공동 학습 단계에서의 느린 학습과 같은 NeRF 기반 방법의 몇 가지 한계를 물려받습니다.
또 다른 중요한 문제는 많은 양의 고해상도 이미지를 다루는 것입니다.
현재 혼합된 ray의 배치 샘플링은 분산 학습 없이는 매우 비효율적입니다.
더 많은 논의는 보충 자료에서 찾을 수 있습니다.