2025. 3. 14. 13:22ㆍ3D Vision/Urban Scene Reconstruction
CityGaussian: Real-time High-quality Large-Scale Scene Rendering with Gaussians
Yang Liu, He Guan, Chuanchen Luo, Lue Fan, Naiyan Wang, Junran Peng, Zhaoxiang Zhang
Abstract
실시간 3D 장면 재구성과 새로운 뷰 합성의 발전은 3D Gaussian Splatting (3DGS)에 의해 크게 촉진되었습니다.
그러나 대규모 3DGS를 효과적으로 학습하고 다양한 규모에서 실시간으로 렌더링하는 것은 여전히 어려운 과제입니다.
이 논문은 효율적인 대규모 3DGS 학습 및 렌더링을 위해 새로운 분할 정복 학습 접근 방식과 Level-of-Detail (LoD) 전략을 사용하는 CityGaussian (CityGS)을 소개합니다.
특히, 전역 장면 prior 및 적응형 학습 데이터 선택은 효율적인 학습과 원활한 융합을 가능하게 합니다.
융합된 가우시안 프리미티브를 기반으로 압축을 통해 다양한 세부 레벨을 생성하고, 제안된 블록 단위 세부 레벨 선택 및 집계 전략을 통해 다양한 스케일에서 빠른 렌더링을 실현합니다.
대규모 장면에 대한 광범위한 실험 결과는 우리의 접근 방식이 SOTA 렌더링 품질을 달성하여 다양한 규모에서 대규모 장면을 일관되게 실시간으로 렌더링할 수 있음을 보여줍니다.
1 Introduction
AR/VR [6, 11], 항공 측량 [36], 스마트 시티 [4, 8], 자율 주행 [34]의 중추적인 구성 요소인 3D 대규모 장면 재구성은 최근 수십 년 동안 학계와 산업계에서 광범위한 주목을 받고 있습니다.
이러한 작업은 일반적으로 1.5km^2 이상의 넓은 지역에 대해 다양한 규모에서 고충실도 재구성 및 실시간 렌더링을 추구합니다 [36].
지난 몇 년 동안 이 분야는 neural radiance fields (NeRF) [21] 기반 방법이 지배적이었습니다.
대표적인 작품으로는 Block-NeRF [34], BungeNeRF [41], ScaNeRF [40]이 있습니다.
하지만 여전히 세부 사항에 충실하지 못하거나 성능이 부진합니다.
최근 3D Gaussian Splatting (3DGS) [12]이 유망한 대안 솔루션으로 떠오르고 있습니다.
NeRF와 달리, 장면을 표현하기 위해 명시적인 3D 가우시안을 기본 요소로 사용합니다.
고효율 래스터화 알고리즘 덕분에 3DGS는 실시간 렌더링 속도로 고품질의 시각적 효과를 달성합니다.
대부분의 기존 3DGS 관련 학문적 탐구는 주로 물체나 작은 장면에 초점을 맞추고 있습니다.
그러나 대규모 장면 재구성에 3DGS를 적용하면 악마가 나타납니다.
한편, 대규모 장면에 3DGS를 직접 배치하면 학습 중 GPU 메모리에 엄청난 오버헤드가 발생합니다.
예를 들어, 24G RTX3090은 가우시안 수가 1,100만 개 이상 증가할 때 메모리 부족 오류를 발생시킵니다.
그러나 항공 시야에서 높은 시각적 품질로 1.5km² 이상의 도시 지역을 재건하려면 2천만 이상의 가우시안이 필요할 수 있습니다.
이러한 용량의 3DGS는 40G A100에서도 직접 학습할 수 없습니다.
반면 렌더링 속도 병목 현상은 뎁스 정렬에 있습니다.
가우시안의 수가 수백만으로 증가함에 따라 래스터화가 매우 느려집니다.
예를 들어, 110만의 가우시안으로 구성된 Tanks&Temple [13]의 작은 학습 장면 데이터셋은 평균 가시 가우시안 수가 약 65만이고 속도는 103FPS로 렌더링됩니다.
하지만 2.7km^2의 MatrixCity 장면은 2,300만의 가우시안 수가 평균 약 65만임에도 불구하고 21FPS의 속도로만 렌더링할 수 있습니다.
불필요한 가우시안을 래스터화로부터 해방시키는 방법은 실시간 대규모 장면 렌더링의 핵심입니다.
위에서 언급한 문제들을 해결하기 위해, 우리는 CityGaussian (CityGS)을 제안합니다.
MegaNeRF [36]에서 영감을 받아 분할 정복 전략을 채택했습니다.
전체 장면은 먼저 공간적으로 인접한 블록으로 분할되어 병렬로 학습됩니다.
각 블록은 훨씬 적은 수의 가우시안으로 표현되며 더 적은 데이터로 학습됩니다, 단일 GPU의 메모리 비용이 크게 감소합니다.
가우시안 분할의 경우, 다양한 블록 간의 워크로드 균형을 개선하기 위해 무한 영역을 정규화된 유계 큐빅으로 축소하고 균일한 그리드 분할을 적용합니다.
학습 데이터 분할의 경우, 포즈가 고려된 블록 내에 있거나 고려된 블록이 렌더링 결과에 상당한 기여를 하는 경우에만 포즈가 유지됩니다.
이 새로운 전략은 표 4에 나와 있는 것처럼 비 상대적 데이터의 방해를 효율적으로 피하면서도 가우시안 소비를 줄이면서 더 높은 충실도를 가능하게 합니다.
학습된 가우시안을 인접 블록과 정렬하기 위해 각 블록의 학습을 coarse 전역 가우시안 prior로 가이드합니다.
이 전략은 블록 간의 상호작용 간섭을 효율적으로 피하고 원활한 융합을 가능하게 합니다.
대규모 가우시안 렌더링 시 계산 부담을 줄이기 위해 블록 단위 Level-of-Detail (LoD) 전략을 제안합니다.
핵심 아이디어는 추가 계산 비용을 제거하면서 필요한 가우시안만 래스터라이저에 공급하는 것입니다.
구체적으로, 우리는 이전에 나누어진 블록을 단위로 삼아 어떤 가우시안이 frustum에 포함될 가능성이 있는지 신속하게 결정합니다.
게다가 원근감 효과로 인해 먼 지역은 화면 공간의 작은 영역을 차지하고 세부 사항이 적습니다.
따라서 카메라에서 멀리 떨어진 가우시안 블록은 더 적은 포인트와 기능을 사용하여 압축된 버전으로 교체할 수 있습니다.
이러한 방식으로 래스터라이저의 처리 부담은 크게 줄었지만, 도입된 추가 계산은 여전히 허용 가능합니다.
그림 1의 (d,e)에 나타난 바와 같이, 우리의 CityGS는 매우 넓은 field-of-view에서도 실시간 대규모 장면 렌더링을 유지할 수 있습니다.

간단히 말해서, 이 작업은 세 가지 기여를 합니다:
• 우리는 대규모 3D Gaussian Splatting을 병렬 방식으로 재구성하기 위한 효과적인 분할 정복 전략을 제안합니다.
• 제안된 LoD 전략을 통해, 우리는 품질 손실을 최소화하면서 극적으로 다른 스케일에서 실시간 대규모 장면 렌더링을 실현합니다.
• 우리의 방법인 CityGS는 공개 벤치마크에서 최신 방법들에 비해 유리한 성능을 보입니다.
2 Related Works
2.1 Neural Rendering
Neural Radiance Field는 3D 장면 재구성과 새로운 뷰 합성을 위한 도구적 기법입니다.
암시적인 신경 장면 표현으로, 쿼리 위치와 해당 래디언스 사이의 매핑 함수로 Multilayer Perceptrons (MLP)을 사용합니다.
그런 다음 볼륨 렌더링을 적용하여 이러한 표현을 2D 이미지로 렌더링합니다.
NeRF의 성공은 원래 방법의 다양한 측면을 개선한 다양한 후속 작업 [2, 3, 19, 20, 25–27, 35, 42]을 탄생시켰습니다.
그 중에서도 Mip-NeRF360 [3]은 뛰어난 렌더링 품질로 최근의 이정표 역할을 하고 있습니다.
그러나 NeRF는 방출된 ray를 따라 집중적으로 샘플링되어 상대적으로 높은 학습 및 추론 지연 시간을 초래합니다.
이 문제를 완화하기 위해 일련의 방법 [5, 10, 23, 32, 46]이 제안되었습니다.
가장 대표적인 예로는 InstantNGP [23]와 Plenoxels [10]가 있습니다.
멀티 해상도 해시 그리드와 소규모 신경망을 결합한 InstantNGP는 높은 이미지 품질을 유지하면서 몇 배의 속도 향상을 달성합니다.
반면에, Plenoxels은 희소한 복셀 그리드를 가진 연속 밀도 필드를 나타내며, 이는 상당한 속도 향상과 뛰어난 성능을 함께 제공합니다.
Point-based Rendering
또 다른 평행선은 장면을 점 기반 표현으로 렌더링합니다.
이러한 명시적인 지오메트리 프리미티브는 빠른 렌더링 속도와 높은 편집성을 가능하게 합니다.
선구적인 작업에는 [14, 39, 44, 45, 51]이 포함되지만 렌더링된 이미지의 불연속성은 여전히 문제로 남아 있습니다.
최근 제안된 3D Gaussian Splatting (3DGS) [12]은 3D 가우시안을 프리미티브로 사용하여 이 문제를 해결했습니다.
고도로 최적화된 래스터라이저와 결합된 3DGS는 시각적 충실도의 loss 없이 NeRF 기반 패러다임보다 뛰어난 렌더링 속도를 달성할 수 있습니다.
그럼에도 불구하고, 고차원 피쳐 (RGB, 구형 고조파 등)을 가진 명시적인 수백만의 가우시안들은 상당한 메모리 및 저장 공간을 확보하게 됩니다.
이 부담을 완화하기 위해 [9,15,22]와 같은 방법론이 제안됩니다.
벡터 양자화 [24]외에도, [9], [22]는 각각 distillation과 2D 그리드 분해를 결합하여 저장 공간을 압축하면서 속도를 향상시킵니다.
Joo et al. [15]은 가우시안의 기하학적 유사성과 로컬 피쳐 유사성을 활용하여 유사한 성능을 실현합니다.
압축과 속도 향상에 성공했음에도 불구하고, 이러한 연구들은 작은 장면이나 단일 객체에 집중하고 있습니다.
대규모 장면에서는 과도한 메모리 비용과 계산 부담으로 인해 고품질 재구성 및 실시간 렌더링에 어려움이 발생합니다.
그리고 우리의 CityGS는 이러한 문제들에 대한 효율적인 해결책 역할을 합니다.
2.2 Large Scale Scene Reconstruction
대규모 이미지 컬렉션에서 3D 재구성은 수십 년 동안 많은 연구자와 엔지니어들의 열망이었습니다.
Photo Tourism [30]과 Building Rome in a Day [1]는 견고하고 병렬적인 대규모 장면 재구성의 초기 탐사를 대표하는 두 가지 사례입니다.
NeRF [21]의 발전으로 패러다임이 바뀌었습니다.
Block-NeRF [34]와 Mega-NeRF [36]에서는 분할 정복 전략이 채택되었으며, 각 분할된 블록은 작은 MLP로 표현됩니다.
Switch-NeRF [49]는 학습 가능한 장면 분해 전략을 도입하여 성능을 더욱 향상시킵니다.
Urban Radiance Fields [28]와 SUDS [37]는 LiDAR 및 2D 광학 플로우와 같은 RGB 이미지를 넘어서는 모달리티로 대형 장면 재구성을 더욱 탐구합니다.
모델 저장과 성능의 균형을 더 잘 맞추기 위해 Grid-NeRF [43]는 멀티 해상도 피쳐 평면의 가이던스를 도입하고, GP-NeRF [48]와 City-on-Web [31]은 해시 그리드와 멀티 해상도 삼중 평면 표현을 활용합니다.
실시간 렌더링을 실현하기 위해 UE4-NeRF [11]은 분할된 서브 NeRF를 다각형 메쉬로 변환하고 Unreal Engine 4의 성숙한 래스터라이제이션 파이프라인을 결합합니다.
ScaNeRF [40]은 현실적인 장면에서 부정확한 카메라 포즈의 문제점을 더욱 보완합니다.
VastGaussian [17]은 대규모 장면에서 3DGS의 적용을 탐구하고 외관 변화를 다룹니다.
그러나 이렇게 큰 장면의 낮은 렌더링 속도는 여전히 문제로 남아 있습니다.
반면, 우리의 접근 방식은 3D 가우시안 프리미티브와 잘 설계된 학습 및 LoD 방법론을 결합하여 실시간 렌더링 품질을 크게 향상시킵니다.
2.3 Level of Detail
컴퓨터 그래픽스에서 Level of Detail (LoD) 기법은 복잡성과 성능을 연결하기 위해 가상 세계를 표현하는 데 사용되는 세부 사항의 양을 조절합니다 [18].
일반적으로 LoD는 덜 중요해지는 객체 (예: 뷰어에서 멀어지는 경우)의 작업량을 줄여줍니다.
최근 몇 년 동안 LoD와 뉴럴 래디언스 필드의 통합이 큰 관심을 받고 있습니다.
BungeeNeRF [41]은 NeRF에 점진적인 성장 전략을 제공하며, 각 잔여 블록은 더 세밀한 디테일 수준을 담당합니다.
반면, NGLoD [33]은 멀티 해상도 희소 복셀 옥트리를 가진 다양한 세부 수준의 신경 signed distance functions (SDF)를 나타내며, VQ-AD [32]는 계층적 피쳐 그리드를 사용하여 3D 신호의 LoD를 압축적으로 표현합니다.
Mip-NeRF [21]에서 영감을 받아, Tri-MipRF와 LoD-NeuS [50]는 안티에일리어드 LoD를 위해 멀티 해상도 삼중 평면 표현을 사용한 콘 캐스팅을 적용합니다.
City-on-Web [31]은 저해상도의 피쳐 그리드와 해당 지연 MLP 디코더를 학습하여 더 coarse한 디테일 레벨을 생성합니다.
명시적인 3D 가우시안 표현에서 LoD를 실현함으로써, 대규모 장면에서 실시간 성능을 효율적으로 향상시킵니다.


3 Method
Overview
학습 파이프라인과 렌더링 파이프라인은 각각 그림 2와 그림 3에 나와 있습니다.
먼저 섹션 3.1에 설명된 일반적인 3DGS 학습 전략으로 전역 장면 묘사를 제공하는 3DGS를 생성합니다.
이 전역 prior 정보를 바탕으로, 우리는 섹션 3.2에서 제시된 학습 전략을 사용하여 가우시안 원시 데이터와 데이터를 적응적으로 나누어 추가 병렬 학습을 수행합니다.
융합된 대규모 가우시안을 기반으로, 섹션 3.3에서 논의된 우리의 Level of Detail (LoD) 알고리즘은 빠른 렌더링을 위해 필요한 가우시안을 동적으로 선택합니다.
3.1 Preliminary
3DGS에 대한 간략한 소개로 시작합니다 [12].
3DGS는 이산 3D 가우시안 G_K = {G_k|k = 1, ..., K}의 장면을 나타냅니다, 이들 각각은 3D 위치 p_k ∈ R^(3×1), 불투명도 α_k ∈ [0, 1], 지오메트리 (즉, 가우시안 공분산을 구성하는 데 사용되는 스케일링 및 회전), spherical harmonics (SH)는 뷰 의존적 색상 c_k ∈ R^(3×1)을 위해 f_k ∈ R^(3×16)을 피쳐로 합니다.
렌더링 시 i번째 이미지의 intrinsic κ와 포즈 τ_i가 주어지면 가우시안을 화면 공간에 분할하고 뎁스 순서대로 정렬한 다음 알파 블렌딩을 통해 렌더링합니다:
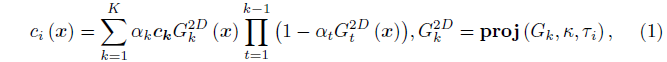
, proj는 프로젝션 연산, c_i(x)는 픽셀 위치 x에서의 색상, G_k^2D는 프로젝션 가우시안 분포입니다.
자세한 내용은 독자들에게 원본 논문 [12]을 참조해 주시기 바랍니다.
최종 렌더링된 이미지는 I_G_K (τ_i)로 표시됩니다.
학습 중에 일반적인 초기화 선택은 COLMAP [29]와 같이 Structure-from-Motion (SfM)로 생성된 포인트 클라우드입니다.
그런 다음 미분 가능한 렌더링에서 파생된 그래디언트를 기반으로 가우시안을 복제, 밀도화, 프루닝 및 일관되게 정제합니다.
그러나 대규모 장면의 묘사는 2천만 개 이상의 프리미티브를 소모할 수 있어 학습 과정에서 메모리 부족 오류를 쉽게 유발할 수 있으며, 렌더링 시간도 느려집니다.
3.2 Training CityGS
이 섹션에서는 먼저 coarse 전역 가우시안 prior의 필요성과 이를 생성하는 방법을 설명합니다.
이 prior를 바탕으로 가우시안 및 데이터 프리미티브 분할 전략을 설명합니다.
이 섹션의 마지막에는 학습 및 후처리 세부 사항을 소개합니다.
파이프라인은 그림 2에 나와 있습니다.
Global Gaussian Prior Generation
이 부분은 추가적인 가우시안 및 데이터 분할의 기초가 됩니다.
직관적인 대규모 장면 학습 전략에는 COLMAP 포인트에 분할 정복 전략을 적용하는 것이 포함됩니다.
그러나 뎁스 제약과 전역 인지도 부족으로 인해 블록 외부 영역에 과적합되는 기하학적으로 부정확한 플로터들이 많이 생성되어 서로 다른 블록의 신뢰할 수 있는 융합이 어렵습니다.
또한, COLMAP 포인트에서 렌더링된 이미지는 블러하고 부정확한 경향이 있어 특정 뷰가 블록을 학습하는 데 중요한지 평가하기 어렵습니다.
이를 위해, 우리는 문제를 해결하는 간단하면서도 효과적인 방법을 제안합니다.
구체적으로, 먼저 30,000번의 반복에 대해 모든 관측값을 가진 COLMAP 포인트를 학습하여 전체 기하 분포에 대한 대략적인 설명을 제공합니다.
결과적으로 생성된 가우시안 원시 집합은 G_K = {G_k|k = 1, ...,K}로 표시되며, 여기서 K는 총량입니다.
추가적인 블록 단위 파인튜닝에서는 이러한 강력한 전역 지오메트리가 기하학적으로 적절한 위치를 가리키게 하여 융합에 대한 심각한 간섭을 제거합니다.
표 4에서 입증된 바와 같이, 이 전략은 렌더링 충실도를 효율적으로 향상시킬 수 있습니다.
게다가, 이 coarse 가우시안은 더 정확한 기하학적 분포와 더 깨끗한 렌더링 이미지를 제공하여 후속 프리미티브와 데이터 분할을 용이하게 합니다.

Primitives and Data Division
대부분의 실제 장면이 무한하다는 점을 고려할 때 [35] 최적화된 가우시안은 무한히 확장될 수 있습니다.
원래 3D 공간에 균일한 그리드 분할을 직접 적용하면 거의 빈 블록이 많아져 워크로드의 균형이 심각하게 깨질 수 있습니다.
이 문제를 완화하기 위해 먼저 유계 입방체 영역 prior에 전역 가우시안을 축소합니다.
수축을 위해 내부 전경 영역, 즉 그림 2의 분홍색 사각형은 선형 공간 매핑을 포함하고 외부 배경 영역은 비선형 매핑을 포함합니다.
구체적으로, 우리는 모서리 p_min과 p_max의 최소 및 최대 위치를 가진 전경 영역을 묘사합니다.
그런 다음 가우시안 위치를 ˆp_k = 2 (p_k - p_min) / (p_max - p_min) - 1로 정규화합니다.
따라서 전경 가우시안의 위치는 [-1, 1] 범위 내에 있습니다.
후속 축소는 다음 함수 [40]를 사용하여 실행됩니다:
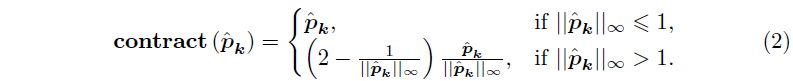
이 수축된 입방체 공간을 균등하게 분할함으로써, 보다 균형 잡힌 가우시안 분할이 도출됩니다.
파인튜닝 단계에서는 각 블록이 충분히 학습되기를 바랍니다.
구체적으로 말하자면, 할당된 데이터는 블록 내 세부 사항을 정제하는 데 중점을 두고 학습 진행을 계속해야 합니다.
따라서 고려된 블록이 렌더링 결과에 상당한 양의 가시적인 콘텐츠를 투사할 때만 하나의 포즈를 유지해야 합니다.
심각한 가려짐이나 사소한 콘텐츠 기여와 같은 산만한 경우는 차단해야 합니다.
SSIM loss는 구조적 차이를 효율적으로 포착할 수 있고 밝기 변화에 어느 정도 민감하지 않기 때문에 [38], 우리는 이를 데이터 분할 전략의 기초로 삼습니다.
구체적으로, j번째 블록의 경우, 포함된 coarse 전역 가우시안은 G_K_j = {G_k|b_(j,min) ⩽ contract(ˆp_k) < b_(j,max), k = 1, ...,K_j}로 표시됩니다, 여기서 b_(j,min)와 b_(j,max)는 블록 j의 x,y,z 경계를 정의하며, K_j는 포함된 가우시안의 수입니다.
그런 다음 i번째 포즈 τ_i가 j번째 블록에 할당되는지 여부는

에 의해 결정됩니다, 여기서 G_K \ G_K_j는 G_K와 G_K_j의 차이 집합을 정의합니다.
SSIM loss L_SSIM이 임계값 ε보다 크다는 것은 렌더링된 이미지에 블록 j가 상당히 기여한다는 것을 의미하므로 할당으로 이어집니다.
그러나 첫 번째 원칙에만 의존하면 블록 가장자리에서 외부를 볼 때 아티팩트가 발생할 수 있습니다.
이러한 경우는 고려된 블록의 투영을 거의 포함하지 않기 때문에 첫 번째 원칙에 따라 충분히 학습되지 않습니다.
따라서 우리는 또한 고려된 블록, 즉

에 속하는 포즈도 포함합니다, 여기서 ˆp_τ_i는 포즈 i의 월드 좌표 아래에 있는 위치입니다.
그리고 마지막 할당은
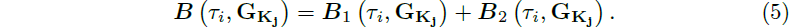
입니다.
위의 전략들이 마련되어 있음에도 불구하고, 분포가 매우 고르지 않거나 블록 차원이 높은 경우에도 빈 블록이 여전히 존재할 수 있습니다.
과적합을 방지하기 위해, 우리는 경계 b_(j,min)와 b_(j,max)를 K_j가 특정 임계값을 초과할 때까지 확장합니다.
이 프로세스는 각 블록에 대해 충분한 학습 데이터를 보장하기 위해 데이터 할당에만 사용됩니다.
Finetuning and Post-processing
데이터와 프리미티브 분할 후, 각 블록을 병렬로 학습시킵니다.
이 파인튜닝 단계는 원래 수축되지 않은 공간 아래에 있다는 점에 주목할 가치가 있습니다.
구체적으로, 우리는 섹션 3.2에서 생성된 coarse 전역 prior를 활용하여 각 블록의 파인튜닝을 초기화합니다.
학습 손실은 원래 3DGS 논문 [12]에 명시된 접근 방식을 따르며, 이는 L1 loss와 SSIM loss의 가중 합으로 구성됩니다.
그런 다음 각 블록에 대해 공간 경계 내에 포함된 파인튜닝된 가우시안을 필터링합니다.
전역 기하학적 prior 덕분에 블록 간 간섭이 크게 완화되었습니다.
따라서 직접 concat을 통해 고품질의 전체 모델을 도출할 수 있습니다.
추가적인 질적 검증은 부록에서 확인할 수 있습니다.
LoD 부분에는 추가적인 개선이 남아 있습니다.
3.3 Level-of-Detail on CityGS
섹션 1에서 논의한 바와 같이, 불필요한 가우시안이 래스터라이저에 미치는 계산 부담을 없애기 위해, 우리의 CityGS는 여러 세부 수준 생성과 블록 단위 가시 가우시안 선택을 포함합니다.
다음 두 부분에서 각각 이 두 부분을 소개합니다.
Detail Level Generation
물체가 카메라에서 멀어질수록 화면에서 차지하는 면적은 줄어들고 고주파 정보는 줄어듭니다.
따라서 멀리 떨어져 있고 세부 수준이 낮은 영역은 낮은 용량, 즉 포인트 수, 피쳐 차원 수, 데이터 정밀도가 낮은 모델로 잘 표현될 수 있습니다.
실제로, 우리는 학습된 가우시안에 직접 작동하는 고급 압축 전략인 LightGaussian [9]을 사용하여 다양한 세부 수준을 생성하며, 성능 저하를 최소화하면서 상당한 압축률을 달성합니다.
그 결과, 필요한 가우시안에 대한 메모리 및 계산 요구가 크게 완화되고 렌더링 충실도는 여전히 잘 유지됩니다.
Detail Level Selection and Fusion
세부 수준 선택의 베이스라인은 서로 다른 거리 간격 사이의 frustum 영역을 해당 세부 수준에서 가우시안으로 채우는 것입니다.
그러나 이 방법은 포인트별 거리 계산과 할당이 필요하여 섹션 4.4에서 확인된 바와 같이 상당한 계산 오버헤드를 초래합니다.
따라서 그림 3의 오른쪽 부분에 표시된 것처럼 공간적으로 인접한 블록을 단위로 고려하여 블록별 전략을 채택합니다.
각 블록은 frustum 교차점 계산을 위해 8개의 모서리가 있는 정육면체로 간주됩니다.
특정 블록에 포함된 모든 가우시안은 8개의 모서리에서 카메라 중심까지의 최소 거리에 따라 결정되는 동일한 세부 수준을 공유합니다.
그러나 실제로 우리는 가우시안의 최소 좌표와 최대 좌표가 보통 플로터에 의해 결정된다는 것을 발견했습니다.
결과적으로 부피가 지나치게 커져서 많은 가짜 교차로가 생길 수 있습니다.
이러한 플로터의 영향을 피하기 위해 Median Absolute Deviation (MAD) [7] 알고리즘을 사용합니다.
j번째 블록의 경계는 p_min^j와 p_max^j로 표시되며,

에 의해 결정됩니다, 여기서 n_MAD는 하이퍼파라미터입니다.
적절한 n_MAD를 선택함으로써, 이 방법은 블록의 경계를 더 정확하게 포착할 수 있습니다.
그 후, 카메라 앞의 모든 모서리가 화면 공간에 투사될 것입니다.
이 투영된 점들의 최소값과 최대값은 바운딩 박스를 구성합니다.
화면 면적과의 Intersection-over-Union (IoU)을 계산하여 블록이 frustum과 교차하는지 확인할 수 있습니다.
카메라가 있는 블록과 함께, 해당 세부 수준의 모든 가시적인 블록이 렌더링에 사용될 것입니다.
융합 단계에서는 여전히 다양한 세부 수준이 직접 연결을 통해 이해되며, 이는 무시할 수 있는 불연속성을 초래합니다.
4 Experiments
4.1 Experiments setup
Dataset and Metrics
우리의 알고리즘은 다양한 규모와 환경을 가진 다섯 가지 장면에서 벤치마킹되었습니다.
구체적으로, 우리는 [31]에서와 같이 합성 도시 규모 데이터셋 MatrixCity [16]의 2.7km^2 소도시 장면을 채택합니다.
그러나 부분적인 도시 지역만을 대상으로 학습하고 평가하는 대신, 우리는 도시 전체를 건설하고 성과를 비교합니다.
그리고 이미지 너비를 1600픽셀로 재조정합니다.
또한 Residence, Sci-Art, Rubble, 및 Building [36]을 포함한 공공 실제 장면 데이터셋에 대한 실험도 수행했습니다.
[36,48,49]의 접근 방식에 따라 이러한 데이터셋의 이미지 해상도가 4배 감소합니다.
CityGS의 일반화 능력을 더욱 검증하기 위해, 우리는 MatrixCity의 스트리트 뷰 장면 Block_A에서도 이를 테스트합니다 [16].
이 도전적인 장면에는 4076개의 학습 이미지와 495개의 테스트 이미지가 포함되어 있습니다.
다양한 방법의 재구성 품질을 종합적으로 측정하기 위해 표준 SSIM, PSNR, LPIPS를 지표로 사용합니다 [47].
렌더링 속도를 평가하기 위해 FPS를 비교하기도 합니다.
시간을 측정하기 전에 모든 CUDA 스트림을 동기화하여 각 프레임의 렌더링 시간을 객관적으로 평가할 수 있다는 점은 주목할 만합니다.
Implementations and Baselines
우리의 방법은 먼저 블록 단위의 추가 정제를 위해 coarse 전역 가우시안 사전 학습을 수행합니다.
Sci-Art, Residence 및 Rubble에 대한 사전 학습은 3DGS [12]에 명시된 매개변수 설정을 준수합니다.
하지만 Building과 MatrixCity의 경우, 공격적인 최적화로 인한 과소적합을 방지하기 위해 위치와 스케일링 학습률을 절반으로 줄였습니다.
파인튜닝 단계에서는 각 블록을 초기화 전에 coarse 전역 가우시안을 사용하여 30,000번 더 반복하도록 학습시킵니다.
또한, 3DGS 설정에 비해 위치 학습률은 60% 감소한 반면, 스케일링 학습률은 경험적으로 20% 감소했습니다 [12].
수축 함수의 전경 영역은 중앙 1/3 영역으로 선택되며, 자세한 블록 차원은 부록에서 확인할 수 있습니다.
우리의 방법은 Mega-NeRF [36], Switch-NeRF [49], GPNeRF [48] 및 3DGS [12]와 비교하여 벤치마킹되었습니다.
데이터셋에는 원래 3DGS 논문 [12]에서 사용된 것보다 훨씬 큰 수천 개의 이미지가 포함되어 있기 때문에, 우리는 전체 반복을 60,000으로 조정하면서 가우시안을 반복 간격 1,000에서 30,000으로 밀도화합니다.
이 강력한 베이스라인을 3DGS †이라고 합니다.
LoD에서는 MatrixCity 데이터셋을 사용하여 평가합니다.
우리는 LoD 2가 가장 우수하고 LoD 0이 가장 coarse 3가지 세부 레벨을 사용합니다.
섹션 3.3에서 언급된 n_MAD는 4로 설정됩니다.
0m에서 200m 이내의 블록은 LoD 2로 표시되며, 200m에서 400m 이내의 블록은 LoD 1로 표시되며, 다른 블록은 LoD 0으로 표시됩니다.


4.2 Comparison with SOTA
SOTA 대규모 장면 재구성 전략과의 apple-to-apple 렌더링 품질 비교를 위해, 우리는 LoD가 없는 CityGS의 성능을 사용합니다.
정량적 결과는 표 1에 나와 있습니다.
페이지 제한으로 인해 Sci-Art의 결과를 부록에 넣었습니다.
우리의 방법이 NeRF 기반 베이스라인을 큰 차이로 능가하는 것을 관찰할 수 있었습니다.
한편, 우리가 아는 한, 우리의 방법은 150m에서 500m에 이르는 매우 가변적인 카메라 고도로 MatrixCity 전체를 성공적으로 재구성한 최초의 시도입니다 [16].
PSNR은 27.46에 도달했으며, 그림 5에 제시된 정성적 결과도 렌더링의 높은 충실도를 입증합니다.
기본 3DGS†과 비교했을 때, 우리의 CityGS는 훨씬 더 풍부한 세부 사항을 포착할 수 있습니다.
MatrixCity에 대한 자세한 시각화는 부록에서 확인할 수 있습니다.
다른 세 가지 현실적인 장면에서는 우리의 방법이 훨씬 더 높은 SSIM과 LPIPS를 가능하게 하여 뛰어난 시각적 품질을 나타냅니다.
그림 4에서 볼 수 있듯이, girder steel 및 창문과 같은 얇은 구조물을 잘 재구성할 수 있습니다.
잔디와 잔해와 같은 복잡한 구조물의 세부 사항도 잘 복구되었습니다.
또한, 표 3의 결과는 우리의 학습 전략이 거리 장면에 잘 일반화될 수 있음을 입증합니다.


4.3 Level of Detail
MatrixCity는 700개 이상의 이미지와 다양한 고도의 테스트 분할을 보유하고 있다는 점을 고려하여, 이를 기준으로 LoD 전략의 효과를 평가합니다.
구체적으로, 먼저 압축률이 50%, 34%, 25%인 세 가지 세부 수준, 즉 LoD 2, LoD 1, LoD 0을 생성합니다.
우리 CityGS는 제안된 LoD 기법을 적용하여 이러한 모든 세부 수준을 결합합니다.
표 2에 나타난 바와 같이, 가장 세밀한 LoD 2는 렌더링 품질이 가장 우수하며, 가장 coarse한 LoD 0은 렌더링 속도가 가장 빠릅니다.
세 가지 세부 수준과 비교했을 때, LoD 기법이 적용된 버전은 LoD 2에 이어 SSIM과 PSNR을 두 번째로 얻으며, 속도는 LoD 1에 매우 가깝습니다.

그러나 MatrixCity 테스트 스플릿의 카메라 고도는 500m 이하로 제한되어 있습니다.
극단적인 스케일 분산 하에서 성능을 검증하기 위해, 우리는 피치를 조정하여 지정된 고도에 따라 직선으로 아래쪽을 보도록 하고, 다른 자세 속성은 변경하지 않습니다.
다양한 고도에서의 렌더링 결과는 그림 1의 (d) 부분과 (e) 부분에서 확인할 수 있습니다.
LoD가 있는 버전과 없는 버전 간의 시각적 차이는 깊이 확대할 때만 관찰할 수 있습니다.

그림 6에서는 카메라 높이에 따라 평균 렌더링 속도와 최소 렌더링 속도가 어떻게 변하는지를 보여줍니다.
LoD 0은 렌더링 품질이 낮기 때문에 고려되지 않습니다.
평균 FPS를 비교하면 LoD와 단일 디테일 레벨의 결과 모두 vanilla보다 큰 차이로 우수한 성능을 발휘합니다.
그리고 LoD 버전은 모든 높이에서 가장 높은 속도를 자랑합니다.
최소 FPS를 비교해보면, LoD 버전만이 다양한 높이의 최악의 경우에도 일관된 실시간 성능을 발휘하는 반면, 단일 디테일 레벨의 최악의 속도는 카메라가 들어올수록 급격히 떨어집니다.
즉, 제안된 LoD는 급격하게 변화하는 스케일 간의 원활한 실시간 전환을 돕습니다.
4.4 Ablation
이 섹션에서는 표 4와 같이 학습 전략의 영향을 분석합니다.
기본적으로 각 블록의 1.5배 더 넓은 영역에서 카메라를 사용하여 학습했습니다.
표 4의 첫 번째 줄과 마지막 줄의 결과는 이 방법이 CityGS에 비해 현저히 성능이 떨어졌음을 나타냅니다.
주요 문제는 블록 외부의 과적합 영역으로 인한 플로터지만, 이는 전역 모델의 지침에 따라 완화되어 표 4의 두 번째 줄에서 볼 수 있듯이 성능이 향상됩니다.
그러나 이 개선된 베이스라인은 CityGS보다 1.5배 더 많은 가우시안을 사용하므로 비효율적입니다.
마지막 세 줄은 식 (3)이 데이터 분할에 매우 중요하다는 것을 보여주며, 식 (4)가 블록 가장자리의 플로터를 방지하는 데 도움이 된다는 것을 발견했습니다.
추가 하이퍼파라미터 ablations에 대한 자세한 내용은 부록에 나와 있습니다.

LoD 전략에 대한 정량적 ablation은 표 5에 나와 있습니다.
첫 번째 행과 두 번째 행을 비교하면 포인트별 전략으로 인한 계산 부담으로 인해 실시간 성능이 상당히 저하됩니다.
렌더링 품질은 더 작은 간격 설정, 즉 세 번째 행과 동등합니다.
첫 번째 행과 세 번째 행 및 네 번째 행을 비교하면, LoD 2와 LoD 1의 간격이 클수록 렌더링된 결과에 더 풍부한 세부 사항이 포함되지만 속도가 저하된다는 것을 알 수 있습니다.
그리고 첫 번째 행은 표준 설정으로 채택된 균형에 도달합니다.
5 Conclusions
본 연구에서는 실시간 대규모 장면 재구성을 높은 충실도로 성공적으로 구현한 CityGS를 소개합니다.
가우시안 지오메트리에 맞춘 블로킹 및 LoD 전략을 통해 주류 벤치마크에서 SOTA 렌더링 충실도를 확보하는 동시에 동일한 장면의 스케일을 크게 다르게 렌더링할 때 시간 비용을 크게 절감할 수 있습니다.
그러나 숨겨진 정적 장면 가정은 일반화 능력을 제한합니다.
항공 뷰와 스트리트 뷰와 같은 극적으로 다른 뷰를 결합한 학습은 CityGS의 성능을 향상시키는 대신 성능을 저하시킵니다.
내부 메커니즘은 더 깊이 탐구하고 잘 해결할 가치가 있습니다.