2025. 4. 9. 11:23ㆍ3D Vision/Urban Scene Reconstruction
Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, Sida Peng
Abstract
이 논문은 자율 주행 장면을 위한 동적인 도시 스트리트 모델링 문제를 해결하는 것을 목표로 합니다.
최근 방법들은 추적된 차량 포즈를 애니메이션 차량에 통합하여 NeRF를 확장하여 역동적인 도시 거리 장면을 사진사실적으로 시각적으로 합성할 수 있게 합니다.
그러나 학습 속도와 렌더링 속도가 느리다는 점에서 큰 한계가 있습니다.
우리는 이러한 한계를 극복하기 위한 새로운 명시적 장면 표현인 Street Gaussians를 소개합니다.
구체적으로, 동적인 도시 장면은 각각 전경 차량이나 배경과 연관된 시맨틱 로짓과 3D 가우시안이 장착된 포인트 클라우드 집합으로 표현됩니다.
전경 물체 차량의 역학을 모델링하기 위해 각 물체 포인트 클라우드는 최적화 가능한 추적 포즈와 동적 외관을 위한 4D 구형 고조파 모델로 최적화됩니다.
명시적인 표현을 통해 객체 차량과 배경을 쉽게 구성할 수 있으며, 이를 통해 학습 후 30분 이내에 장면 편집 작업과 렌더링을 135 FPS (1066 * 1600 해상도)로 수행할 수 있습니다.
제안된 방법은 KITTI 및 Waymo Open 데이터셋을 포함한 여러 도전적인 벤치마크에서 평가됩니다.
실험 결과, 제안된 방법이 모든 데이터셋에서 일관되게 SOTA 방법을 능가하는 것으로 나타났습니다.
코드는 재현성을 보장하기 위해 공개될 것입니다.
1 Introduction
이미지에서 동적 3D 스트리트를 모델링하는 것은 도시 시뮬레이션, 자율 주행, 게임 등 많은 중요한 응용 분야를 가지고 있습니다.
예를 들어, 도시 도로의 디지털 트윈을 자율 주행 차량의 시뮬레이션 환경으로 사용할 수 있어 학습 및 테스트 비용을 절감할 수 있습니다.
이러한 애플리케이션은 캡처된 데이터로부터 3D 스트리트 모델을 효율적으로 재구성하고 실시간으로 고품질의 새로운 뷰를 렌더링해야 합니다.
신경 장면 표현의 발전으로 인해 뉴럴 래디언스 필드 [35]를 사용하여 스트리트 장면을 재구성하려는 몇 가지 방법 [32, 38, 43, 52, 78]이 생겨났습니다.
모델링 능력을 향상시키기 위해 Block-NeRF [52]는 장면을 여러 블록으로 나누고 각 블록을 NeRF 네트워크로 표현합니다.
이 전략은 대규모 스트리트 장면을 사실적으로 렌더링할 수 있게 해주지만, Block-NeRF는 네트워크 매개변수가 많아 학습 시간이 오래 걸립니다.
게다가 자율 주행 환경 시뮬레이션에서 중요한 측면인 스트리트에서의 동적 차량을 처리할 수 없습니다.
최근 일부 방법 [23,39,64,71]은 동적 주행 장면을 전경 이동 차량과 정적 배경으로 구성된 구성 신경 표현으로 표현할 것을 제안합니다.
동적 자동차를 다루기 위해, 그들은 추적된 차량 포즈를 활용하여 관측 공간과 표준 공간 간의 매핑을 설정하고, NeRF 네트워크를 사용하여 자동차의 지오메트리와 외관을 모델링합니다.
이러한 방법들은 합리적인 결과를 제공하지만, 여전히 높은 학습 비용과 낮은 렌더링 속도로 제한됩니다.
이 연구에서는 이미지에서 동적 3D 스트리트 장면을 재구성하기 위한 새로운 명시적 장면 표현을 제안합니다.
기본 아이디어는 포인트 클라우드를 활용하여 동적 장면을 구축하는 것으로, 이를 통해 학습 및 렌더링 효율성이 크게 향상됩니다.
구체적으로, 우리는 도시 스트리트 장면을 정적 배경과 움직이는 차량으로 분해하며, 이는 3D 가우시안을 기반으로 별도로 제작됩니다 [19].
전경 차량의 역학을 처리하기 위해, 우리는 각 지점이 학습 가능한 3D 가우시안 매개변수를 저장하는 최적화 가능한 추적 가능한 차량 포즈를 가진 포인트들로 그들의 지오메트리를 모델링합니다.
또한, 시간에 따라 변하는 모습은 시계열 함수를 사용하여 모든 시간 단계에서 구형 고조파 계수를 예측하는 4D 구형 고조파 모델로 표현됩니다.
동적 3D 가우시안 표현 덕분에 30분 이내에 목표 도시 스트리트를 충실히 재구성하고 실시간 렌더링 (135 FPS@1066x1600)을 달성할 수 있습니다.
제안된 장면 표현을 바탕으로, 우리는 렌더링 성능을 더욱 향상시키기 위한 여러 전략을 개발합니다, 여기에는 추적된 포즈 최적화, 포인트 클라우드 초기화, 그리고 하늘 모델링이 포함됩니다.
우리는 복잡한 차량 움직임과 다양한 환경 조건을 가진 동적스트리트 장면을 제시하는 Waymo Open [51] (Waymo) 및 KITTI [15] 데이터셋에서 제안된 방법을 평가합니다.
모든 데이터셋에서 우리의 접근 방식은 렌더링 품질 측면에서 SOTA 성능을 달성하면서도 이전 방법들보다 100배 이상 빠르게 렌더링되었습니다 [39, 64, 69].
또한, 제안된 구성 요소의 효과와 제안된 표현의 유연성을 입증하기 위해 상세한 ablation과 장면 편집 응용 프로그램이 각각 수행되었습니다.
전반적으로 이 작업은 다음과 같은 기여를 합니다:
– 우리는 고품질의 도시 스트리트 장면을 실시간으로 효율적으로 재구성하고 렌더링하는 복잡한 동적 스트리트 장면을 모델링하기 위한 새로운 장면 표현인 Street Gaussians를 제안합니다.
– 우리는 Street Gaussians의 렌더링 성능을 크게 향상시키는 4D 구형 고조파 외관 모델, 추적 포즈 최적화, 포인트 클라우드 초기화 등 여러 전략을 제안합니다.
2 Related work
Static scene modeling.
신경망 장면 표현은 이미지에서 복잡한 장면을 미분 가능한 렌더링을 통해 모델링할 수 있는 신경망으로 3D 장면을 표현하는 것을 제안합니다.
NeRF [3–5, 35, 36]은 MLP 네트워크를 사용하여 연속적인 볼륨 장면을 나타내며 인상적인 렌더링 결과를 달성합니다.
NeRF를 도시 장면으로 확장하기 위한 일부 작업이 제안되었습니다 [9, 16, 18, 30, 32, 38, 43, 52, 55].
GridNeRF [66]은 NeRF가 대규모 장면에서 사실적인 결과를 생성하는 데 도움이 되는 멀티해상도 피쳐 평면을 제안합니다.
DNMP [32]는 포인트 클라우드를 복셀라이징하여 초기화된 변형 가능한 메쉬 프리미티브로 장면을 모델링합니다.
NeuRas [30]는 스캐폴드 메쉬를 입력으로 받아 신경 텍스처 필드를 최적화하여 빠른 래스터화를 수행합니다.
포인트 기반 렌더링 작업 [1,10,22,27,45]은 포인트 클라우드에서 학습된 신경 설명자를 정의하고 신경 렌더러를 사용하여 미분 가능한 래스터라이제이션을 수행합니다.
그러나 그들은 밀집된 포인트 클라우드를 입력으로 필요로 하며, 포인트 수가 적은 영역에서는 블러 결과를 생성합니다.
최근 연구인 3D Gaussian Splatting (3D GS) [19]는 3D 세계에서 이방성 가우시안 집합을 정의하고, 희소한 포인트 클라우드 입력만으로 고품질 렌더링 결과를 달성하기 위해 적응형 밀도 제어를 수행합니다.
그러나 3D GS는 장면이 정적이며 동적으로 움직이는 물체를 모델링할 수 없다고 가정합니다.
Dynamic scene modeling.
최근 방법들은 시간을 추가 입력으로 인코딩하여 단일 객체 장면에 4D 신경 장면 표현을 구축합니다 [2,13,26,28,29,40,41,50].
일부 작품에서는 optical flow [56] 또는 비전 트랜스포머 피쳐 [69]의 supervision 하에 야외 장면의 장면 분해를 학습합니다.
그러나 그들의 장면 표현은 인스턴스 인식이 되지 않아 자율 주행 시뮬레이션의 응용 분야가 제한됩니다.
또 다른 작품들은 장면을 움직이는 물체 모델과 배경 모델 [23, 39, 54, 64, 65, 71]의 구성으로 모델링하며, 이는 우리와 가장 유사합니다.
그러나 대규모 장면에서 높은 메모리 비용으로 인해 실시간 렌더링을 수행할 수 없습니다.
포인트 기반 렌더링을 동적 장면으로 확장하는 방법도 최근에 조사되었습니다 [68, 76].
최근 접근 방식은 변형 필드 [61,75], 물리적 prior [33] 또는 4D 매개변수화 [73]을 3D 가우시안 모델에 도입하여 3D GS를 소규모 동적 장면으로 확장합니다.
최근에는 일부 동시 작품 [8,79]에서도 도시 스트리트 장면에서 3D 가우시안을 탐구하고 있습니다.
Driving Gaussian [79]은 Incremental 3D Static Gaussians과 Composite Dynamic Gaussian Graphs를 소개합니다.
PVG [8]은 Periodic Vibration 3D Gaussians을 활용하여 동적 도시 장면을 모델링합니다.
Simulation environments for autonomous driving.
CARLA [11] 또는 AirSim [47]과 같은 기존 자율주행 시뮬레이션 엔진은 가상 환경을 만들기 위한 비용이 많이 드는 수작업과 생성된 데이터의 현실감 부족으로 어려움을 겪고 있습니다.
최근 몇 년 동안 실제 장면에서 포착된 자율 주행 데이터를 기반으로 센서 시뮬레이션을 구축하는 데 많은 노력이 기울여졌습니다.
일부 연구 [12, 34, 74]는 LiDAR를 집계하고 텍스처 프리미티브를 재구성하여 LiDAR 시뮬레이션에 집중합니다.
그러나 고해상도 이미지를 처리하는 데 어려움을 겪고 있으며 보통 노이즈가 많은 외관을 연출합니다.
다른 작품들 [7, 57, 72]은 다른 환경과 상호작용할 수 있는 멀티뷰 이미지와 LiDAR 입력으로부터 객체를 재구성합니다.
그러나 이러한 방법은 기존 이미지에 국한되어 새로운 뷰를 렌더링하는 데 실패합니다.
일부 방법은 신경망을 활용하여 뷰 합성 [17, 39, 71], 지각 [14, 23, 78], 생성 [25, 37, 48, 67, 70] 및 인버스 렌더링 [42, 58–60]을 포함한 다중 작업을 수행합니다.
그러나 그들은 높은 학습 및 렌더링 비용으로 어려움을 겪고 있습니다.
반면에, 우리의 방법은 자율 주행 시뮬레이션에 중요한 동적 도시 장면을 실시간으로 렌더링하는 데 중점을 둡니다.

3 Method
도시 스트리트 장면에서 움직이는 차량에서 촬영한 일련의 이미지를 고려할 때, 우리의 목표는 뷰 합성을 위한 사진사실적인 이미지를 생성할 수 있는 모델을 개발하는 것입니다.
이 objective를 향해, 우리는 동적 스트리트 장면을 표현하기 위해 특별히 설계된 Street Gaussians라는 새로운 장면 표현을 제안합니다.
그림 2에서 볼 수 있듯이, 우리는 동적 도시 장면을 정적 배경이나 움직이는 차량에 해당하는 포인트 클라우드 집합으로 표현합니다 (섹션 3.1).
명시적인 포인트 기반 표현은 별도의 모델을 쉽게 구성할 수 있게 하여 실시간 렌더링과 편집 애플리케이션을 위한 전경 객체의 분해를 가능하게 합니다 (섹션 3.2).
제안된 장면 표현은 우리의 포즈 최적화 전략에 의해 향상된 기성품 추적기에서 추적된 차량 포즈와 함께 효과적으로 학습될 수 있습니다 (섹션 3.3).
3.1 Street Gaussians
이 섹션에서는 실시간으로 빠르게 구성하고 렌더링할 수 있는 동적 장면 표현을 찾고자 합니다.
이전 방법 [23, 64]은 일반적으로 낮은 학습 및 렌더링 속도와 정확한 추적 차량 포즈로 인해 어려움을 겪습니다.
이 문제를 해결하기 위해, 우리는 3D 가우시안을 기반으로 한 새로운 명시적 장면 표현인 Street Gaussians를 제안합니다 [19].
Street Gaussians에서는 정적 배경과 각 움직이는 차량 객체를 별도의 신경 포인트 클라우드로 표현합니다.
다음에서는 먼저 배경 모델에 초점을 맞추어 객체 모델과 공유되는 몇 가지 일반적인 속성에 대해 자세히 설명하겠습니다.
그 후, 우리는 객체 모델 설계의 동적인 측면을 탐구할 것입니다.
Background model.
배경 모델은 월드 좌표계에서 포인트들의 집합으로 표현됩니다.
각 지점에는 연속적인 장면 지오메트리와 색상을 부드럽게 표현하기 위해 3D 가우시안이 할당됩니다.
가우시안 매개변수는 공분산 행렬 Σ_b와 평균값을 나타내는 위치 벡터 μ_b ∈ R^3으로 구성됩니다.
최적화 중 잘못된 값을 피하기 위해 각 공분산 행렬은 스케일링 행렬 S_b와 회전 행렬 R_b로 더 축소됩니다, 여기서 S_b는 대각선 요소로 특징지어지고 R_b는 단위 쿼터니언으로 변환됩니다.
공분산 행렬 Σ_b는 S_b와 R_b에서

로 복원할 수 있습니다.
위치 및 공분산 행렬 외에도 각 가우시안에는 장면 지오메트리 및 외관을 나타내기 위해 불투명도 값 α_b ∈ R과 구형 고조파 계수 z_b = (z_(m,l)) 세트가 할당됩니다.
뷰 의존 색상을 얻기 위해, 구면 고조파 계수에 뷰 방향에서 투영된 구면 고조파 basis 함수를 추가로 곱합니다.
3D 시맨틱 정보를 표현하기 위해 각 지점에는 시맨틱 로짓 β_b ∈ R^M이 추가됩니다, 여기서 M은 시맨틱 클래스의 수입니다.
Object model.
N개의 움직이는 전경 물체 차량이 포함된 장면을 고려해 보겠습니다.
각 객체는 최적화 가능한 추적 가능한 차량 포즈 세트와 포인트 클라우드로 표현되며, 각 포인트에는 3D 가우시안, 시맨틱 로짓 및 동적 외관 모델이 할당됩니다.
객체와 배경의 가우시안 속성은 유사하며, 불투명도 α_o와 스케일 행렬 S_o에 대해서도 동일한 의미를 공유합니다.
그러나 그들의 위치, 회전 및 외관 모델은 배경 모델과 다릅니다.
위치 μ_o와 회전 R_o는 객체 로컬 좌표계에서 정의됩니다.
이를 월드 좌표계 (배경 좌표계)로 변환하기 위해 객체에 대한 추적된 포즈의 정의를 소개합니다.
구체적으로, 차량의 추적된 포즈는 회전 행렬 {R_t}과 변환 벡터 {T_t}의 집합으로 정의되며, 여기서 N_t는 프레임의 수를 나타냅니다.
변환은

로 정의할 수 있으며, 여기서 μ_w와 R_w는 각각 월드 좌표계에서 해당 객체 가우시안의 위치와 회전을 나타냅니다.
변환 후, 객체의 공분산 행렬 Σ_w는 R_w와 S_o를 사용하여 식 1에 의해 구할 수 있습니다.
또한 기성품 추적기에서 추적된 차량 포즈가 노이즈가 있는 것을 발견했습니다.
이 문제를 해결하기 위해 추적된 차량 포즈를 학습 가능한 매개변수로 취급합니다.
섹션 3.3에서 자세히 설명합니다.

단순히 물체의 외관을 구형 고조파 계수로 표현하는 것만으로는 그림 3과 같이 움직이는 차량의 외관을 모델링하는 데 충분하지 않습니다, 왜냐하면 움직이는 차량의 외관은 전역 장면에서의 위치에 의해 영향을 받기 때문입니다.
간단한 해결책 중 하나는 각 시간 단계마다 객체를 나타내기 위해 별도의 구형 고조파를 사용하는 것입니다.
그러나 이 표현은 저장 비용을 크게 증가시킬 것입니다.
대신, 각 SH 계수 z_(m,l)를 푸리에 변환 계수 f ∈ R^k 세트로 대체하여 4D 구면 고조파 모델을 소개합니다, 여기서 k는 푸리에 계수의 수입니다.
주어진 시간 단계 t에서 z_(m,l)는 실수 값 Inverse Discrete Fourier Transform을 수행하여 복구됩니다:
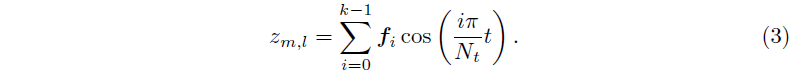
제안된 모델을 사용하면 높은 저장 비용 없이 시간 정보를 외관에 인코딩할 수 있습니다.
객체 모델의 시맨틱 표현은 배경과 다릅니다.
주요 차이점은 객체 모델의 시맨틱이 M차원 벡터 β_b 대신 트래커에서 차량 시맨틱 클래스를 나타내는 학습 가능한 1차원 스칼라 β_o라는 점입니다.
Initialization.
3D 가우시안에 사용되는 SfM [46] 포인트 클라우드는 객체 중심 장면에 적합합니다.
그러나 관찰이 부족하거나 질감이 없는 지역이 많은 도시 스트리트 장면에는 좋은 초기화를 제공할 수 없습니다.
대신 에고 차량에서 캡처한 집계된 LiDAR 포인트 클라우드를 초기화로 사용합니다.
LiDAR 포인트 클라우드의 색상은 해당 이미지 평면에 투영하고 픽셀 값을 쿼리하여 얻습니다.
객체 모델을 초기화하기 위해 먼저 3D 바운딩 박스 내부의 집계된 포인트를 수집하고 이를 로컬 좌표계로 변환합니다.
LiDAR 포인트가 2K 미만인 객체의 경우, 대신 3D 바운딩 박스 내부의 8K 포인트를 랜덤으로 샘플링하여 초기화합니다.
배경 모델의 경우, 남은 포인트 클라우드에 대해 복셀 다운샘플링을 수행하고 학습 카메라에 보이지 않는 포인트를 필터링합니다.
우리는 넓은 지역에서 LiDAR의 제한된 커버리지를 보완하기 위해 SfM 포인트 클라우드를 통합합니다.
3.2 Rendering of Street Gaussians
Street Gaussians을 렌더링하려면 각 모델의 기여도를 집계하여 최종 이미지를 렌더링해야 합니다.
이전 방법들 [23,39,64,71]은 신경망 표현 때문에 복잡한 raymarching을 사용한 합성 렌더링이 필요합니다.
대신 Street Gaussians은 모든 포인트 클라우드에 접촉하여 2D 이미지 공간에 투영하여 렌더링할 수 있습니다.
구체적으로, 렌더링된 시간 단계 t가 주어지면 먼저 식 3을 사용하여 구형 고조파를 계산하고, 추적된 차량 포즈 (R_t, T_t)에 따라 식 2를 사용하여 객체 포인트 클라우드를 월드 좌표계로 변환합니다.
그런 다음 배경 포인트 클라우드와 변환된 객체 포인트 클라우드를 연결하여 새로운 포인트 클라우드를 형성합니다.
이 포인트 클라우드를 카메라 extrinsic W와 intrinsic K를 사용하여 2D 이미지 공간에 투영하기 위해 포인트 클라우드의 각 포인트에 대한 2D 가우시안을 계산합니다 [80]:

, 여기서 J는 K의 야코비안 행렬입니다.
μ′와 σ′는 각각 2D 이미지 공간의 위치 행렬과 공분산 행렬입니다.
각 픽셀에 대한 포인트 기반 α-블렌딩은 색상 C를 계산하는 데 사용됩니다:

여기서 α_i는 불투명도 α에 2D 가우시안 확률을 곱한 값이고, c_i는 뷰 방향을 가진 구형 고조파 z에서 계산된 색상입니다.
깊이, 불투명도, 시맨틱과 같은 다른 신호도 렌더링할 수 있습니다.
예를 들어, 시맨틱 맵은 식 5의 색상 c를 의미 로짓 β로 변경하여 렌더링됩니다.
3D 가우시안은 유클리드 공간에서 정의되므로 하늘과 같은 먼 지역을 모델링하는 것은 부적절합니다.
그 결과, 우리는 뷰 방향을 하늘 색 C_sky로 매핑하는 고해상도 큐브맵을 활용합니다.
명시적인 큐브맵 표현은 추론 속도를 희생하지 않고도 하늘 영역의 세부 사항을 복구하는 데 도움이 됩니다.
최종 렌더링 색상은 방정식 5에서 C_sky와 C 색상을 혼합하여 얻습니다.
자세한 내용은 부록에서 확인할 수 있습니다.
3.3 Training
Tracking Pose Optimization.
섹션 3.2에서 렌더링하는 동안 객체 가우시안의 위치와 공분산 행렬은 식 2와 같이 추적된 포즈 매개변수와 밀접한 상관관계가 있습니다.
그러나 트래커 모델에서 생성된 바운딩 박스는 일반적으로 노이즈가 큽니다.
장면 표현을 최적화하기 위해 직접 사용하면 렌더링 품질이 저하됩니다.
그 결과, 각 변환 행렬에 학습 가능한 변환을 추가하여 추적된 포즈를 학습 가능한 매개변수로 취급합니다.
구체적으로, 식 2의 R_t와 T_t는

으로 정의된 R′_t와 T′_t로 대체되며, 여기서 ΔR_t와 ΔT_t는 학습 가능한 변환입니다.
우리는 ΔT_t를 3D 벡터로 나타내고, ΔR_i를 yaw 오프셋 각도 Δθ_t에서 변환한 회전 행렬로 나타냅니다.
이러한 변환의 그래디언트는 암시적 함수나 중간 과정 없이 직접 얻을 수 있으며, 역전파 중에 추가 계산이 필요하지 않습니다.
Loss function.
우리는 다음 loss 함수를 사용하여 장면 표현, 스카이 큐브맵 및 추적된 포즈를 공동으로 최적화합니다:

식 9에서 L_color는 [19] 이후 렌더링된 이미지와 관찰된 이미지 간의 재구성 loss입니다.
L_depth는 렌더링된 depth와 카메라 평면에 희소 LiDAR 포인트를 투사하여 생성된 depth 사이의 L1 loss입니다.
L_sky는 하늘 supervision을 위한 이진 크로스 엔트로피 loss입니다.
L_sem은 렌더링된 시맨틱 로짓과 입력된 2D 시맨틱 세그멘테이션 예측 [24] 사이의 픽셀당 소프트맥스 크로스 엔트로피 loss 옵션이며, L_reg는 플로터를 제거하고 분해 효과를 향상시키기 위해 사용되는 정규화 항입니다.
각 loss 항에 대한 자세한 내용은 보충 자료를 참조하시기 바랍니다.
4 Implementation details
우리는 3D 가우시안 [19]의 구성에 따라 Adam 옵티마이저 [20]를 사용하여 3만 번의 반복을 위해 Street Gaussians를 학습시킵니다.
이동 변환 ΔT_t와 회전 변환 ΔR_t의 학습률은 각각 5e^-5와 1e^-5로 지수적으로 감소하는 5e^-3과 1e^-3으로 설정됩니다.
스카이 큐베맵의 해상도는 1024로 설정되며, 학습률은 1e^-2에서 1e^-4로 지수적으로 감소합니다.
모든 실험은 하나의 RTX 4090 GPU에서 수행됩니다.
최적화 중에 적응형 제어를 적용하기 위해 [19]를 따릅니다.
우리는 배경 모델의 스케일 (실험에서 20미터)을 고정하고, 각 객체 모델의 스케일은 바운딩 박스 차원에 의해 결정됩니다.
객체 가우시안이 가려진 영역으로 성장하는 것을 방지하기 위해 각 객체 모델에 대해 확률 분포 함수로 포인트 집합을 샘플링합니다.
최적화 과정에서 바운딩 박스 외부의 샘플링된 점을 가진 가우시안은 프루닝됩니다.
5 Experiments
5.1 Experimental Setup
Datasets.
우리는 Waymo Open 데이터셋 [51]과 KITTI 벤치마크 [15]에 대한 실험을 수행합니다.
두 데이터셋의 프레임 속도는 10Hz입니다.
Waymo Open 데이터셋에서 우리는 많은 양의 움직이는 물체, 상당한 에고 차량 운동 및 복잡한 조명 조건을 가진 8개의 녹화 시퀀스를 선택합니다.
모든 시퀀스의 길이는 약 100프레임입니다.
시퀀스의 모든 4번째 이미지를 테스트 프레임으로 선택하고 나머지 이미지를 학습에 사용합니다.
고해상도 이미지로 학습할 때 기본 방법 [39,64]이 높은 메모리 비용을 겪는다는 것을 발견했기 때문에 입력 이미지를 1066×1600으로 축소했습니다.
KITTI [15]와 Vitural KITTI 2 [6]에서는 MARS [64]의 설정을 따르고 다양한 학습/테스트 분할 설정으로 방법을 평가합니다.
우리는 Waymo 데이터셋에서 검출기 [62]와 추적기 [63]에 의해 생성된 바운딩 박스를 사용하고, KITTI에서 공식적으로 제공된 객체 트랙렛을 사용합니다.
Baseline methods.
우리는 우리의 방법을 최근 네 가지 방법과 비교합니다.
(1) NSG [39]는 배경을 멀티 평면 이미지로 나타내며, 객체별로 학습된 잠재 코드를 공유 디코더와 함께 사용하여 움직이는 객체를 모델링합니다.
(2) MARS [64]는 Nerfstudio [53]을 기반으로 신경망 그래프를 구축합니다.
(3) 3D 가우시안 [19]은 이방성 가우시안 세트로 장면을 모델링합니다.
(4) EmerNeRF [69]는 장면을 정적 필드와 동적 필드로 계층화하며, 각 필드는 해시 그리드 [36]로 모델링됩니다.
NSG와 MARS는 모두 ground truth 객체 트랙렛을 사용하여 학습되고 평가됩니다.
기본 구현에 대한 자세한 내용은 부록에서 확인할 수 있습니다.


5.2 Comparisons with the State-of-the-art
표 1, 2는 렌더링 품질과 렌더링 속도 측면에서 기본 방법 [19,39,64,69]과의 비교 결과를 보여줍니다.
렌더링 품질을 평가하기 위해 PSNR, SSIM 및 LPIPS [77]를 지표로 채택합니다.
움직이는 물체의 렌더링 품질을 더 잘 평가하기 위해, 우리는 3D 바운딩 박스를 2D 이미지 평면에 투영하고 투영된 박스 내부의 픽셀에 대해서만 loss를 계산합니다, 이는 실험에서 PSNR*로 표시됩니다.
모든 지표에서 우리 모델은 PSNR*이 12.1% 증가하고 PSNR이 13.9% 증가하여 모든 방법 중에서 최고의 성능을 달성했습니다.
또한, 우리의 방법은 NeRF 기반 방법 [39,64,69]보다 두 배 빠른 속도를 제공합니다.
3D GS는 우리의 방법보다 빠르지만, 정적인 장면만 지원할 수 있고 움직이는 물체의 렌더링 결과가 크게 저하됩니다.

그림 4는 Waymo 데이터셋에 대한 우리의 방법과 베이스라인의 정성적 결과를 보여줍니다.
3D GS는 동적 객체를 모델링하지 못하며, EmerNeRF는 새로운 시간 단계의 동적 영역에서 합리적인 결과를 생성할 수 없습니다.
비록 실제 추적 포즈가 주어졌지만, NSG와 MARS는 장면이 복잡할 때 모델의 용량 부족으로 인해 여전히 블러하고 왜곡된 결과를 겪습니다.
반면에, 우리의 방법은 높은 충실도와 디테일로 고품질의 새로운 뷰를 생성할 수 있습니다.
5.3 Ablations and Analysis
우리는 Waymo 데이터셋에서 선택된 모든 시퀀스에 대해 알고리즘의 설계 선택을 검증합니다.
표 3은 정량적 결과를 보여줍니다.

Importance of optimizing tracked poses.
표 3의 실험 결과에 따르면, 우리의 완전한 모델이 추적 포즈 최적화 없이 학습된 모델보다 큰 차이로 뛰어나며, 이는 우리의 포즈 최적화 전략의 효과를 나타냅니다.
우리 방법의 결과가 실제 포즈로 학습된 모델보다 훨씬 더 뛰어나다는 점은 흥미롭습니다, 그럴듯한 설명은 실제 주석에 여전히 노이즈가 존재한다는 것입니다.

추적 포즈 최적화의 영향에 대한 시각적 결과는 그림 5에 나와 있습니다.
추적된 포즈를 학습 가능한 매개변수로 취급하면 객체 모델이 흰색 차량의 후면이나 검은색 차량의 로고와 같은 텍스처 세부 사항을 더 많이 합성하고 렌더링 아티팩트를 줄이는 데 도움이 됩니다.
Effectiveness of 4D spherical harmonics.
표 3의 결과는 4D 구형 고조파 외관 모델이 렌더링 품질을 개선할 수 있음을 나타냅니다.
이 상황은 그림 3과 같이 물체가 환경 조명과 상호작용할 때 특히 분명해집니다.
우리 모델은 자동차에 부드러운 그림자를 생성할 수 있지만, 4D 구형 고조파가 없는 렌더링 결과는 훨씬 더 노이즈합니다.
Influence of incorporating LiDAR points.
우리는 우리의 방법을 배경에 대한 SfM 초기화와 이동 객체에 대한 랜덤 초기화를 포함한 변형과 비교하여 LiDAR 포인트 클라우드의 영향을 평가합니다, 이는 섹션 3.1에서 설명한 바와 같습니다.
우리는 또한 식 9에서 LiDAR depth loss를 비활성화합니다.
표 3은 LiDAR 포인트 클라우드를 통합하면 배경 객체와 움직이는 객체의 결과가 모두 향상된다는 것을 보여줍니다.
그림 6은 LiDAR 포인트를 사용하면 모델이 더 정확한 장면 지오메트리를 복구하고 블러 아티팩트를 줄이는 데 도움이 된다는 것을 나타냅니다.
우리의 방법이 LiDAR 입력 없이도 여전히 기본 방법들을 크게 능가한다는 점은 주목할 만하며, 이는 다양한 설정에서 Street Gaussians의 효율성을 입증합니다.

5.4 Applications
Street Gaussians은 객체 분해, 시맨틱 세그멘테이션 및 장면 편집을 포함한 컴퓨터 비전의 여러 작업에 적용될 수 있습니다.
Scene editing.
인스턴스 인식 장면 표현은 다양한 유형의 장면 편집 작업을 가능하게 합니다.
우리는 차량의 방향을 회전시킬 수 있습니다 (그림 7 (a)), 차량을 이동시킬 수 있습니다 (그림 7 (b)), 그리고 현장에 있는 한 차량을 다른 차량으로 바꿀 수 있습니다 (그림 7 (c)).

Object Decomposition.
Waymo 데이터셋에서 NSG [39] 및 MARS [64]와 우리 방법의 분해 결과를 비교합니다.
그림 8에서 볼 수 있듯이 NSG는 전경 객체를 배경에서 분리하는 데 실패하고 모델 용량과 정규화 부족으로 인해 MARS의 결과가 블러합니다.
대조적으로, 우리의 방법은 높은 충실도와 깨끗한 분해 결과를 생성할 수 있습니다.

Semantic Segmentation.
우리는 렌더링된 시맨틱 맵의 품질을 KITTI 데이터셋에서 Video-K-Net [24]의 시맨틱 예측과 비교합니다.
우리의 시맨틱 세그멘테이션 모델은 비디오 K-Net의 결과를 바탕으로 학습되었습니다.
정성적 및 정량적 결과는 그림 9와 표 4에 나와 있습니다.
우리의 시맨틱 맵은 우리의 표현 덕분에 더 나은 성능을 달성합니다.


6 Conclusion
이 논문은 동적 도시 스트리트 장면을 모델링하기 위한 명시적인 장면 표현인 Street Gaussians를 소개했습니다.
제안된 표현은 배경 차량과 전경 차량을 각각 신경 포인트 클라우드로 모델링합니다.
이 명시적인 표현은 객체 차량과 배경을 쉽게 합성할 수 있게 하여, 학습 후 30분 이내에 장면 편집과 실시간 렌더링을 가능하게 합니다.
또한, 제안된 장면 표현이 기성 추적기의 포즈만을 사용하여 정확한 실제 포즈를 사용하여 달성한 것과 유사한 성능을 달성할 수 있음을 입증합니다.
여러 데이터 세트에 대한 상세한 ablation 및 비교 실험이 수행되어 제안된 방법의 효과를 입증합니다.