2025. 5. 12. 13:19ㆍView Synthesis
EventPS: Real-Time Photometric Stereo Using an Event Camera
Bohan Yu, Jieji Ren, Jin Han, Feishi Wang, Jinxiu Liang, Boxin Shi
Abstract
Photometric stereo는 물체의 표면 노멀을 추정하는 잘 확립된 기술입니다.
그러나 다양한 조명 조건에서 여러 개의 높은 동적 범위 이미지를 캡처해야 하는 요구 사항은 속도와 실시간 응용 프로그램을 제한합니다.
이 논문은 이벤트 카메라를 사용하여 실시간 photometric stereo에 대한 새로운 접근 방식인 EventPS를 소개합니다.
이벤트 카메라의 뛰어난 시간 해상도, 동적 범위, 낮은 대역폭 특성을 활용하여, EventPS는 래디언스 변화만으로 표면 노멀을 추정하여 데이터 효율성을 크게 향상시킵니다.
EventPS는 최적화 기반 및 딥러닝 기반 photometric stereo 기술과 원활하게 통합되어 non-Lambertian 표면에 대한 강력한 솔루션을 제공합니다.
광범위한 실험을 통해 EventPS의 효과와 효율성이 프레임 기반 모델과 비교하여 입증되었습니다.
우리 알고리즘은 실제 시나리오에서 30fps 이상의 속도로 실행되며, 시간 민감하고 고속 다운스트림 애플리케이션에서 EventPS의 잠재력을 발휘합니다.
1. Introduction
Photometric Stereo (PS) [53]는 다양한 방향에서 조명된 물체의 이미지를 분석하여 표면 노멀의 방향을 추정하는 기술로, 특히 제어된 조명 조건에서 고해상도와 정밀한 표면 세부 사항을 재구성할 수 있는 능력이 특징입니다.
그림자, 반사경, 다양한 유형의 노이즈와 같은 이상적인 Lambertian 이미지 형성 모델과의 편차로 인해 전통적인 Frame-based PS (FramePS)에서 견고한 노멀 추정을 달성하는 것은 복잡하고 시간이 많이 소요됩니다 [17].
그림 1 (f)에 나타난 바와 같이, 일반적으로 이 과정은 여러 개의 순차적으로 조명된 원거리 광원 (예: 약 100개의 조명 [40, 45])의 조명 아래 고정 카메라를 사용하여 일련의 노출 브래킷 이미지를 캡처해야 합니다.
이 힘든 과정은 PS의 실시간 적용을 방해합니다.
최근 실시간 PS를 추진하려는 노력은 두 가지 범주로 나뉩니다.
한 그룹의 방법은 멀티-스펙트럼 카메라를 사용하여 다양한 방향의 멀티-스펙트럼 조명 조건에서 객체의 관측을 동시에 얻습니다 [4, 8, 10, 23–25, 30, 36, 47].
싱글 샷 데이터 캡처 과정에도 불구하고 조명과 물체의 색상 간의 모호성은 노멀 추정에 어려움을 초래합니다.
또 다른 방향은 신중하게 제어된 광원과 동기화된 고속 카메라를 포함하며, 이는 이미지 캡처 과정을 가속화하는 것을 목표로 합니다 [5, 32, 49].
그러나 이 설정은 카메라와 실험 시설에서 높은 데이터 처리량 능력을 요구하며, 이는 특히 제한된 전력과 비용으로 인해 실시간 응용 프로그램에서 실질적인 구현에 장애가 됩니다.
이벤트 카메라는 높은 시간 해상도, 높은 동적 범위, 낮은 대역폭 요구 사항으로 특징지어지며, 최근 실시간 비전 애플리케이션을 위한 유망한 솔루션으로 인정받고 있습니다 [6].
전통적인 프레임 기반 카메라와 달리 이벤트 카메라는 로그 장면 래디언스 변화만 기록합니다.
이 특성은 많은 시나리오에서 유리합니다.
예를 들어, 구조화된 빛 아래에서 멀티뷰 스테레오 [38] 또는 3D 재구성을 위한 시간적 대응과 공간적 격차를 신속하게 설정합니다 [33, 34].
그러나 절대값 대신 래디언스 변화의 특성은 FramePS 문제에서 벗어납니다.
how to effectively utilize the unique attributes of event cameras for real-time PS에 대한 탐구는 여전히 미해결 과제로 남아 있습니다.

이 논문에서는 이벤트 카메라의 유리한 특성에 맞춘 다양한 조명 조건에서의 장면 래디언스 변화만으로 도출된 관측값에 PS 문제를 재구성하는 방법을 제안합니다.
그림 1 (a)에 표시된 것처럼 물체는 지속적으로 래디언스 변화를 유도하고 이벤트 신호를 트리거하는 고속 회전 광원 (분당 최대 1800회 회전, rpm)에 의해 조명됩니다.
각 이벤트는 트리거 타임스탬프의 조명 방향과 관련이 있습니다 (그림 1 (b)).
Lambertian 반사율 모델을 가정하면 (이 가정은 나중에 공개할 것입니다), 각 연속 이벤트 쌍은 표면 노멀에 직교하는 벡터인 "null space vector"로 변환됩니다 (그림 1 (c)).
각 픽셀의 표면 노멀은 모호성 없이 최소 두 개의 선형 독립적인 null 공간 벡터로부터 결정됩니다 (그림 1 (d)).
이벤트 카메라의 고유한 특성 덕분에 이 과정을 통해 빠르게 변화하는 조명 아래에서 높은 동적 범위의 관측 데이터를 포착하면서 경제적인 데이터 효율성을 유지할 수 있습니다.
EventPS라고 불리는 이 접근 방식은 이벤트 카메라의 고유한 강점을 활용하여 실시간 PS를 달성할 수 있게 해줍니다.
이벤트가 노이즈가 있는 실제 장면의 경우, 모든 null 공간 벡터를 사용하여 최소 제곱 최소화 문제를 해결함으로써 표면 노멀을 더 견고하게 얻을 수 있습니다.
Singular Value Decomposition (SVD) [7]을 EventPS와 통합함으로써, 우리의 방법은 노멀 추정에서 특히 초당 30프레임 (fps)을 달성합니다.
또한, non-Lambertian 표면을 처리하는 데 내재된 어려움을 인정하여, 우리는 EventPS 공식에 따라 딥러닝 변형 [2, 13]을 제안합니다.
우리는 우리 접근 방식의 실현 가능성을 입증하고 실시간 3D 재구성과 같은 고속 시간 민감 애플리케이션에서 EventPS의 잠재력을 강조하는 맞춤형 검증 플랫폼을 개발합니다.
실험 결과, EventPS는 대역폭의 31%만을 사용하면서도 FramePS의 성능과 일치하는 것으로 나타났으며, 이는 그 효과와 효율성을 입증하는 증거입니다.
우리 작업의 주요 기여는 다음과 같이 요약됩니다:
• 우리는 이벤트 카메라가 기록한 조명에 대한 연속적인 래디언스 변화로부터 표면 노멀을 추정할 수 있다는 것을 최초로 공식화했으며, 이는 FramePS에 비해 상당한 대역폭 감소를 달성합니다.
• 우리는 Lambertian 곡면과 non-Lambertian 곡면을 처리하기 위해 최적화 기반 및 딥러닝 기반 접근 방식과 통합된 EventPS를 제안합니다.
• 고속 회전 광원을 갖춘 검증 플랫폼을 구축하여 제안된 EventPS가 실시간으로 30fps 출력으로 표면 노멀을 추정한다는 것을 보여줍니다.
2. Related Works
2.1. Photometric Stereo Methods
PS가 1980년대에 제안된 이후 [53] 성능을 향상시키기 위해 최적화 기반 방법과 딥러닝 기반 방법이 모두 제안되었습니다.
대부분의 대표적인 최적화 기반 방법들은 [45]에서 종합적으로 논의되었으므로, 다음 부분에서는 딥러닝 기반 솔루션을 검토하는 데 중점을 둡니다.
최근 PS 방법들은 주로 딥러닝 기반 접근 방식을 채택하고 있으며, 이는 두 가지 범주로 나뉩니다: 전체 픽셀 및 픽셀당 [56].
전채 픽셀 방법 [2, 3]은 관찰된 이미지와 빛의 방향에서 얻은 전역 정보를 결합한 반면, 픽셀당 방법 [13, 43, 55]은 다양한 빛의 방향에서 각 픽셀의 관측값을 사용하여 표면 노멀을 추정했습니다.
딥러닝 기반 PS 방법의 성능을 향상시키기 위해 연구자들은 픽셀당 방법과 전체 픽셀 방법의 장점을 결합했습니다 [54],
전역 조명을 모델링하기 위해 관측 지도를 보강하고 역방향 렌더링을 활용하여 표면 법선을 추정했습니다 [26, 48].
또한, 어텐션 기반 가중치 [20, 22], 트랜스포머 [14], 미분 가능 모델링 [27]과 같은 현실적인 복잡성을 처리하기 위해 고급 학습 모델과 기법 [21]도 도입되었습니다.
또한 일반 조명 및 기능 표현 [15]은 딥러닝 기반 PS를 재구성하여 3D 스캐너 [16]와 비슷한 성능을 달성했습니다.
그러나 여전히 다양한 조명 아래에서 상당한 수의 이미지가 필요합니다.
직렬화된 캡처 프로세스는 동적 시나리오에서 PS 적용을 상당히 제한합니다.
PS의 이미징 프로세스를 가속화하는 핵심은 고속 카메라와 동기화된 조명을 사용하여 관찰 프로세스를 최적화하는 데 있습니다 [46].
그러나 프레임 속도가 증가함에 따라 비용이 크게 증가합니다.
다른 연구자들은 싱글 샷으로 다양한 방향 조명 하에서 물체를 관찰할 수 있도록 멀티 스펙트럼 이미징 시스템을 도입하여 PS의 효율성을 크게 향상시켰습니다 [25, 36, 47].
그러나 밴드 수, 크로스토크 및 강도 불일치 (예: 미지의 조명, 표면 반사율, 카메라의 스펙트럼 응답)와 같은 멀티 스펙트럼 카메라의 한계는 표면 노멀 추정에 추가적인 도전 과제를 제기합니다 [19].
2.2. Event Camera based 3D Reconstruction
이벤트 카메라는 카메라/물체의 움직임이나 조명 변화로 인해 발생할 수 있는 장면의 광채 변화를 감지합니다.
관련 연구를 두 가지 범주로 나눕니다: 모션 기반 및 액티브 조명 기반 방법.
모션 기반 방법의 경우, EMVS [38]과 EvAC3D [51]은 개별 이벤트를 ray로 처리하여 반밀도 3D 구조와 알려진 궤적을 가진 이벤트 카메라의 객체 메시를 추정했습니다.
또한, 이벤트 기반 neural radiance fields (NeRF) [1, 12, 29, 31, 37, 41]는 높은 시간 해상도로 이벤트 신호를 활용하여 볼륨 장면 표현을 구성하는 중요한 돌파구로 떠올랐습니다.
이벤트 기반 SLAM 방법에 대한 요약은 종합 서베이 [11]를 참조하시기 바랍니다.
액티브 조명 기반 방법을 위해 연구자들은 구조화된 빛 [33, 34]을 적용하여 프로젝터와 이벤트 카메라 간의 시공간 상관관계를 최대화하여 depth 감지를 수행했습니다.
EFPS-Net [42]은 희소 이벤트 관측 맵을 보간하고 이를 RGB 이미지와 통합하여 주변 조명 하에서 표면 노멀 맵을 예측했습니다.
전역 조명 변화 (예: 암실에서 불을 켜거나 회전 편광판을 사용하여 등좌표를 재구성하거나 표면 노멀을 추정하는 방법)도 있습니다 (예: 암실에서 불을 켜거나 회전 편광판을 사용하는 방법 [35]).
3. Proposed Method
3.1. Problem Formulation
Photometric stereo.
이상적인 원거리 광원에 의해 조명된 물체를 가정할 때, 광원의 래디언스는 일정하며 방향은 시간 t에 대한 정규화된 조명 벡터 함수 L(t)로 설명됩니다.
노멀 벡터 n_x와 확산 알베도 a_x를 가진 이미지 좌표 x = (x, y)의 픽셀에 대해, Lambertian 가정 하에, 이 픽셀 ˆ I_x(t)의 반사된 래디언스는
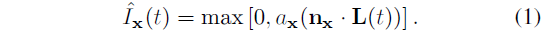
입니다.
Event formation model.
이벤트 카메라는 로그 스케일로 장면의 래디언스 변화를 포착합니다.
각 픽셀은 비동기적으로 변화하는 래디언스를 측정합니다.
픽셀 x에서 로그 래디언스의 변화가 트리거 임계값 C에 도달하면 이벤트 {x, p, t}가 트리거됩니다, 여기서 t는 타임스탬프이고, p ∈ {-1,+1}은 래디언스의 감소 또는 증가를 나타내는 극성입니다.
짧은 시간 동안 픽셀 x에서 완전히 K개의 이벤트가 발생한다고 가정해 보겠습니다.
이 이벤트들은 E_x = {x, p_k, t_k}로 표현되며, 여기서 k = {1, 2, ...,K}입니다.
픽셀 x의 래디언스 값이 t_(k-1)에서 t_k로 변화하면

가 됩니다, 여기서 ϵ은 0의 로그를 취하지 않기 위한 작은 오프셋 값이고, η는 픽셀의 굴절 시간입니다 [6].
식 (2)에서 오프셋 값과 불응 시간을 생략하고 양쪽에서 지수화를 수행하면 다음과 같은 식을 얻을 수 있습니다:

식 (1)을 식 (3)에 대입하면, 우리는

를 얻습니다.
픽셀 x와 조명 방향 L(t)에서 캡처된 이벤트 E_x를 고려할 때, 우리의 목표는 가능한 한 n_x에 가까운 픽셀 x에서 표면 노멀 ˆ n_x를 추정하는 다음 함수 f를 찾는 것입니다:

3.2. EventPS Model
이 하위 섹션에서는 이상적인 이벤트 트리거 메커니즘을 사용하여 이벤트 카메라에 포착된 Lambertian 표면을 가진 정적 객체에서 시작하여 EventPS 모델이 어떻게 작동하는지 설명합니다.
다음 하위 섹션 (섹션 3.3 및 섹션 3.4)에서 EventPS 모델을 기반으로 제안된 알고리즘은 실제 시나리오 (일반적인 BRDF, 노이즈 이벤트 및 동적 장면)에서 모든 비이상적인 효과를 다룹니다.

그림 2에서 볼 수 있듯이 PS 설정에서 트리거된 이벤트 신호에는 EventPS를 가능하게 하는 세 가지 속성이 있습니다:
Observation 1: Albedo invariance.
이벤트 신호는 표면 알베도 a_x와 무관합니다.
식 (4)의 양쪽에 a_x가 있으므로, 우리는 a_x를 제거합니다.
이는 조명 방향이 동일하게 변경되더라도 표면 알베도가 이벤트 트리거에 영향을 미치지 않는다는 것을 의미합니다.
따라서 식 (4)는

과 같이 단순화할 수 있습니다.
Observation 2: No events in attached shadow.
식 (2)에서 우리는 I_x(t_k)의 도함수가 t_k에서 0이 아니어야 한다고 추론합니다.
그렇지 않으면 이벤트가 트리거되지 않습니다.
이 속성은 이벤트 신호에 첨부된 그림자 영역의 픽셀에 대한 중복 정보가 포함되어 있지 않으며, 이벤트 타임스탬프 t_k에서 ˆI가 0보다 커야 함을 나타냅니다.
따라서 식 (6)의 양쪽에서 max 연산자를 제거하고

을 구합니다.
각 픽셀에 대해 연속적인 이벤트 신호 쌍을 이 픽셀에서 객체 표면의 접평면에 있는 벡터로 변환합니다, 벡터는 표면 법선에 수직입니다.
우리는 이 벡터들을 null 공간 벡터라고 부르며, 이 벡터들은 z_k로 표현됩니다, 여기서 k = {1, 2, ..., K - 1}:

식 (7)과 식 (8)을 결합하여 null 공간 벡터가 표면 법선, 즉 {z_1, z_2, ..., z_(K-1)} ⊥ n_x에 수직임을 확인합니다.
Observation 3: Linear-independent null space vectors.
각 픽셀의 표면 법선을 결정하려면 선형적으로 독립적인 최소 2개의 널 공간 벡터가 필요합니다.
모든 널 공간 벡터가 선형적으로 상관되어 있다면, 모든 널 공간 벡터에 수직인 무한한 표면 법선 벡터가 존재할 것입니다.
각 라운드에서 볼록 곡선을 스캔 패턴으로 적용할 때, 이 곡선의 어떤 3개 점도 같은 선에 있지 않으므로 모든 널 공간 벡터가 선형적으로 의존해서는 안 됩니다:

따라서 각 픽셀에 대해 2개의 널 공간 벡터를 얻은 한 접평면을 결정한 다음 해당 픽셀에서 고유한 표면 법선을 계산할 수 있습니다.

우리는 EventPS 공식의 유효성을 검증하기 위해 그림 3의 두 가지 예를 사용합니다.
(a)의 경우, 우리는 Lambertian 곡면과 이상적인 이벤트 트리거링 모델이 있는 구의 한 점을 보여줍니다.
우리는 식 (8)에서 계산된 양의 영공간 벡터와 음의 영공간 벡터를 시각화합니다.
그림 3 (a)에서 시각화된 바와 같이, 모든 널 공간 벡터는 접선면 (회색 투명 평면)에 완벽하게 놓여 있으며, 이는 고유한 법선 방향 (노란색 화살표)을 결정합니다.
(b)의 경우, 실제 이벤트 카메라로 포착된 non-Lambertian 표면을 사용한 시나리오를 보여줍니다 (실험 설정에 대한 자세한 내용은 섹션 4.1에서 소개될 예정입니다).
그림 3 (b)에서 시각화된 바와 같이, 비이상적인 반사율 모델과 노이즈 이벤트로 인한 오프셋이 있더라도 널 공간 벡터는 여전히 접평면 주변에 있습니다.

표면 법선이 이벤트 신호의 프로파일로 명확하게 설명될 수 있음을 보여주기 위해 그림 4에 예시를 제시합니다.
우리는 빛의 방향을 따라 4개의 점을 사용하여 빛의 방향으로 회전하면서 발생하는 빛의 변화와 이벤트 신호를 그래프로 그립니다.
광원이 azimuth 각 ϕ_L을 0˚에서 360˚까지 쓸어가며 회전할 때, 파란색, 주황색, 초록색 점들의 래디언스가 감소합니다.
빨간 점은 표면 법선 azimuth 각의 차이로 인해 90˚ 지연이 발생합니다.
elevation 각도가 증가함에 따라 (파란색-주황색-녹색 점), 래디언스의 변화가 더 부드러워지고 이벤트가 발생하는 횟수가 단조롭게 감소합니다.
각 지점에서 패턴을 유발하는 고유 이벤트 (즉, 타임스탬프 및 숫자)는 래디언스 변화를 명확하게 반영합니다.
따라서 모호함 없이 이벤트 신호만으로 각 지점에서 노멀 벡터를 직접 얻을 수 있습니다.
다음으로, 노이즈가 있는 널 공간 벡터로부터 표면 법선을 견고하게 추정하기 위해 최적화 기반 및 딥러닝 기반의 EventPS 솔루션을 소개하겠습니다.
3.3. EventPS by Optimization
각 픽셀에 대해 모든 널 공간 벡터를 3 × (K - 1) 행렬 Z_x로 결합합니다.
이론적으로 표면 법선 추정을 위해 rank-2 행렬 Z_x를 얻으려면 최소 3개의 이벤트가 필요합니다.
충분한 이벤트 (즉, K > 3)가 주어졌을 때, 우리는 다음 mean square error (MSE)를 최소화하기 위해 표면 법선 ˆn_x를 추정하는 최적화 타겟을 정의합니다:

이 최적화 문제는 SVD로 해결됩니다.
행렬 Z_x Z_x^T의 가장 작은 고유값에 해당하는 고유 벡터를 계산한 다음 표면 법선 ˆ n_x를 얻습니다.
이 방법을 Event Photometric Stereo OPtimization (EventPS-OP)라고 명명합니다.
벤치마크 [44]에서 가장 밝은 영역 (스펙티브 하이라이트에서 가장 가능성이 높은 영역)과 가장 어두운 영역 (첨부/캐스트 섀도우에서 가장 가능성이 높은 영역)을 필터링하는 임계값을 추가하면 최소 제곱으로 해결된 PS 정확도가 효과적으로 향상된다는 것이 확인되었습니다 [45].
EventPS에서는 절대 래디언스 정보가 부족하기 때문에 이벤트 신호에 이러한 임계값을 추가하기가 어렵습니다.
그러나 대비가 높은 강도 변화가 관찰될 때 이벤트는 높은 빈도로 트리거됩니다.
PS 설정에서는 일반적으로 포인트가 그림자 경계 (공격된 그림자 및 캐스트 그림자 포함) 또는 특정 하이라이트를 넘을 때 발생합니다.
이벤트 트리거 빈도에 임계값을 설정하면 주파수 영역에서 최소 제곱 방법에 임계값을 추가하는 것과 유사한 목표를 달성할 수 있습니다.
필터링된 널 공간 벡터 ˆZ는

이며, 여기서 δ는 시간 임계값이고 δ ≥ η입니다.
δ가 클수록 이 필터에 의해 더 많은 널 공간 벡터가 제거되어 EventPS-OP 알고리즘에 대한 필터링이 더 엄격해집니다.
3.4. EventPS by Deep Learning
FramePS에서 딥러닝 기반 방법 [2, 13]은 대규모 합성 학습 데이터셋에서 이전에 학습한 덕분에 그림자, 반사, 상호 반사에 대해 더 높은 견고성을 보여줍니다.
EventPS의 견고성과 일반화를 개선하기 위해 PS-FCN [2]과 CNN-PS [13]이라는 두 가지 프레임 기반 딥러닝 방법을 이벤트 신호의 모달리티에 적용합니다.

원본 PS-FCN [2]은 특정 조명 하에서 각 개별 이미지에 컨볼루션 레이어를 적용하고 맥스 풀링을 통해 여러 이미지 피쳐를 병합합니다.
그림 5에 나타난 바와 같이, 우리는 픽셀 내 관계를 유지하기 위해 널 공간 벡터 이미지를 입력으로 구성하여 이벤트 모달리티 (EventPS-FCN으로 명명)에 PS-FCN [2]를 적용합니다.
먼저 관심 있는 스캔 시간 (일반적으로 전체 원)을 N개의 빈으로 나눕니다.
이벤트는 식 (8)을 사용하여 영공간 벡터로 변환됩니다.
널 공간 벡터 이미지는 각 시간 빈 내에 각 픽셀의 모든 널 공간 벡터를 합산하여 형성되며, 이들은 빛의 방향 변화를 공유합니다.
우리는 피쳐 추출을 위해 각 널 공간 벡터 이미지에 광 방향 ˆL_i 채널을 추가하여 원래의 PS-FCN [2] 설계를 따릅니다.
이벤트 피쳐가 이미지 피쳐보다 훨씬 드물고 인접한 시간대 간의 차이가 뚜렷하지 않기 때문에, 인접한 시간대의 이벤트에서 시간적 피쳐를 추출하기 위해 두 개의 시간 컨볼루션 레이어를 추가합니다.
그런 다음 모든 빈의 피쳐를 맥스 풀링하여 표면 법선을 추정합니다.

원본 CNN-PS [13]은 각 픽셀에서 32×32 관측 맵을 추출하고 이러한 관측 맵에 컨볼루션 레이어를 적용하여 각 픽셀을 개별적으로 처리합니다.
마찬가지로, 제안된 EventPS 공식을 사용하여 이벤트 신호에서 널 공간 벡터로 변환하는 작업도 픽셀 단위로 수행됩니다.
그림 6에 나타난 바와 같이, 우리는 관찰 맵의 정의를 수정하여 원래의 CNN-PS [13]을 이벤트 모달리티 (EventPS-CNN으로 명명)에 맞게 조정합니다.
이벤트 관측 맵에서는 채널 수를 1 (회색 스케일 이미지)에서 3 (null 공간 벡터의 x, y, z 축)으로 늘립니다.
각 픽셀은 해당 조명 방향에서 널 공간 벡터를 나타냅니다.
이러한 방식으로 각 픽셀의 모든 널 공간 벡터가 이 이벤트 관측 맵에 모여 원래 CNN-PS [13] 모델에 입력됩니다.
EventPS-FCN의 타임 빈과 비교했을 때, 관측 맵에는 각 픽셀에 대한 더 많은 정보가 포함되어 있습니다.
그 결과, 각 개별 널 공간 벡터에 대한 더 많은 세부 정보가 EventPS-CNN에 보존됩니다.
4. Experiment
4.1. Implementation Details
Algorithms implementation.
우리 방법의 실시간 성능을 입증하기 위해, 우리는 Rust와 OpenCL로 작성된 GPU 가속을 사용하여 이벤트 전처리 부분 (EventPS-OP, EventPS-FCN, EventPS-CNN용)과 SVD 부분 (EventPS-OP 전용)을 구현합니다.
우리는 EventPS-OP를 위한 비동기식 파이프라인을 구현하여 최신 들어오는 이벤트를 지속적으로 업데이트하여 지연 시간을 줄이고, EventPS-FCN과 EventPS-CNN이 더 나은 품질을 위해 모든 이벤트를 대기하고 처리할 수 있도록 합니다.
EventPS-FCN 신경망은 PyTorch를 사용하여 원래 PS-FCN [2]의 체크포인트로 파인튜닝되고 평가됩니다.
EventPS-CNN의 경우, 원래 CNN-PS [13]와 유사한 PyTorch 버전을 구현하여 처음부터 학습합니다.
더 자세한 내용은 공개된 소스 코드에서 확인할 수 있습니다 (본 논문이 수락되면).
Validation platform.
실제 물체에서 알고리즘의 성능을 검증하기 위해 고속 조명 및 캡처 검증 플랫폼을 설계했습니다.
수트 내 리튬 이온 배터리로 구동되는 녹색 LED 광원이 있습니다.
LED는 회전축에 장착되어 최대 1800 rpm의 DC 모터가 장착된 동기식 벨트 휠 시스템에 의해 구동되며, 고속 "circle" 스캐닝 패턴을 형성합니다.
홀 효과 각도 센서가 설치되어 LED 위치를 감지하고, 이를 동기화하기 위해 이벤트 카메라로 전송합니다.
우리는 회전 중 이벤트 신호를 포착하기 위해 IMX636 센서가 장착된 Propredsee EVK4 HD 카메라를 사용합니다.
두 가지 "contrast sensitivity threshold biases"는 -20으로 설정되며, "dead time bias"는 -20으로 설정되어 약 580 μs의 불응 시간을 초래합니다.
4.2. Datasets
Synthetic dataset.
딥러닝 기반 알고리즘을 체계적이고 제어 가능한 비교를 위해 학습시키기 위해 합성 데이터셋을 렌더링하고 시뮬레이션된 이벤트 스트림을 생성하는 파이프라인을 구축했습니다.
우리는 Blobby 데이터셋 [18]에서 모든 객체와 Sculpture 데이터셋 [52]에서 15개의 객체를 선택합니다.
각 객체에 대해 이전 딥러닝 기반 PS 방법 [2, 13]과 유사한 랜덤 변환 및 랜덤 BRDF 텍스처를 추가합니다.
우리는 합성 데이터셋에서 조명을 위해 세 가지 유형의 스캐닝 패턴을 선택합니다: 기계적 타당성을 나타내는 "circle", 사각지대를 피하기 위한 "hypotrochoid", 그리고 다음 세미-리얼 데이터셋의 호환성을 나타내는 "DiLi-GenT".
그런 다음 랜덤 매개변수가 있는 스캐닝 패턴을 선택하고 ray-tracing 렌더러를 사용하여 회전 조명 아래에서 6라운드 동안 600개의 고밀도 이미지를 렌더링합니다.
이 이미지들은 이벤트 시뮬레이터 ESIM [39]을 사용하여 이벤트 스트림으로 변환됩니다.
Semi-real dataset.
FramePS [40, 45, 50]의 인기 있는 실제 데이터셋에는 여러 개별 조명 방향으로 캡처된 이미지만 포함되어 있습니다.
우리는 DiLiGenT 데이터셋 [45]에서 가장 바깥쪽 경계 조명 방향의 이미지를 선택하고, 이를 이벤트 시뮬레이터 [39]를 사용하여 이벤트 스트림으로 변환하여 DiLiGenT-Ev라는 세미-리얼 데이터셋을 생성합니다.
Real dataset.
제안된 EventPS 방법의 성능을 검증하기 위해, 우리는 5개의 객체를 제작하고 실제 데이터셋을 ground truth 노멀 맵으로 캡처합니다.
실제 데이터셋은 단순 지오메트리 (BALL), 공간적으로 변하는 알베도 (BALCVR), 그리고 중간 정도의 세부 사항 (BUNNY)과 복잡한 세부 사항 (HORSE, TIGER)을 포함합니다.
각 객체는 더 나은 품질을 위해 암실에서 240rpm으로 회전하는 검증 플랫폼을 사용하여 캡처됩니다.
4.3. Comparison with FramePS
우리는 제안된 EventPS를 DiLiGenTEV 데이터셋에서 FramePS와 정량적 비교를 수행합니다.
이벤트 입력과 프레임 입력에 필요한 데이터 전송률을 계산하기 위해 이벤트 스트림이 16비트 Prophesee EVT 3.0 형식을 사용한다고 가정하고, 프레임 이미지는 3개의 노출 괄호가 있는 8비트 그레이 스케일 이미지로 캡처합니다.
세 가지 FramePS 알고리즘, 즉 TH28 [45] ([20%, 80%] 임계값을 가진 최소 제곱 방법, EventPS-OP 대응), CNN-PS [13] (EventPS-CNN 대응), PS-FCN [2] (EventPS-FCN 대응)에 대해, 우리는 DiLiGenT 데이터셋 [45]에서 96개의 빛 방향 중에서 랜덤으로 이미지를 선택합니다.
세 가지 EventPS 알고리즘에 대해 각 장면마다 서로 다른 수의 이벤트가 생성됩니다.
Mean Angular Error (MAE)와 데이터 속도 비교는 표 1에 나와 있습니다.
평균적으로 EventPS는 필요한 데이터 전송률을 약 25.9% (EventPS-OP의 경우), 39.8% (EventPS-FCN의 경우), 26.6% (EventPS-CNN의 경우)로 줄입니다.


그림 7에서 볼 수 있듯이, FramePS는 입력 이미지의 수가 증가함에 따라 데이터 전송률이 선형적으로 증가하고 정상 MAE가 감소하는 것을 보여줍니다.
반면에, 제안된 EventPS는 일정한 데이터 전송률과 MAE를 가지고 있습니다.
각 알고리즘에 대해 데이터 전송률의 교차점은 왼쪽에 있고, MAE의 교차점은 오른쪽에 있습니다.
이는 EventPS가 더 나은 데이터 효율성으로 더 작은 MAE를 달성한다는 것을 나타냅니다.
정성적 평가를 위해 그림 8에 제안된 EventPS의 오류 분포가 객체 전반에 걸쳐 고르게 분포되어 있음을 나타내는 세 가지 객체 예제를 보여줍니다.



4.4. Evaluation on Real Camera
Results on static objects.
우리는 실제 데이터에서 EventPS의 성능을 평가합니다.
결과는 표 2에 나와 있습니다.
평균적으로 EventPS는 18.8 (EventPS-OP의 경우), 14.7 (EventPS-FCN의 경우), 17.6 (EventPS-CNN의 경우)의 MAE를 달성하여 PS에 이벤트 신호만 활용하는 효과를 입증했습니다.
그림 9에 3개의 객체 예제와 노멀 추정 결과를 보여줍니다.
왼쪽 예시는 공간적으로 변화하는 알베도를 가진 공을 보여줍니다.
캡처된 이벤트 신호와 추정된 노멀 맵에서 "CVPR" 단어를 거의 볼 수 없으며, 이는 EventPS의 "albedo invariance" 속성을 보여줍니다.
MAE는 일반적인 추정 결과의 경계에서 더 높은데, 이는 근조도 효과 (약 12cm의 빛-물체 거리)와 거칠게 정렬된 조명 때문입니다.

Results on dynamic objects.
실제 시나리오에서 동적 객체에 EventPS 모델을 적용하기 위해 모든 널 공간 벡터에 지수적으로 감소하는 가중치를 추가하여 최신 이벤트의 우선순위를 정합니다.
그림 10에서는 검증 플랫폼을 사용하여 (a) 손가락과 (b) 고무 장난감의 실시간 PS를 보여줍니다 (가장 낮은 지연 시간을 위해 1800rpm으로 최대 속도로 회전).
지문과 고무 변형과 같은 세밀한 세부 사항을 실시간으로 확인할 수 있으며, 이는 EventPS가 세밀한 세부 사항을 복구하는 데 있어 우수함을 보여줍니다.
EventPS 알고리즘의 처리 속도는 1000fps 이상 (EventPS-OP의 경우), 약 2fps (EventPS-FCN의 경우), 약 0.1fps (EventPS-CNN의 경우)입니다.
5. Conclusion and Discussion
이 논문에서는 단일 이벤트 카메라를 사용하는 새로운 실시간 PS 접근 방식인 EventPS를 제안합니다.
우리의 방법은 속도와 데이터 효율성의 놀라운 장점을 보여주며, 이는 동적 장면에서 실시간 감지 기능을 확장하고 객체 표면 노멀을 신속하게 측정할 수 있는 큰 잠재력을 보여줍니다.
Robustness to event noise.
최적화 및 딥러닝 기반 방법 모두에서 노이즈 견고성과 관련된 설계가 있습니다:
슬라이딩 윈도우에서 이벤트를 수집하고 SVD (식 (10)의 EventPS-OP에 대해)로 가중하거나 신경망 입력으로 합산합니다 (그림 5의 EventPS-FCN 및 그림 6의 EventPS-CNN에 대해).
이러한 방식으로 각 픽셀의 노이즈가 감소합니다.
두 가지 딥러닝 방법의 학습 단계에서.
가변 노이즈 수준에 이벤트 트리거 노이즈를 추가하여 그림 11에서 노이즈 수준에 대한 하이퍼파라미터 분석 실험을 수행하여 우리 방법의 견고성을 입증합니다.
세 가지 EventPS 알고리즘 모두 노이즈 수준이 증가함에 따라 견고합니다.

Limitation.
첫째, 조명의 스캐닝 패턴에는 한계가 있습니다: "circle" 패턴은 높은 각도의 표면을 정상으로 만들기 위해 사각지대를 남기며, "hypotrochoid" 패턴은 기계적으로 구현하기 어렵습니다.
둘째, 조명의 스캐닝 속도가 증가함에 따라 주파수 응답으로 인해 이벤트 신호의 품질이 점차 저하됩니다 [6].
다양한 스캐닝 패턴을 달성하고, 비기계적 조명 장치를 구현하며, 고속 조명 하에서 이벤트 신호 품질을 향상시키는 것은 추가 연구로서 탐구할 가치가 있습니다.
'View Synthesis' 카테고리의 다른 글
| pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction (0) | 2025.05.26 |
|---|---|
| Mip-Splatting: Alias-free 3D Gaussian Splatting (0) | 2024.06.22 |
| 3D Gaussian Splatting for Real-Time Radiance Field Rendering (0) | 2023.10.29 |
| Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions (0) | 2023.09.29 |
| D-NeRF: Neural Radiance Fields for Dynamic Scenes (2) | 2023.09.04 |