2021. 7. 27. 10:16ㆍView Synthesis
NeRF−−: Neural Radiance Fields Without Known Camera Parametrs
ZIRUI WANG, SHANGZHE WU, SHANGZHE WU, MIN CHEN, VICTOR ADRIAN PRISACARIU
이 논문은 알려진 카메라 포즈나 본질적인 요소 없이 2D 이미지에서 새로운 뷰 합성(NVS) 문제를 다룹니다.
다양한 NVS 기술 중 NeRF(Neural Radiance Field)는 놀라운 합성 품질로 인해 최근 인기를 얻고 있습니다.
기존 NeRF 기반 접근 방식은 각 입력 이미지와 관련된 카메라 매개변수가 학습 시 직접 액세스할 수 있거나 동작 구조와 같은 대응을 기반으로 하는 기존 기술로 정확하게 추정할 수 있다고 가정합니다.
이 작업에서 우리는 미리 계산된 카메라 매개변수 없이 RGB 이미지만 주어진 NeRF 모델을 훈련하기 위해 NeRF--라고 하는 종단 간 프레임워크를 제안합니다.
특히, 우리는 내장 및 외장을 모두 포함하는 카메라 매개변수가 NeRF 모델의 훈련 중에 공동 최적화를 통해 자동으로 발견될 수 있음을 보여줍니다.
표준 LLFF 벤치마크에서 우리 모델은 COLMAP 사전 계산된 카메라 매개변수로 훈련된 기준선과 동등한 새로운 뷰 합성 결과를 달성합니다.
또한 다양한 카메라 궤적에서 모델 동작을 이해하기 위해 광범위한 분석을 수행하고 COLMAP이 실패하는 시나리오에서 우리 모델이 여전히 강력한 결과를 생성한다는 것을 보여줍니다.
1. INTRODUCTION
3차원 세계를 날 수 있는 능력은 고대 그리스 신화에 나오는 다이달로스와 이카루스의 3500년 이야기에서, 레오나르도 다빈치가 1400년대 후반에 비행 기계를 만들려는 최초의 과학적 시도에 이르기까지 [Niccoli 2006] 수천 년 동안 인류의 꿈이었습니다.
가상 현실(VR) 기술의 최근 발전 덕분에 이제 디지털 버전의 세상을 캡처하고 임의의 뷰를 생성할 수 있으므로 가상 렌즈를 통해 세상을 횡단할 수 있습니다.
어떤 시점에서든 실제 장면의 사실적인 뷰를 생성하려면 3D 장면 기하학을 이해해야할 뿐만 아니라 정교한 빛 전달 현상으로 인한 복잡한 시점 종속적 모양을 모델링해야 합니다.
이를 달성하는 한 가지 방법은 공간의 각 지점을 통과하는 빛을 직접 모델링하는 소위 5D 플렌옵틱 기능을 구성하는 것입니다[Adelson and Bergen 1991] (또는 관심 대상의 볼록 껍질 외부로 우리 자신을 제한하는 경우 4D 라이트 필드[Gortler et al. 1996; Levoy and Hanrahan 1996]).
불행히도, 조밀하게 샘플링된 플렌옵틱 기능을 물리적으로 측정하는 것은 실제로 실현 가능하지 않습니다.
대안으로 NVS(Novel View Synthesis)는 다양한 관점에서 캡처한 작은 이미지 세트와 같은 드문드문 관찰에서 이러한 조밀한 라이트 필드를 근사하는 것을 목표로 합니다.
문헌에서는 새로운 뷰 합성을 위한 방법을 개발하기 위해 많은 연구 노력을 기울였습니다.
한 그룹은 관찰된 희소 뷰에서 표면 기하학과 표면의 모양을 명시적으로 재구성하는 것을 목표로 합니다[Chaurasia et al. 2013; Debevec et al. 1996; Hedman et al. 2017; Waechter et al. 2014; Wiles et al. 2020; Zitnick et al. 2004].
2D 이미지에서 3D 지오메트리를 재구성하기 위해 SfM(Structure-from-Motion)[Faugeras and Luong 2001]과 같은 기술은 직접 사용할 수 없는 경우 대응 관계를 설정하고 동시에 카메라 매개변수를 추정합니다.
그러나 이러한 방법은 불완전한 표면 재구성과 반사도, 투명도 및 전역 조명과 같은 복잡한 뷰 종속 효과를 모델링할 수 있는 제한된 용량으로 인해 고충실도 이미지를 합성하는 데 종종 어려움을 겪습니다.
다른 접근 방식 그룹은 전체 공간의 모양을 직접 모델링하기 위해 볼륨 기반 표현을 채택합니다[Mildenhall et al. 2019, 2020; Penner와 Zhang 2017; Sitzmann et al. 2019; Zhou et al. 2018], 체적 렌더링 기술을 사용하여 이미지를 생성합니다.
이를 통해 측광 기반 최적화를 위한 부드러운 그라디언트가 가능하고 정교한 뷰 종속 효과로 매우 복잡한 모양과 재료를 모델링할 수 있습니다.
이러한 접근 방식 중에서 NeRF(Neural Radiance Fields)는 복잡한 실제 장면의 고품질 이미지를 합성하기 위한 뛰어난 단순성과 성능으로 인해 최근 인기를 얻었습니다.
NeRF의 핵심 아이디어는 MLP(다층 퍼셉트론)에 의해 매개변수화된 연속 함수로 전체 볼륨 공간을 표현하는 것이며, 일반적으로 해상도 제약이 있는 복셀 그리드로 공간을 이산화할 필요성을 우회합니다.
두 연구 그룹 모두에서 카메라 보정은 종종 전제 조건으로 가정되지만 실제로 이 정보에 액세스할 수 있는 경우는 거의 없으며 SfM과 같은 기존 기술을 사용하여 미리 계산해야 합니다.
특히, NeRF[Mildenhall et al. 2020] 및 그 변종 [Martin-Bruella et al. 2020; Parket al. 2020; Zhang et al. 2020]은 COLMAP[Schonberger and Frahm 2016]을 사용하여 각 입력 이미지와 관련된 카메라 매개변수(내재 및 외재 모두)를 추정합니다.
추가적인 복잡성을 도입하는 것 외에도 이 사전 처리 단계는 동적 장면 또는 상당한 보기 종속적인 모양 변경의 존재로 인해 어려움을 겪습니다, 결과적으로 NeRF 학습은 카메라 매개변수 추정의 견고성과 정확성에 의존하게 됩니다.
이 논문에서 우리는 다음과 같은 질문을 던집니다: NeRF와 같은 뷰 합성 모델을 훈련할 때 카메라 매개변수를 미리 계산해야 합니까?
우리는 대답이 아니오임을 보여줍니다.
NeRF 모델은 실제로 훈련 중에 자체적으로 카메라 매개변수를 자동으로 발견할 수 있습니다.
특히, 우리는 3D 장면 표현과 카메라 매개변수(외부 및 내재 모두)를 공동으로 최적화하는 NeRF--를 제안합니다.
표준 LLFF 벤치마크에서 우리는 COLMAP 사전 계산된 카메라 매개변수로 훈련된 기준 NeRF와 유사한 새로운 뷰 합성 결과를 보여줍니다.
또한 다양한 카메라 궤적에서 모델 동작을 분석하여 COLMAP이 실패한 시나리오에서 우리 모델이 여전히 강력한 결과를 생성한다는 것을 보여줍니다, 이는 조인트 최적화가 고전 SfM 파이프라인의 번들 조정(BA)을 반영하여 보다 강력한 재구성으로 이어질 수 있음을 시사합니다[Triggs et al. 2000].
2. RELATED WORK
새로운 뷰 합성에 대한 방대한 문헌이 있습니다.
이는 대략 두 가지 범주로 나눌 수 있는데, 하나는 명시적 표면 모델링이고 다른 하나는 밀도가 높은 볼륨 기반 표현입니다.
첫 번째 접근 방식 그룹은 표면 기하학을 명시적으로 재구성하고 새로운 뷰 렌더링을 위해 모양을 모델링하는 것을 목표로 합니다.
2D 이미지로부터 3D 기하학을 재구성하기 위해 SfM[Faugeras and Luong 2001; Hartley and Zisserman 2003]과 같은 전통적인 기술 및 SLAM(Simultaneous Localization and Mapping)은 기능 일치를 설정하여 3D 기하학 및 관련 카메라 매개변수(예: MonoSLAM[Davison et al. 2007], ORB-SLAM[Mur-Artal et al. 2015], Bundler[Snavely et al. 2006], COLMAP[Schonberger and Frahm 2016]), 또는 측광 오류, 예 DTAM [Newcombe et al. 2011] 및 LSD-SLAM [Engel et al. 2014]를 공동으로 해결합니다.
그러나 이러한 방법 중 많은 부분이 표면 질감을 확산하고 뷰 종속적인 모양을 복구하지 않으므로 비현실적인 새로운 뷰 렌더링이 발생합니다.
반면에, 다중 뷰 측광 스테레오 방법[Zhou et al. 2013]은 정교한 수제 재료 BRDF 모델을 사용하여 뷰 종속적 모양을 설명하는 것을 목표로 하지만 품질과 복잡성 사이의 트레이드 오프에 어려움을 겪고 있습니다.
[Riegler and Koltun 2020a,b]와 같은 최근 작업은 이미지의 메쉬와 기능을 통합하여 이러한 뷰 종속적 모양 합성을 처리합니다.
궁극적으로, 명시적 지오메트리 재구성이 카메라 매개변수 추정을 용이하게 하지만, 새로운 뷰를 위한 사진처럼 사실적인 모양을 모델링하는 것은 여전히 어려운 작업입니다.
대안으로 3D 공간의 모양을 직접 모델링하기 위해 볼륨 기반 표현이 제안되었습니다[Flynn et al. 2016; Mildenhall et al. 2019, 2020; Penner와 Zhang 2017; Seitz와 Dyer 1999; Sitzmann et al. 2019; Zhou et al. 2018].
최근 몇 년 동안 연구자들은 Soft3D[Penner and Zhang 2017], 다중 평면 이미지(MPI)[Choi et al. 2019; Flynn et al. 2019; Mildenhall et al. 2019; 터커와 스네이블리 2020; Zhou et al. 2018], 장면 표현 네트워크(SRN) [Sitzmann et al. 2019], 점유 네트워크 [Mescheder et al. 2019; Yariv et al. 2020] 및 Neural Radiance Fields(NeRF) [Mildenhall et al. 2020]와 같은 다양한 볼륨 기반 표현을 제안했습니다.
이러한 조밀한 체적 표현은 측광 기반 최적화를 위한 부드러운 그라디언트를 가능하게 하며 매우 복잡한 모양과 모양의 사실적인 새로운 뷰 합성에 유망한 것으로 나타났습니다.
두 연구 그룹의 공통 가정 중 하나는 모든 입력 이미지에 대한 카메라 매개변수에 액세스할 수 있거나 COLMAP[Schonberger and Frahm 2016], Bundler[Snavely et al. 2006] 및 ORB-SLAM [Mur-Artal et al. 2015]과 같은 기존 SfM 또는 SLAM 기술로 정확하게 추정할 수 있다는 것입니다.
이것은 일반적으로 뷰 합성이 정확한 카메라 매개변수 추정에 의존하는 2단계 시스템을 나타냅니다.
이 작업에서 우리는 비교 가능한 뷰 합성 결과를 생성할 수 있는 기능을 유지하면서 RGB 이미지만 제공된 카메라 매개변수와 NeRF 표현을 공동으로 최적화하는 종단 간 프레임워크를 제안합니다.
특히 동시작업인 iNeRF[Yen-Chen et al. 2020]는 우리와 밀접한 관련이 있습니다.
잘 훈련된 NeRF 모델이 주어지면 새로운 뷰에 대한 6DOF 카메라 포즈는 단순히 측광 렌더링 오류를 최소화하여 추정할 수 있음을 보여줍니다.
그러나 처음에는 잘 훈련된 NeRF 모델을 가정하는 반면 우리의 방법은 완전히 감독되지 않은 방식으로 RGB 이미지에서만 카메라 매개변수를 자동으로 검색할 수 있습니다.
여러 이미지를 사용하는 새로운 뷰 합성 외에도 학습 기반 접근 방식도 있습니다[Niklaus et al. 2019; Shih et al. 2020; Tucker and Snavely 2020; Wiles et al. 2020; Wu et al. 2020; Zhou et al. 2016], 학습 데이터 모음에 대해 사전 학습을 통해 추론 시간에 단일 이미지 신규 뷰 합성을 허용합니다.
그러나 이러한 방법은 작은 카메라 움직임에 제한되거나 단일 입력 이미지의 제한된 정보로 인해 낮은 품질의 이미지를 생성합니다.
3. PRELIMINARY
주어진 이미지 세트 I = {𝐼_1, 𝐼_2, . . . , 𝐼_𝑁} 관련 카메라 매개변수 Π = {𝜋_1, 𝜋_2, . . . , 𝜋_𝑁} 내재적 요소와 외재적 요소를 모두 포함하여 새로운 뷰 합성의 목표는 새로운, 보이지 않는 관점에서 사실적인 이미지를 생성할 수 있는 장면 표현을 제시하는 것입니다.
이 논문에서는 NeRF(Neural Radiance Fields)[Mildenhall et al. 2020]에서 제안한 접근 방식을 따릅니다.
NeRF에서 저자는 희소 입력 뷰에서 장면의 체적 표현을 구성하기 위한 연속 함수를 채택합니다.
본질적으로, 연속 함수 𝐹_Θ : (𝒙, 𝒅) → (𝒄, 𝜎)를 사용하여 3D 공간의 뷰 종속 모양을 모델링하며, 다층 퍼셉트론(MLP)에 의해 매개변수화됩니다.
이 함수는 3D 공간의 위치 𝒙 = (𝑥,𝑦, 𝑧)를 보기 방향 𝒅 = (𝜃, 𝜙)과 함께 radiance color 𝒄 = (𝑟, 𝑔, 𝑏) 및 밀도 값 𝜎으로 매핑합니다.
NeRF 모델에서 이미지를 렌더링하기 위해 이미지 평면(^𝐼𝑖 )의 각 픽셀의 색상 𝒑 = (𝑢, 𝑣)은 카메라 위치 𝒐𝑖에서 광선을 따라 radiance를 집계하는 렌더링 함수 R에 의해 얻어집니다, 픽셀 𝒑을 통해 볼륨으로 전달 [Gortler et al. 1996; Max 1995]:
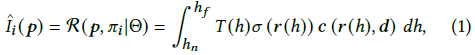
여기서

는 광선을 따라 누적된 투과율을 나타냅니다, 즉, 광선이 ℎ_𝑛에서 ℎ까지 다른 입자에 부딪히지 않고 이동할 확률이고 𝒓(ℎ) = 𝒐 + ℎ𝒅는 카메라에서 시작하는 카메라 광선을 나타냅니다, 원점 𝒐 및 근거리 및 원거리 경계 ℎ_𝑛 및 ℎ_𝑓의 카메라 매개변수 𝜋𝑖에 의해 제어되는 𝒑를 통과한다.
실제로, 식 (1)의 적분은 광선을 따라 샘플링된 점 세트의 방사 및 밀도를 누적하여 근사화됩니다.
이 암시적 장면 표현 𝐹_Θ(𝒙, 𝒅) 및 미분 가능한 렌더러 R을 사용하여 NeRF는 알려진 카메라 매개변수(

,
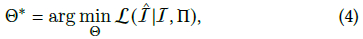
에서 ^I는 합성 이미지 세트 {^𝐼_1, ..., ^𝐼_𝑁}를 나타냄)에서 관찰된 뷰와 합성된 뷰 사이의 측도 오류를 최소화하여 훈련할 수 있습니다.
요약하자면, NeRF는 MLP에 의해 매개변수화된 복사 필드로 3D 장면을 나타내며, 이는 측광 재구성 손실을 통해 드물게 관찰된 이미지 세트로 훈련됩니다.
이러한 이미지에 대한 카메라 매개변수 𝜋𝑖는 훈련에 필요하며 일반적으로 COLMAP[Schonberger and Frahm 2016]과 같은 SfM 패키지로 추정됩니다.
NeRF에 대한 자세한 내용은 독자에게 [Mildenhall et al. 2020]를 참조하십시오.
4. METHOD
본 논문에서는 입력 영상의 카메라 매개변수 𝜋_𝑖를 추정하는 전처리 단계가 실제로 필요하지 않음을 보여줍니다.
원래 NeRF의 학습 설정과 달리 여기에서는 알려진 카메라 매개변수 없이 RGB 이미지 I 세트만 입력으로 가정합니다.
우리는 학습 중에 카메라 매개변수와 장면 표현을 공동으로 최적화하려고 합니다.
수학적으로 이것은 다음과 같이 쓸 수 있습니다:
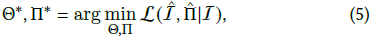
여기서 카메라 매개변수 Π는 카메라 내장과 카메라 내장을 모두 포함합니다.
원래의 2단계 접근 방식을 단순화하는 것 외에도 이러한 공동 최적화 접근 방식에 대한 또 다른 동기는 전 세계적으로 일관된 재구성 결과를 얻기 위한 핵심 단계인 기존 SfM 파이프라인[Triggs et al. 2000] 및 SLAM 시스템[Davison et al.2007; Engel et al. 2014; Newcombe et al. 2011]의 번들 조정에서 비롯됩니다.
다음 섹션에서는 먼저 카메라 매개변수에 대한 표현을 소개한 다음 조인트 최적화 프로세스를 설명합니다.
4.1. Camera Parameters
Camera Intrinsics.
핀홀 카메라 모델을 가정하면 카메라 고유 매개변수는 행렬

로 표현될 수 있습니다: 여기서 𝑓_𝑥 및 𝑓_𝑦는 각각 센서의 너비와 높이에 따른 카메라 초점 거리를 나타내고 𝑐_𝑥 및 𝑐_𝑦은 이미지 평면의 기본 점을 나타냅니다.
카메라의 원리점은 센서 중심, 즉 𝑐_𝑥 ≈ 𝑊/2 및 𝑐_𝑦 ≈ 𝐻/2에 있다고 가정합니다, 여기서 𝐻 및 𝑊는 이미지의 높이와 너비를 나타내며 모든 입력 이미지는 동일한 카메라로 촬영됩니다.
결과적으로 카메라 내장 추정은 초점 거리 𝑓_𝑥 및 𝑓_𝑦의 두 값을 추정하는 것으로 축소되며, 이는 학습 중에 학습 가능한 매개변수로 직접 최적화될 수 있습니다.
Camera Extrinsics.
카메라 외부 매개변수는 SE(3)에서 변환 행렬 𝑻_𝑤𝑐 = [𝑹|𝒕]으로 표현되는 카메라의 위치와 방향을 결정합니다, 여기서 𝑹 ∈ SO(3)은 카메라 회전을 나타내고 𝒕 ∈ R^3은 변환을 나타냅니다.
번역 벡터 𝒕는 유클리드 공간에서 정의되므로 학습 중에 학습 가능한 매개변수로 직접 최적화할 수 있습니다.
SO(3)에 정의된 카메라 회전은 축 각도 표현 𝝓 := 𝛼𝝎, 𝝓 ∈ R^3을 채택합니다, 여기서 회전은 정규화된 회전 축 𝝎 및 회전 각도 𝛼로 표시됩니다.
이것은 Rodrigues의 공식을 사용하여 회전 행렬 𝑹으로 변환할 수 있습니:
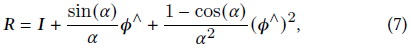
여기서 스큐 연산자(·)∧는 벡터 을 스큐 행렬인

로 변환합니다.
이 매개변수화를 통해 학습 중 학습 가능한 매개변수 𝝓_𝑖 및 𝒕_𝑖를 사용하여 각 입력 이미지 𝐼_𝑖에 대한 카메라 외부 요소를 최적화할 수 있습니다.
요약하자면, 우리 모델에서 직접 최적화하는 카메라 매개변수 세트는 모든 입력 이미지가 공유하는 카메라 내장 함수 𝑓_𝑥 및 𝑓_𝑦, 그리고 각 이미지 𝐼_𝑖에 따라 𝝓_𝑖 및 𝒕_𝑖에 의해 매개변수화된 카메라 외부 속성입니다.
4.2. Joint Optimisation of NeRF and Camera Parameters
우리의 목표는 알려진 카메라 매개변수 없이 RGB 이미지만 입력으로 제공된 NeRF 모델을 훈련하는 것입니다.
즉, NeRF 모델을 훈련하는 동안 각 입력 이미지와 관련된 카메라 매개변수를 찾아야 합니다.
NeRF는 입력 뷰에서 측광 재구성 오류를 최소화하여 학습되었음을 기억하십시오.
특히, 각 훈련 이미지 𝐼_𝑖 에 대해 NeRF 모델 𝐹_Θ에서 재구성하려는 𝑀 픽셀 위치 {𝒑𝑖,𝑚}^𝑀 _𝑚=1을 무작위로 선택합니다.
각 픽셀 𝒑_𝑖,𝑚 = (𝑢, 𝑣)의 색상을 렌더링하기 위해 카메라 위치에서 픽셀을 통해 광선 ^𝒓_𝑖,𝑚(ℎ)을 촬영합니다, 현재 카메라 매개변수 ^𝜋_𝑖 = (^𝑓_𝑥, ^𝑓_𝑦, ^𝝓_𝑖 ,^𝒕_𝑖 ):
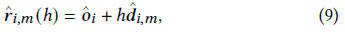
여기서
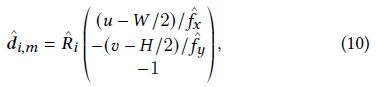
^𝒐_𝑖 = ^𝒕_𝑖 및 ^𝑹_𝑖는 식 (7)을 사용하여 ^𝝓_𝑖로부터 계산됩니다.
그런 다음 광선을 따라 여러 3D 점 {𝒙_𝑗}을 샘플링하고 NeRF 네트워크 𝐹_Θ를 통해 이러한 위치에서 방사 색상 {𝒄_𝑗}과 밀도 값 {𝝈_𝑗}을 평가합니다.
그런 다음 렌더링 함수 식 (1)을 적용하여 광선을 따라 예측된 광도와 밀도를 집계하여 해당 픽셀 ^𝐼_𝑖,𝑚의 색상을 얻습니다.

재구성된 각 픽셀에 대해 예측 색상 ^𝐼_𝑖,𝑚을 입력 이미지에서 샘플링된 실제 색상 𝐼_𝑖,𝑚과 비교하여 식 (3)을 사용하여 측광 손실을 계산합니다.
전체 파이프라인이 완전히 미분 가능하므로 재구성 손실을 최소화하여 NeRF 모델 Θ의 매개변수와 카메라 매개변수 {𝜋_𝑖}를 공동으로 최적화할 수 있습니다.
파이프라인은 알고리즘 1에 요약되어 있습니다.
초기화를 위해 모든 입력 이미지의 카메라는 −𝑧축을 바라보는 원점에 위치합니다, 즉, 모든 ^𝑅_𝑖는 단위 행렬로 초기화되고 모든 𝑡_𝑖는 0벡터로 초기화되며, 초점 거리 𝑓_𝑥 및 𝑓_𝑦은 너비 W 및 높이 𝐻는 각각 FOV≈ 53º로 초기화됩니다.
Refinement.
위의 카메라 매개변수와 NeRF 모델의 공동 최적화가 처음부터 합당한 결과를 생성하지만, 모델은 최적화된 카메라 매개변수가 차선인 로컬 최소값에 빠질 수 있어 합성 이미지가 약간 흐릿해질 수 있습니다.
따라서 합성된 이미지의 품질을 더욱 향상시키기 위해 선택적 개선 단계를 도입합니다.
특히, 첫 번째 학습 프로세스가 완료된 후 학습된 NeRF 모델을 삭제하고 사전 학습된 카메라 매개변수를 유지하면서 임의 매개변수로 다시 초기화합니다.
그런 다음 사전 학습된 카메라 매개변수를 초기화로 사용하여 조인트 최적화를 반복합니다.
우리는 이 추가 개선 단계가 일반적으로 더 선명한 이미지로 이어지고 표 1의 비교에서 입증된 바와 같이 합성 결과를 개선한다는 것을 발견했습니다.
또한 카메라 매개변수는 사용 가능한 외부 도구 상자의 추정 값으로 초기화할 수 있으며 NeRF 모델 학습 중에 공동으로 개선할 수 있습니다.
NeRF 학습 중 COLMAP을 사용하여 추정된 카메라 매개변수를 미세 조정하는 실험을 수행하고 표 1과 같이 조인트 미세 조정을 통해 새로운 뷰 결과가 약간 개선되었음을 찾습니다.
5. EXPERIMENTS
다양한 장면에 대한 실험을 수행하고 COLMAP으로 입력 이미지의 카메라 매개변수를 추정하는 원본 기준 NeRF와 비교합니다.
다음 섹션에서는 실험 설정과 다양한 결과 및 분석에 대해 설명합니다.
또한 섹션 끝에 현재 방법의 한계에 대한 논의도 포함됩니다.
5.1. Setup
5.1.1. Dataset.
우리는 먼저 NeRF에서와 동일한 전방 데이터 세트, 즉 LLFF-NeRF[Mildenhall et al. 2019]에 대한 실험을 수행합니다, LLFF-NeRF는 각각 20-62개의 이미지를 포함하는 휴대폰 또는 소비자 카메라로 캡처한 8개의 전방 장면을 가지고 있습니다.
모든 실험에서 우리는 공식 전처리 절차와 훈련/테스트 분할을 따릅니다, 즉, 훈련 이미지의 해상도는 756×1008이고 모든 8번째 이미지는 테스트 이미지로 사용됩니다.
회전, 횡단(수평 모션) 및 확대와 같은 다양한 카메라 모션 시나리오에서 NVS의 동작을 이해하기 위해 RealEstate10K [Zhou et al. 2018] 및 Tanks&Temples [Knapitsch et al. 2017] 데이터 세트의 짧은 비디오 세그먼트에서 추출한 다양한 장면과 다양한 장면을 추가로 수집했고 뿐만 아니라 우리 자신이 캡처한 클립이 몇 개 더 있습니다.
특히, 해당 데이터 세트에서 원하는 모션 유형의 비디오 시퀀스만 선택합니다.
이 시퀀스의 이미지 해상도는 480x640에서 1080x1920 사이이며 프레임 속도 범위는 24fps에서 60fps입니다.
프레임을 하위 샘플링하고 프레임 속도를 3-6fps로 줄이고 각 시퀀스에는 7-40개의 이미지가 포함됩니다.
5.1.2. Metrics.
우리는 두 가지 측면에서 제안된 프레임워크를 평가합니다:
첫째, 새로운 뷰 렌더링의 품질을 측정하기 위해 일반적인 메트릭인 PSNR(Peak Signal-to-Noise Ratio), SSIM(Structuralsimilarity Index Measure) 및 LPIPS(Learned Perceptual Image Patchsimilarity)를 사용합니다;
둘째, 지각 품질과 별도로 최적화된 카메라 매개변수의 정확도도 평가합니다.
그러나 실제 장면에 대해서는 ground truth에 접근할 수 없으므로 최적화된 카메라와 COLMAP에서 얻은 추정치 간의 차이를 계산해야만 정확도를 평가할 수 있습니다.
초점 거리 평가를 위해 픽셀 메트릭의 절대 오차를 보고합니다.
카메라 포즈의 경우 ATE(Absolute Trajectory Error) 평가 프로토콜을 따릅니다, ATE는 먼저 유사성 변환 Sim(3)을 사용하여 전역적으로 두 세트의 포즈 궤적을 정렬하고 두 회전 사이의 회전 각도와 두 변환 벡터 사이의 절대 거리를 보고합니다.
5.1.3. Implementation Details.
계산 효율성을 위해 다음을 제외하고 원래 기준 NeRF와 동일한 아키텍처를 따라 PyTorch에서 프레임워크를 구현합니다:
(a) 계층적 샘플링 전략을 사용하지 않습니다;
(b) 은닉층 차원을 256에서 128로 줄입니다;
(c) 각 광선을 따라 128개의 점만 샘플링합니다.
NeRF 모델에 대해 Kaiming 초기화 [He et al. 2015]를 사용하고 모든 카메라가 −𝑧 방향을 바라보는 원점에 있도록 초기화하고 초점 거리 𝑓_𝑥 및 𝑓_𝑦을 이미지의 너비와 높이로 사용합니다.
우리는 NeRF, 카메라 포즈 및 초점 거리에 대해 각각 3개의 개별 Adam 옵티마이저를 사용하며, Fortress 장면의 경우 초기 NeRF 학습률을 0.0005로 낮추는 것을 제외하고는 모두 초기 학습률이 0.001입니다.
NeRF 모델의 학습 속도는 0.9954(지수 감쇠)를 곱하여 10 Epoch마다 감쇠되고, 포즈 및 초점 거리 매개변수의 학습 속도는 0.9의 승수로 100 Epoch마다 감쇠됩니다.
각 훈련 에포크에 대해 모든 입력 이미지에서 1024개의 픽셀을 무작위로 샘플링하고 각 광선을 따라 NeRF의 128개 포인트를 샘플링하여 픽셀의 색상을 합성합니다.
달리 지정하지 않는 한 모든 모델은 10000 epoch 동안 학습됩니다.
자세한 기술 정보는 보충 자료에 포함되어 있습니다.
코드를 공개하겠습니다.
5.2. Results
이 섹션에서는 제안된 프레임워크, 즉 NeRF--에 대한 실험 결과와 심층 분석을 제시합니다.
섹션 5.2.1에서 우리는 지각 품질 측면에서 새로운 뷰 합성에 대한 결과를 보여줍니다.
섹션 5.2.2에서 최적화된 카메라 매개변수의 평가를 보여줍니다.
마지막으로 섹션 5.2.3에서 다양한 카메라 모션 패턴에서 모델 동작을 이해하기 위해 제어된 카메라 모션 예를 들어 회전, 횡단 및 확대에서 시퀀스에 대한 몇 가지 정성적 결과와 논의를 보여줍니다.
더 많은 결과와 시각화는 보충 자료에서 제공됩니다.
5.2.1. On Novel View Synthesis Quality.
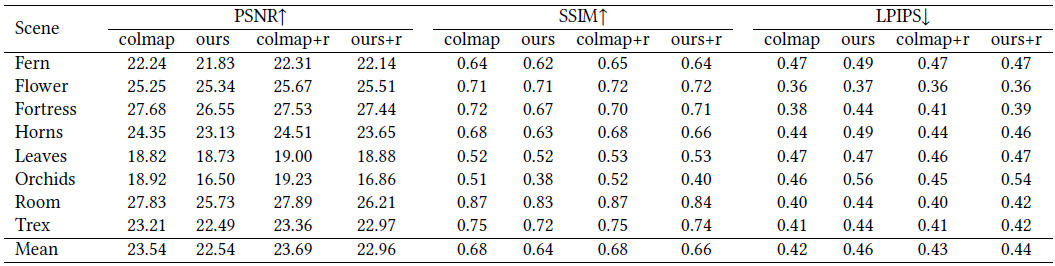
이 섹션에서는 기본 NeRF(여기서 카메라 매개변수는 COLMAP에서 추정됨)에 의해 렌더링된 새로운 뷰의 지각 품질과 RGB 이미지에서만 카메라 매개변수와 3D 장면 표현을 공동으로 최적화하는 제안 모델 NeRF−−를 비교합니다.
최적화된 카메라 매개변수는 COLMAP을 사용하여 추정된 것과 다른 공간에 있을 수 있으므로 평가를 위해 먼저 ATE 도구 상자를 사용하여 Sim(3) 변환을 사용하여 두 개의 궤적을 전역적으로 정렬한 다음 더 세밀한 그래디언트 구동 카메라 NeRF 모델을 고정된 상태로 유지하면서 합성된 이미지의 측광 오류를 최소화하여 포즈 정렬합니다.
마지막으로 테스트 이미지와 가능한 최상의 관점에서 렌더링된 합성 이미지 간의 메트릭을 계산합니다.
간단히 말해서, 위에서 언급한 모든 처리는 카메라 오정렬로 인한 영향을 제거하고 3D 장면 표현의 품질을 공정하게 비교하는 것을 목표로 합니다.

우리는 표 1에 정량적 평가를 보고하고 그림 3에 시각적 결과를 보고합니다.
전반적으로 카메라 매개변수를 입력으로 요구하지 않는 공동 최적화 모델은 기본 NeRF 모델과 유사한 NVS 품질을 달성합니다.
이것은 카메라 매개변수와 3D 장면 표현을 공동으로 최적화하는 것이 실제로 가능하다는 것을 확인합니다.
그럼에도 불구하고 우리는 Orchids와 Room 모두에 대해 NeRF-- 모델이 기준선 NeRF에 비해 약간 더 나쁜 결과를 생성한다는 것을 관찰했습니다.
또한 표 2에서 최적화된 카메라 초점 거리와 COLMAP 추정 간의 차이가 이 두 장면(196.50 및 343.6)에서 가장 두드러진다는 것을 알 수 있습니다.
이는 최적화가 차선의 내장 함수를 사용하여 로컬 최소값으로 떨어졌을 수 있음을 시사합니다.
더 많은 논의는 섹션 5.3에서 찾을 수 있습니다.
표 1에서 우리는 또한 기본 NeRF와 제안된 NeRF-- 모델 모두에 대해 NVS 품질을 약간 개선하는 것으로 나타난 추가 개선 단계의 결과를 보여줍니다.
5.2.2. On Camera Parameter Estimation.
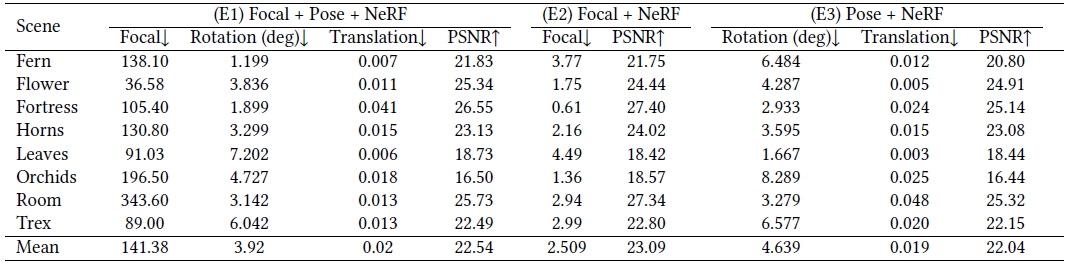
LLFF-NeRF 데이터 세트에서 카메라 매개변수 추정의 정확도를 평가합니다.
섹션 5.1.2에서 설명한 대로 이러한 시퀀스에 대한 실제 카메라 매개변수를 사용할 수 없으므로 COLMAP 추정을 참조로 취급하고 최적화된 카메라 매개변수와 훈련 이미지의 해당 매개변수 간의 차이를 보고합니다.
표 2에서는 추정된 초점 거리의 L1 차이와 글로벌 스케일 모호성을 설명하는 ATE 도구 상자 [Zhang and Scaramuzza 2018]로 계산된 카메라 회전 및 변환에 대한 메트릭을 보여줍니다.
첫 번째 열 세트(Focal + Pose + NeRF)에서 우리 모델에서 얻은 카메라 포즈는 COLMAP에서 추정한 것과 유사하여 공동 최적화 파이프라인의 효율성을 확인합니다.
이는 그림 3의 𝑥𝑦 평면에 정렬된 카메라 궤적으로도 시각화할 수 있습니다.
그러나 카메라 내장 함수의 오류는 훨씬 더 큽니다.
이는 특히 이러한 전방을 향한 장면의 경우 카메라 내장 기능과 카메라 변환 [Pollefeys and Van Gool 1997]의 규모 사이의 악명 높은 모호성 때문입니다.
또 다른 두 가지 실험을 수행합니다:
1) 카메라 포즈를 COLMAP과 동일하게 수정하고 NeRF 모델과 공동으로 카메라 초점 거리만 최적화합니다.
그런 다음 최적화된 초점 거리와 COLMAP 추정 초점 거리 간의 차이를 측정합니다.
표 2의 두 번째 열 세트(Focal + NeRF)에 표시된 대로 카메라 외부를 고정하여 초점 거리가 복구되었습니다.
2) focal length를 COLMAP과 동일하게 고정하고 카메라 외적인 부분만 NeRF 모델과 공동으로 최적화합니다.
결과는 동일한 테이블 Pose+NeRF에 보고되어 관절 최적화와 유사한 성능을 보여줍니다.

Visualisation of the optimisation process.
최적화 프로세스를 더 잘 이해하기 위해 LLFF-NeRF 데이터 세트의 꽃 장면에 대한 다양한 훈련 에포크에서 카메라 포즈의 시각화를 제공합니다(그림 5).
포즈 추정은 처음에 항등 행렬로 초기화되고 약 1000 에포크 후에 수렴되며 최적화된 카메라 매개변수와 COLMAP에서 추정된 매개변수 간의 유사성 변환이 적용됩니다.
5.2.3. On Different Camera Motion Patterns.
5.3. Limitations and Future Work
카메라 매개변수와 3D 장면 표현을 공동으로 최적화하기 위해 제안된 프레임워크가 유망한 결과를 보여주지만 여전히 몇 가지 제한 사항이 있습니다.
첫째, 다른 측도 기반 재구성 방법과 마찬가지로 텍스처가 없는 큰 영역이 있거나 모션 블러, 밝기 또는 색상의 변화와 같이 프레임 전반에 걸쳐 상당한 측광 불일치가 있는 장면을 재구성하는 데 어려움을 겪습니다.
예를 들어, 공동 최적화는 LLFF-NeRF 데이터 세트의 Fortress 장면에 수렴하는 데 어려움을 겪습니다(NeRF 모델의 낮은 학습률에서도 잘 작동함).
이는 반복되는 텍스처의 넓은 영역으로 인해 발생할 수 있으며, 이는 기능 수준 손실을 통합하거나 훈련 중에 뚜렷한 특징 지점에 명시적으로 주의함으로써 잠재적으로 완화될 수 있습니다.
둘째, 카메라 매개변수와 장면 재구성을 공동으로 최적화하는 것은 매우 어려운 일이며 잠재적으로 로컬 최소값에 빠질 수 있습니다.
예를 들어, 섹션 5.2.1에서 논의된 바와 같이, 우리의 공동 최적화 파이프라인은 주로 카메라 내장에 대한 차선의 최적화 결과로 인해 표 1에 표시된 기준선 NeRF와 비교하여 Orchids 및 Room에서 열등한 합성 결과를 생성합니다 (우리의 최적화된 초점 거리와 표 2에 보고된 COLMAP의 초점 거리 사이의 상당한 차이로 알 수 있음).
명시적 기하학적 일치를 위해 추가 구성 요소를 통합하면 최적화 프로세스를 안내하는 데 유용할 수 있습니다.
마지막으로 제안된 프레임워크는 NeRF 모델이 여전히 360° 또는 큰 카메라 변위에서 실제 장면을 모델링하는 데 어려움을 겪기 때문에 대략적으로 앞으로 향하는 장면과 상대적으로 짧은 카메라 궤적으로 제한됩니다 [Zhang et al. 2020].
향후 작업에 관해서는 시간 정보를 시퀀스로 활용하는 것이 더 긴 궤적에 대한 효과적인 정규화가 될 수 있습니다.
6. CONCLUSIONS
이 작업에서 우리는 훈련을 위해 카메라 매개변수에 대한 정보가 필요하지 않은 희소 입력 뷰에서 새로운 뷰 합성을 위해 NeRF--라고 하는 종단 간 NeRF 기반 파이프라인을 제시합니다.
특히, 우리 모델은 NeRF 모델을 동시에 훈련하면서 각 입력 이미지에 대한 카메라 매개변수를 공동으로 최적화합니다.
이렇게 하면 잠재적으로 잘못된 SfM 방법(예: COLMAP)을 사용하여 카메라 매개변수를 미리 계산할 필요가 없으며 여전히 COLMAP 기반 NeRF 기준과 유사한 뷰 합성 결과를 얻을 수 있습니다.
우리는 광범위한 실험 결과를 제시하고 기준 COLMAP이 카메라 매개변수를 추정하지 못하는 경우에도 다양한 카메라 궤적 패턴에서 이 공동 최적화 프레임워크의 효율성을 보여줍니다.
위에서 논의한 현재의 한계에도 불구하고 제안된 공동 최적화 파이프라인은 이 매우 어려운 작업에 대한 유망한 결과를 보여주었으며, 이는 종단 간 접근 방식으로 보다 일반적인 장면에서 새로운 뷰 합성을 향한 한 걸음을 제시합니다.