2022. 3. 25. 17:45ㆍ3D Vision
Pyramid Stereo Matching Network
Jia-Ren Chang, Yong-Sheng Chen
Abstract
최근 연구는 스테레오 이미지 쌍으로부터의 depth 추정이 컨볼루션 뉴럴 네트워크(CNN)로 해결되는 지도 학습 과제로 공식화될 수 있다는 것을 보여주었다.
다만, 현재의 아키텍처는 패치 기반의 Siamse 네트워크에 의존하고 있기 때문에, 부적절한 장소에서의 대응 관계를 검출하기 위한 컨텍스트 정보의 이용 수단이 없습니다.
이 문제를 해결하기 위해, 우리는 공간 피라미드 풀링과 3D CNN이라는 두 개의 주요 모듈로 구성된 피라미드 스테레오 매칭 네트워크인 PSMNet을 제안한다.
공간 피라미드 풀링 모듈은 다양한 규모와 위치의 컨텍스트를 집계하여 비용 볼륨을 형성함으로써 글로벌 컨텍스트 정보의 용량을 활용합니다.
3D CNN은 여러 개의 모래시계 네트워크를 쌓고 중간 지도를 통해 비용량을 정규화하는 방법을 배웁니다.
제안된 접근방식은 여러 벤치마크 데이터셋에서 평가되었습니다.
우리의 방법은 2018년 3월 18일 이전 KITTI 2012와 2015년 순위표에서 1위를 차지했습니다.
1. Introduction
스테레오 영상의 depth 추정은 차량용 자율주행, 3D 모델 재구성, 물체 감지 및 인식을 포함한 컴퓨터 비전 애플리케이션에 필수적이다[4, 31].
한 쌍의 정류된 스테레오 화상이 주어졌을 때, depth 추정의 목적은 기준 화상의 각 화소에 대한 시차 d를 계산하는 것이다.
시차란 왼쪽과 오른쪽 이미지에서 대응하는 픽셀 쌍 사이의 수평 변위를 가리킵니다.
왼쪽 영상의 픽셀(x, y)의 경우, 대응하는 점이 오른쪽 영상의 (x - d, y)에 있는 경우, 이 픽셀의 depth는 fB/d로 계산됩니다, 여기서 f는 카메라의 초점 거리이고 B는 두 카메라 중심 사이의 거리입니다.
스테레오 매칭을 위한 일반적인 파이프라인은 매칭 비용과 후처리를 기반으로 대응하는 포인트를 찾는 것을 포함합니다.
최근에는 MC-CNN [30]에서 해당 지점과 일치시키는 방법을 배우기 위해 컨볼루션 뉴럴 네트워크 (CNN)가 적용되었다.
CNN을 사용한 초기 접근법은 대응 추정의 문제를 유사성 계산으로 처리했다[27, 30], 여기서 CNN은 일치 여부를 추가로 결정하기 위해 한 쌍의 이미지 패치에 대한 유사성 점수를 계산한다.
CNN은 정확도와 속도 면에서 기존 접근 방식에 비해 상당한 이점을 제공하지만, 폐색 영역, 반복 패턴, 텍스처 없는 영역 및 반사 표면과 같이 본질적으로 위치가 좋지 않은 영역에서 정확한 해당 지점을 찾는 것은 여전히 어렵다.
서로 다른 시점 간에 강도-일관성 제약만을 적용하는 것은 일반적으로 이러한 잘못된 위치 영역에서 정확한 대응 추정에 불충분하며 텍스처 없는 영역에서는 쓸모가 없다.
따라서 글로벌 컨텍스트 정보로부터의 지역 지원을 스테레오 매칭에 통합해야 합니다.
현재 CNN 기반 스테레오 매칭 방법의 주요 문제 중 하나는 컨텍스트 정보를 효과적으로 이용하는 방법이다.
일부 연구는 비용 볼륨이나 시차 지도를 크게 개선하기 위해 의미 정보를 통합하려고 시도한다[8, 13, 27].
Displets [8] 방법은 3D 차량을 모델링하여 물체 정보를 활용하여 스테레오 매칭의 모호성을 해결합니다.
ResMatchNet [27]은(는) 위치가 좋지 않은 지역의 성능을 개선하기 위해 시차 맵의 반사 신뢰도를 측정하는 방법을 학습합니다.
GC-Net [ 13 ]는, 코스트 볼륨의 정규화를 위해서 멀티스케일 기능을 병합 하기 위해서, 인코더/디코더 아키텍처를 채용하고 있습니다.
본 연구에서는 스테레오 매칭에서 글로벌 컨텍스트 정보를 활용하기 위한 새로운 피라미드 스테레오 매칭 네트워크(PSMNet)를 제안한다.
수용 필드를 확대하기 위해 공간 피라미드 풀링(SPP)[9, 32] 및 확장 컨볼루션[2, 29]을 사용한다.
이와 같이 PSMNet은 픽셀 레벨의 피쳐를 수용 필드의 스케일이 다른 영역 레벨의 피쳐로 확장합니다, 그 결과, 글로벌과 로컬의 피쳐의 힌트를 조합해, 코스트량을 형성해, 신뢰성 높은 시차를 추정합니다.
또한, 우리는 비용량을 정규화하기 위해 중간 감독과 함께 누적 모래시계 3D CNN을 설계한다.
누적 모래시계 3D CNN은 비용량을 하향/상향 방식으로 반복적으로 처리하여 글로벌 컨텍스트 정보의 활용도를 더욱 향상시킵니다.
우리의 주된 공헌은 다음과 같습니다.
• 후처리 없이 스테레오 매칭을 위한 엔드 투 엔드 학습 프레임워크를 제안한다.
• 글로벌 컨텍스트 정보를 이미지 피쳐에 통합하기 위한 피라미드 풀링 모듈을 소개합니다.
• 우리는 코스트 볼륨에서 컨텍스트 정보의 지역적 지원을 확장하기 위해 누적 모래시계 3D CNN을 제공한다.
• 우리는 KITTI 데이터 세트에 대해 SOTA 정확도를 달성했습니다.
2. Related Work
스테레오 이미지로부터의 depth 추정을 위해, 비용 계산과 비용 볼륨 최적화를 일치시키기 위한 많은 방법이 문헌에서 제안되어 왔다.
[25]에 따르면 일반적인 스테레오 매칭 알고리즘은 4단계로 구성됩니다: 매칭 비용 계산, 비용 집계, 최적화, 시차 개선
최신 연구는 CNN을 사용하여 매칭 비용을 정확하게 계산하는 방법과 불균형 지도를 개선하기 위해 SGM(Semi-Global Matching)[11]을 적용하는 방법에 초점을 맞추고 있다.
Zbontar와 LeCun [30]은 매칭 비용을 계산하기 위해 심층 Siamese 네트워크를 도입한다.
네트워크는 9×9 이미지 패치의 쌍을 사용하여 이미지 패치 간의 유사성을 예측하는 방법을 학습합니다.
또, 비용 집약, SGM, 및 그 외의 시차 맵의 미세화를 포함한 전형적인 스테레오 매칭 순서도 이용하고, 매칭 결과를 개선합니다.
추가 연구를 통해 스테레오 depth 추정이 개선됩니다.
Luo et al. [18] 일치 비용 계산이 다중 라벨 분류로 취급되는 현저하게 빠른 샴 네트워크를 제안한다.
Shaked and Wolf[27]는 비용 계산을 위한 고속도로 네트워크와 불균형 신뢰 점수 예측을 위한 글로벌 불균형 네트워크를 제안하며, 이는 불균형 맵의 추가적인 개선을 촉진한다.
일부 연구는 시차 맵의 후처리에 초점을 맞추고 있다.
Displets [8] 방법은 객체가 일반적으로 규칙적인 구조를 나타내며 임의로 형상화되지 않는다는 사실에 기초하여 제안되었다.
Displets [8] 방법에서는 차량의 3D 모델을 사용하여 반사 영역과 텍스처가 없는 영역의 일치 모호한 부분을 해결합니다.
또한 Gidaris와 Komodakis [6]는 잘못된 라벨을 검출하고 잘못된 라벨을 새로운 라벨로 교체하며 갱신된 라벨(DRR)을 개량함으로써 라벨을 개선하는 네트워크 아키텍처를 제안하고 있습니다.
Gidaris와 Komodakis [6]는 시차 맵 상에서 DRR 네트워크를 사용하여 다른 후처리 없이 뛰어난 성능을 달성합니다.
SGM-Net [26]는 정규화를 위해 수동으로 조정된 패널티 대신 SGM 패널티를 예측하는 방법을 학습합니다.
최근에는 엔드 투 엔드 네트워크가 개발되어 후처리 없이 전체 시차 맵을 예측하고 있습니다.
Mayer et al. [19]는, 시차(DispNet)와 광학 플로우(FlowNet)의 추정을 위해서 엔드 투 엔드 네트워크를 나타내고 있습니다.
또한 네트워크 학습용으로 대규모 합성 데이터 세트인 Scene Flow도 제공합니다.
Fang et al. [21] DispNet [19]를 확장하고 캐스케이드 잔류 학습 (CRL)이라 불리는 2단계 네트워크를 도입합니다.
첫 번째 단계와 두 번째 단계는 각각 시차 맵과 해당 멀티 스케일 잔차를 계산합니다.
그런 다음 두 단계의 출력을 합산하여 최종 시차 맵을 형성합니다.
Kendall et al. [13]은 3D 컨볼루션을 사용한 비용 볼륨 정규화를 위한 엔드 투 엔드 네트워크인 GC-Net을 소개합니다.
상기의 엔드 투 엔드 접근법은 시차 추정을 위해서 멀티 스케일 기능을 이용합니다.
DispNet [19]와 CRL [21]는 모두 계층 정보를 재사용하여 하위 계층의 기능과 상위 계층의 기능을 연결합니다.
또한 CRL [21]은 계층적 감독을 사용하여 여러 해상도의 차이를 계산합니다.
GC-Net [13]는 인코더-디코더 아키텍처를 적용하여 비용 볼륨을 정규화합니다.
이러한 방법의 주요 아이디어는 컨텍스트 정보를 통합하여 애매한 영역의 불일치를 줄이고 depth 추정을 개선하는 것이다.
의미 세그멘테이션 분야에서는 객체 클래스에 라벨을 붙이기 위해 컨텍스트 정보를 통합하는 것도 필수적이다.
글로벌 컨텍스트 정보를 이용하는 방법에는 2가지가 있습니다: 인코더-디코더 아키텍처와 피라미드 풀링
인코더-디코더 아키텍처의 주요 개념은 스킵 커넥션을 통해 하향식 정보와 상향식 정보를 통합하는 것입니다.
완전 컨볼루션 네트워크(FCN) [17]는 세그멘테이션 결과를 개선하기 위해 coarse 예측부터 fine 예측까지 종합하기 위해 처음 제안되었다.
U-Net [24]는 coarse-to-fine 예측을 집계하는 대신 coarse-to-fine 피쳐를 집계하고 생물의학 영상에 대해 양호한 세그멘테이션 결과를 달성합니다.
SharpMask [22], RefineNet [15], 라벨 정제 네트워크 [12]를 포함한 추가 연구는 이 핵심 아이디어를 따르고 멀티스케일 기능의 병합을 위한 보다 복잡한 아키텍처를 제안합니다.
게다가 [5] 및 [20]과 같은 스택형 복수의 인코더-디코더 네트워크가 피쳐 융합을 개선하기 위해 도입되었습니다.
[20]에서 인코더-디코더 아키텍처는 모래시계 아키텍처라고 불립니다.
피라미드 풀링은 심층 네트워크에서 경험적 수용 분야가 이론적 수용 영역보다 훨씬 작다는 사실에 기초하여 제안되었습니다 [16].
ParseNet [16]은 FCN을 사용한 글로벌 풀링이 경험적 수용 필드를 확대하여 전체 이미지 수준에서 정보를 추출하므로 의미 세그맨테이션 결과가 개선된다는 것을 보여줍니다.
DeepLab v2 [2]는 확장 속도가 다른 병렬 확장 컨볼루션을 포함하는 멀티스케일 기능 임베딩을 위한 아터러스 공간 피라미드 풀링(ASPP)을 제안한다.
PSPNet [32]는 효과적인 멀티스케일 컨텍스트를 사전에 수집하기 위한 피라미드 풀링 모듈을 제공합니다.
PSPNet [32]에서 영감을 얻어 DeepLab v3[3]는 글로벌 풀링으로 강화된 새로운 ASPP 모듈을 제안합니다.
공간 피라미드의 유사한 아이디어는 광학적 흐름의 맥락에서 사용되어 왔다.
SPyNet [23]은(는) coarse-to-fine 접근법으로 광학적 흐름을 추정하기 위해 이미지 피라미드를 도입했습니다.
PWC-Net [28]는 피처 피라미드를 사용하여 광학적 흐름 추정을 개선합니다.
스테레오 매칭에 관한 본 연구에서는 의미 세그멘테이션 연구의 경험을 수용하고 전체 이미지 수준에서 글로벌 컨텍스트 정보를 활용한다.
아래에 기술된 바와 같이, 우리는 depth 추정을 위해 피라미드 스테레오 매칭 네트워크를 통한 멀티스케일 콘텍스트 집약을 제안한다.
3. Pyramid Stereo Matching Network
글로벌 컨텍스트의 효과적인 통합을 위한 SPP[9, 32] 모듈과 비용 볼륨 정규화를 위한 누적 모래시계 모듈로 구성된 PSMNet을 소개합니다.
PSMNet의 아키텍처는 그림 1에 나타나 있습니다.
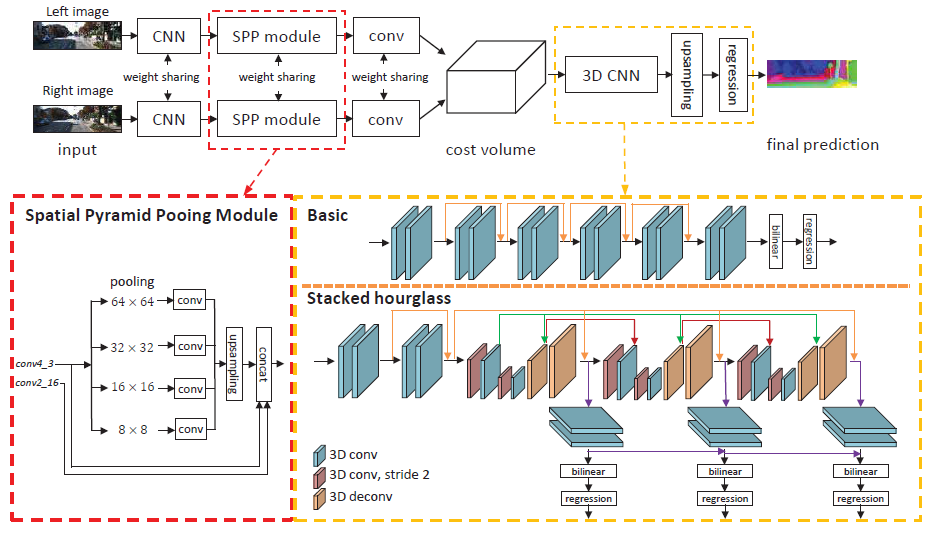
3.1. Network Architecture
제안된 PSMNet의 매개변수는 표 1에 자세히 설명되어 있습니다.
다른 연구에서 첫 번째 컨볼루션 레이어에 큰 필터 (7 × 7)의 적용과는 대조적으로, 세 개의 작은 컨볼루션 필터 (3 × 3)는 동일한 수용 필드를 가진 더 깊은 네트워크를 구축하기 위해 계단식으로 연결된다.
conv1_x, conv2_x, conv3_x 및 conv4_x는 단항 피쳐 추출을 학습하기 위한 기본 잔차 블록 [10]입니다.
conv3_x 및 conv4_x는 확대된 컨볼루션을 적용하여 수용 필드를 더욱 확대한다.
출력 피쳐 맵의 크기는 표 1과 같이 입력 이미지 크기의 1/4 × 1/4입니다.
그런 다음 그림 1에 표시된 것처럼 SPP 모듈을 적용하여 상황 정보를 수집합니다.
왼쪽 및 오른쪽 피쳐 맵을 비용 볼륨에 연결하고, 이를 3D CNN에 공급하여 정규화합니다.
마지막으로 회귀를 적용하여 출력 시차 맵을 계산한다.
SPP 모듈, 비용 볼륨, 3D CNN 및 시차 회귀 분석은 이후 섹션에서 설명합니다.

3.2. Spatial Pyramid Pooling Module
픽셀의 강도만으로 컨텍스트 관계를 판단하기는 어렵습니다.
따라서 객체 컨텍스트 정보가 풍부한 이미지 피쳐는 특히 위치가 잘못된 영역에 대한 대응 추정에 도움이 될 수 있습니다.
이 작업에서 SPP 모듈은 계층적 컨텍스트 정보를 통합하기 위해 물체(예: 자동차)와 하위 영역(윈도우, 타이어, 후드 등) 간의 관계를 학습합니다.
[9]에서 SPP는 CNN의 고정 크기 제약을 제거하도록 설계되었다.
SPP에 의해 생성된 다양한 수준의 피쳐 맵은 평탄화되고 분류를 위해 완전히 연결된 계층에 공급되며, 그 후 SPP는 의미 세분화 문제에 적용됩니다.
ParseNet [16]는 글로벌 평균 풀링을 적용하여 글로벌 컨텍스트 정보를 통합합니다.
PSPNet [32]는 ParseNet [16]를 계층형 글로벌프라이어로 확장하여 스케일 및 서브영역이 다른 정보를 포함합니다.
[32]에서 SPP 모듈은 적응형 평균 풀링을 사용하여 특징을 4개의 척도로 압축한 후, 피쳐 치수를 줄이기 위해 1×1 회전시킨 다음, 저차원 피쳐 맵을 이중 선형 보간법을 통해 원래 피쳐 맵과 동일한 크기로 업샘플링합니다.
다양한 레벨의 피쳐 맵이 최종 SPP 피쳐 맵으로 연결됩니다.
현재 작업에서는 그림 1과 표 1과 같이 SPP에 대해 64×64, 32×32, 16×16, 8×8의 4가지 고정 크기 평균 풀링 블록을 설계합니다.
1×1 컨볼루션 및 업샘플링을 포함한 추가 연산은 [32]와 동일합니다.
Ablation 연구에서는 섹션 4.2에서 설명한 바와 같이 다양한 수준에서 피쳐 맵의 효과를 보여주기 위해 광범위한 실험을 수행했다.
3.3. Cost Volume
MC-CNN[30]과 GC-Net[13]은 거리 메트릭을 사용하는 대신 왼쪽과 오른쪽 피쳐를 연결하여 딥네트워크를 사용하여 일치하는 비용 견적을 학습합니다.
[13]에 이어 SPP 피쳐를 채택하여 각 차이 수준에 걸쳐 왼쪽 피쳐 맵과 해당 오른쪽 피쳐 맵을 연결하여 4D 볼륨(높이×폭×비교×피처 크기)을 형성합니다.
3.4. 3D CNN
SPP 모듈은 다양한 수준의 피쳐를 포함하므로 스테레오 매칭이 용이합니다.
공간 차원뿐만 아니라 시차 차원을 따라 피쳐 정보를 집계하기 위해 비용 볼륨 정규화를 위한 두 가지 종류의 3D CNN 아키텍처를 제안한다: 기본 아키텍처 및 누적 모래시계 아키텍처
그림 1과 같이 기본 아키텍처에서는 네트워크는 단순히 잔여 블록을 사용하여 구축됩니다.
기본 아키텍처는 12개의 3×3×3 컨볼루션 레이어를 포함합니다.
그런 다음 쌍선형 보간법을 통해 비용 볼륨을 H×W×D 크기로 다시 상향 샘플링합니다.
마지막으로, 섹션 3.5에 소개된 크기 H×W의 불균형 맵을 계산하기 위해 회귀를 적용한다.
더 많은 컨텍스트 정보를 학습하기 위해 그림 1과 같이 반복적인 하향식/상향식 처리로 구성된 누적 모래시계(인코더-디코더) 아키텍처를 사용합니다.
누적 모래시계 아키텍처에는 3개의 주요 모래시계 네트워크가 있으며 각각이 시차 맵을 생성합니다.
즉, 누적 모래시계 아키텍처에는 3개의 출력과 손실이 있습니다(Loss_1, Loss_2, Loss_3).
손실 함수는 섹션 3.6에 설명되어 있습니다.
학습 단계에서 총 손실은 3개의 손실의 가중 합계로 계산됩니다.
테스트 단계에서 최종 시차 맵은 3개의 출력 중 마지막 출력입니다.
Ablation 연구에서, 기본 아키텍처는 [13]과 같이 인코딩/디코딩 프로세스를 통해 추가적인 컨텍스트 정보를 학습하지 않기 때문에 SPP 모듈의 성능을 평가하기 위해 기본 아키텍처를 사용했습니다.
3.5. Disparity Regression
연속적인 불균형 맵을 추정하기 위해 [13]에서 제안한 대로 불균형 회귀 분석을 사용한다.
예측 비용 c_d로부터 소프트맥스 연산 σ(·)를 개입시켜 각 시차 d의 확률을 산출한다.
예측된 시차 ^d는 확률에 의해 가중된 각 시차 d의 합계로서

로서 계산된다.
[13]에서 보고되었듯이, 위의 시차 회귀는 분류 기반의 스테레오 매칭 방법보다 더 견고하다.
위의 방정식은 소프트 어텐션 메커니즘이라고 하는 [1]에 도입된 것과 유사합니다.
3.6. Loss
시차 회귀 분석으로 인해 제안된 PSMNet을 학습하기 위해 smooth L1 손실 함수를 채택했습니다.
Smooth L1 손실은 L2 손실에 비해 견고성과 특이치에 대한 민감도가 낮기 때문에 물체 검출을 위한 바운딩 박스 회귀에 널리 사용된다.
PSMNet의 손실 함수는

로 정의됩니다, 여기서
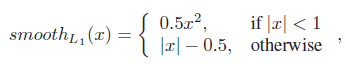
이고, 여기서 N은 라벨이 붙은 픽셀의 수, d는 실측값의 차이, ^d는 예측된 차이입니다.
4. Experiments
5. Conclusions
스테레오 매칭을 위해 CNN을 사용한 최근의 연구는 두드러진 성과를 달성했다.
그럼에도 불구하고, 본질적으로 위치가 좋지 않은 지역에 대한 불균형을 추정하는 것은 여전히 어렵다.
본 연구에서는 컨텍스트 정보를 이용하기 위해 두 개의 주요 모듈로 구성된 스테레오 비전을 위한 새로운 엔드 투 엔드 CNN 아키텍처인 PSMNet을 제안한다: SPP 모듈과 3D CNN
SPP 모듈은 다양한 수준의 피쳐 맵을 통합하여 비용 규모를 형성합니다.
3D CNN은 반복적인 하향/상향 프로세스를 통해 비용량을 정규화하는 방법을 학습합니다.
우리의 실험에서 PSMNet은 다른 최첨단 방법을 능가한다.
PSMNet은 2018년 3월 18일 이전에 KITTI 2012와 2015년 두 순위에서 모두 1위를 차지했습니다.
추정된 시차 맵은 PSMNet이 불량 지역에서의 오류를 크게 감소시킨다는 것을 명확하게 보여줍니다.
'3D Vision' 카테고리의 다른 글
| 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (0) | 2024.05.13 |
|---|---|
| GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images (0) | 2023.02.01 |
| Mesh R-CNN (번역) (0) | 2022.03.23 |
| DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation (0) | 2022.03.18 |
| Occupancy Networks: Learning 3D Reconstruction in Function Space (0) | 2022.03.10 |