2023. 2. 1. 11:28ㆍ3D Vision
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, Sanja Fidler
Abstract
여러 산업이 대규모 3D 가상 세계를 모델링하는 방향으로 나아감에 따라 3D 콘텐츠의 양, 품질 및 다양성 측면에서 확장할 수 있는 콘텐츠 생성 도구의 필요성이 분명해지고 있습니다.
우리 연구에서는 3D 렌더링 엔진이 직접 소비할 수 있는 질감 있는 메시를 합성하여 다운스트림 애플리케이션에서 즉시 사용할 수 있는 성능 3D 생성 모델을 학습하는 것을 목표로 한다.
3D 생성 모델링에 대한 이전 연구는 기하학적 세부 사항이 부족하거나, 생성할 수 있는 메시 토폴로지가 제한적이거나, 일반적으로 텍스처를 지원하지 않거나, 합성 과정에서 신경 렌더러를 활용하여 일반적인 3D 소프트웨어에서 사용하는 것이 중요하다.
본 연구에서는 복잡한 토폴로지, 풍부한 기하학적 세부 정보 및 높은 충실도의 텍스처를 가진 명시적 텍스처 3D 메시를 직접 생성하는 생성 모델인 GET3D를 소개한다.
우리는 2D 이미지 컬렉션에서 모델을 학습시키기 위해 2D 생성 적대적 네트워크뿐만 아니라 미분 가능한 표면 모델링, 미분 가능 렌더링에서 최근의 성공을 연결한다.
GET3D는 자동차, 의자, 동물, 오토바이 및 인간 캐릭터에서 건물에 이르기까지 고품질의 3D 질감 메시를 생성할 수 있어 이전 방법보다 크게 개선되었다.
1 Introduction
다양하고 고품질의 3D 콘텐츠는 게임, 로봇 공학, 건축 및 소셜 플랫폼을 포함한 여러 산업에서 점점 더 중요해지고 있다.
그러나 3D 자산을 수동으로 생성하려면 시간이 많이 걸리고 특정 기술 지식과 예술적 모델링 기술이 필요합니다.
따라서 주요 과제 중 하나는 확장성입니다 – Turbosquid[4] 또는 Sketchfab[3]과 같은 3D 마켓플레이스에서 3D 모델을 찾을 수 있는 반면, 게임이나 영화에 각기 다르게 보이는 캐릭터의 무리를 채우기 위해 많은 3D 모델을 만드는 것은 여전히 아티스트에게 상당한 시간이 걸립니다.
콘텐츠 제작 과정을 용이하게 하고 다양한 (신품) 사용자들이 접근할 수 있도록 하기 위해, 고품질의 다양한 3D 자산을 생산할 수 있는 생성적 3D 네트워크가 최근 활발한 연구 분야가 되고 있다[5, 14, 43, 46, 53, 68, 75, 60, 59, 69, 23].
그러나 현재 실제 애플리케이션에 실질적으로 유용하려면 3D 생성 모델이 이상적으로 다음 요구 사항을 충족해야 합니다:
(a) 상세한 기하학적 구조와 임의의 위상을 가진 형상을 생성할 수 있는 능력이 있어야 한다, (b) 출력은 질감이 있는 메시여야 하며, 이 메시는 Blender [15] 및 Maya [1]와 같은 표준 그래픽 소프트웨어 패키지에서 사용되는 기본 표현이며, 그리고 (c) 명시적인 3D 모양보다 더 광범위하게 사용할 수 있기 때문에 우리는 supervision을 위해 2D 이미지를 활용할 수 있어야 한다.

3D 생성 모델링에 대한 이전 연구는 위의 요구 사항의 하위 집합에 초점을 맞추었지만, 현재까지 이 모든 것을 충족하는 방법은 없습니다(표 1).
예를 들어, 3D 포인트 클라우드[5, 68, 75]를 생성하는 방법은 일반적으로 텍스처를 생성하지 않으며 사후 처리에서 메시로 변환되어야 합니다.
복셀을 생성하는 방법은 종종 기하학적 세부 사항이 부족하고 텍스처를 생성하지 않습니다 [66, 20, 27, 40].
신경 필드[43, 14]에 기반한 생성 모델은 기하학적 구조를 추출하는 데 초점을 맞추지만 텍스처는 무시한다.
이들 중 대부분은 명시적인 3D supervision도 필요하다.
마지막으로, 질감이 있는 3D 메시[54, 53]를 직접 출력하는 방법은 일반적으로 사전 정의된 형상 템플릿을 필요로 하며 복잡한 위상과 변수 속을 가진 형상을 생성할 수 없다.
최근 신경 볼륨 렌더링[45] 및 2D 생성적 적대 네트워크(GAN)[34, 35, 33, 29, 52]의 급속한 발전으로 3D 인식 이미지 합성[7, 57, 8, 49, 51, 25]이 증가하고 있다.
그러나 이 작업 라인은 합성 과정에서 신경 렌더링을 사용하여 다중 뷰 일관된 이미지를 합성하는 것을 목표로 하며 의미 있는 3D 모양이 생성될 수 있다는 것을 보장하지 않는다.
메시는 잠재적으로 마칭 큐브 알고리즘을 사용하여 기본 신경 필드 표현에서 얻을 수 있지만 [39], 해당 텍스처를 추출하는 것은 중요하지 않다.
본 연구에서는 실질적으로 유용한 3D 생성 모델의 모든 요구 사항을 해결하는 것을 목표로 하는 새로운 접근 방식을 소개한다.
구체적으로, 우리는 높은 기하학적 및 텍스처 세부 정보와 임의의 메시 토폴로지를 가진 명시적 텍스처 3D 메시를 직접 출력하는 3D 형상에 대한 생성 모델인 GET3D를 제안한다.
우리 접근 방식의 핵심은 미분 가능한 명시적 표면 추출 방법[60]과 미분 가능한 렌더링 기술[47, 37]을 활용하는 생성 프로세스이다.
전자는 임의의 토폴로지로 질감이 있는 3D 메시를 직접 최적화하고 출력할 수 있게 하는 반면, 후자는 2D 이미지로 모델을 학습시켜 2D 이미지 합성을 위해 개발된 강력하고 성숙한 판별기를 활용할 수 있다.
우리 모델은 메쉬를 직접 생성하고 매우 효율적인(미분 가능한) 그래픽 렌더러를 사용하기 때문에 1024x1024만큼 높은 이미지 해상도로 학습하도록 모델을 쉽게 확장할 수 있어 고품질의 기하학적 및 질감 세부 정보를 학습할 수 있다.
ShapeNet[9], Turbosquid[4] 및 Renderpeople[2]의 복잡한 형상을 가진 여러 범주에서 unconditional 3D 형상 생성을 위한 SOTA 성능을 시연한다.
출력 표현으로 명시적 메시를 사용하는 GET3D는 매우 유연하며 다음을 포함한 다른 작업에도 쉽게 적용할 수 있습니다: (a) supervision 없이 고급 미분 가능 렌더링[12]을 사용하여 분해된 재료 및 뷰 의존적 조명 효과를 생성하는 방법을 학습한다, (b) CLIP [56] 임베딩을 사용하여 텍스트 안내 3D 형상 생성.
2 Related Work
우리는 3D 인식 생성 이미지 합성뿐만 아니라 기하학 및 외관에 대한 3D 생성 모델의 최근 발전을 검토한다.
3D Generative Models
최근, 2D 생성 모델은 고해상도 이미지 합성에서 사진 사실적인 품질을 달성했다[34, 35, 33, 52, 29, 19, 16].
이러한 발전은 또한 3D 콘텐츠 생성 연구에 영감을 주었다.
초기 접근법은 2D CNN 생성기를 3D 복셀 그리드로 직접 확장하는 것을 목표로 했지만 [66, 20, 27, 40, 62], 3D 컨볼루션의 높은 메모리 공간과 계산 복잡성은 고해상도에서의 생성 프로세스를 방해한다.
대안으로, 다른 연구에서는 포인트 클라우드[5, 68, 75, 46], 암시적 [43, 14] 또는 octree [30] 표현을 탐구했다.
그러나 이러한 작업은 주로 기하학을 생성하고 외관을 무시하는 데 중점을 둔다.
또한 출력 표현은 표준 그래픽 엔진과 호환되도록 후처리되어야 한다.
우리 작업과 더 유사한 Textured3DGAN [54, 53] 및 DIBR [11]은 질감이 있는 3D 메시를 생성하지만 템플릿 메시의 변형으로 생성을 공식화하여 다양한 속을 가진 복잡한 토폴로지 또는 모양을 생성하지 못하게 하며, 이는 우리의 방법이 할 수 있다.
PolyGen [48] 및 SurfGen [41]은 임의의 토폴로지로 메쉬를 생성할 수 있지만 텍스처를 합성하지는 않습니다.
3D-Aware Generative Image Synthesis
신경 볼륨 렌더링[45]과 암시적 표현[43, 14]의 성공에 영감을 받아, 최근 연구는 3D 인식 이미지 합성 문제를 다루기 시작했다[7, 57, 49, 26, 25, 76, 8, 51, 58, 67].
그러나 신경 볼륨 렌더링 네트워크는 일반적으로 쿼리 속도가 느려서 학습 시간이 길어지고 [7, 57] 해상도가 제한된 이미지를 생성한다.
GIRAFFE [49] 및 StyleNerf [25]는 낮은 해상도로 신경 렌더링을 수행한 다음 2D CNN으로 결과를 업샘플링하여 학습 및 렌더링 효율성을 향상시킨다.
그러나 성능 향상은 다중 뷰 일관성 감소의 대가로 발생한다.
듀얼 판별기를 활용하여 EG3D[8]는 이 문제를 부분적으로 완화할 수 있다.
그럼에도 불구하고 신경 렌더링을 기반으로 하는 방법에서 질감이 있는 표면을 추출하는 것은 사소한 노력이 아니다.
대조적으로 GET3D는 표준 그래픽 엔진에서 쉽게 사용할 수 있는 질감이 있는 3D 메시를 직접 출력한다.
3 Method
이제 질감이 있는 3D 모양을 합성하기 위한 GET3D 프레임워크를 제시한다.
생성 프로세스는 두 부분으로 나뉩니다: 임의 위상의 표면 메시를 미분으로 출력하는 지오메트리 분기와 표면 포인트에서 쿼리하여 색상을 생성할 수 있는 텍스처 필드를 생성하는 텍스처 분기.
후자는 예를 들어 재료와 같은 다른 표면 특성으로 확장될 수 있다(섹션 4.3.1).
학습 중에 효율적인 미분 가능한 래스터라이저를 사용하여 결과적으로 질감이 있는 메시를 2D 고해상도 이미지로 렌더링한다.
전체 프로세스는 미분될 수 있으므로 2D 판별기에서 두 생성기 분기로 그레디언트를 전파하여 이미지(관심 대상을 나타내는 마스크 포함)에서 적대적 학습을 할 수 있다.
우리의 모델은 그림 2에 예시되어 있다.
다음에서는 섹션 3.2의 미분 가능한 렌더링 및 loss 함수로 진행하기 전에 섹션 3.1에서 3D 생성기를 먼저 소개합니다.

3.1 Generative Model of 3D Textured Meshes
우리는 가우시안 분포 z ∈ N(0, I)의 샘플을 텍스처 E가 있는 메시 M에 매핑하기 위해 3D 생성기 M, E = G(z)를 학습하는 것을 목표로 한다.
동일한 지오메트리가 다른 텍스처를 가질 수 있고, 동일한 텍스처가 다른 지오메트리에 적용될 수 있기 때문에, 우리는 두 개의 랜덤 입력 벡터 z_1 ∈ R^512와 z_2 ∈ R^512를 샘플링한다.
StyleGAN [34, 35, 33]에 이어 비선형 매핑 네트워크 f_tex와 f_tex를 사용하여 z_1과 z_2를 중간 잠재 벡터 w_1 = f_tex(z_1)와 w_2 = f_tex(z_2)에 각각 매핑하며, 이는 3D 모양과 질감의 생성을 제어하는 스타일을 생성하는 데 추가로 사용된다.
우리는 공식적으로 섹션 3.1.1의 기하학적 생성기와 섹션 3.1.2의 텍스처 생성기를 소개한다.
3.1.1 Geometry Generator
우리는 최근 제안된 미분 가능한 표면 표현인 DMTet[60]을 통합하도록 기하학 생성기를 설계한다.
DMTet는 변형 가능한 사면체 그리드에 정의된 부호 거리 필드(SDF)로서 기하학을 표현한다[22, 24], 여기서 표면은 행진하는 사면체를 통해 미분으로 복구할 수 있다[17].
정점을 이동하여 그리드를 변형하면 해상도를 더 잘 활용할 수 있습니다.
표면 추출을 위해 DMTet를 채택함으로써 임의의 토폴로지 및 속과 함께 명시적인 메시를 생성할 수 있다.
다음으로 DMTet에 대한 간략한 요약을 제공하고 자세한 내용을 위해 독자에게 원본 논문을 참조하도록 한다.
(V_T, T)가 물체가 놓여 있는 전체 3차원 공간을 나타내도록 하자, 여기서 V_T는 사면체 격자 T의 꼭짓점이다.
각 정사면체 T_k ∈ T는 k ∈ {1, ..., K}, 그리고 v_i_k ∈ R^3의 4개의 꼭짓점 {v_a_k, v_b_k, v_c_k_k, v_d_k}을 사용하여 정의된다.
각 정점 v_i는 3D 좌표 외에도 SDF 값 s_i ∈ R과 초기 표준 좌표에서 정점의 변형 Δv_i ∈ R^3을 포함한다.
이 표현은 미분 가능한 행군 사면체[60]를 통해 명시적 메시를 복구할 수 있게 해주는데, 여기서 연속 공간의 SDF 값은 변형된 정점 v_i' = v_i + Δv_i의 값 s_i의 중심 보간에 의해 계산된다.
Network Architecture
우리는 일련의 조건부 3D 컨볼루션 및 fully connected 레이어를 통해 각 정점 v_i에서 w_1 ∈ R^512를 SDF 값과 변형에 매핑한다.
구체적으로, 우리는 먼저 3D 컨볼루션 레이어를 사용하여 w_1에서 조건화된 피처 볼륨을 생성한다.
그런 다음 우리는 삼선 보간법을 사용하여 각 정점 v_i ∈ V_T에서 피쳐를 쿼리하고 SDF 값 s_i와 변형 Δv_i를 출력하는 MLP에 공급한다.
고해상도 모델링이 필요한 경우(예: 휠에 얇은 구조가 있는 모터바이크) [60]에 이어 볼륨 세분화를 추가로 사용합니다.
Differentiable Mesh Extraction
모든 정점에 대해 s_i와 Δv_i를 얻은 후, 우리는 명시적인 메시를 추출하기 위해 미분 가능한 행진 사면체 알고리즘을 사용한다.
행군 사면체는 s_i의 부호에 기초하여 각 사면체 내의 표면 위상을 결정한다.
특히, sign(s_i) ≠ sign(s_j)에서 메시 면이 추출되는데, 여기서 i, j는 사면체 가장자리에 있는 꼭짓점의 지수를 나타내며, 그 면의 꼭짓점 m_i,j는 m_i,j = (v_i's_j - v_j's_i) / (s_j - s_i)로 선형 보간에 의해 결정된다.
위 식은 s_i ≠ s_j일 때만 평가되므로 미분 가능하며, m_i,j로부터의 기울기는 SDF 값 s_i 및 변형 Δv_i로 역연산될 수 있다.
이 표현을 사용하면 s_i의 다른 부호를 예측하여 임의의 위상을 가진 형상을 쉽게 생성할 수 있다.
3.1.2 Texture Generator
생성된 형상이 임의의 속과 위상을 가질 수 있기 때문에 출력 메시와 일치하는 텍스처 맵을 직접 생성하는 것은 사소한 일이 아니다.
따라서 텍스처를 텍스처 필드로 매개 변수화한다[50].
구체적으로, 우리는 w_2에서 조건화된 표면점 p ∈ R^3의 3D 위치를 해당 위치의 RGB 색상 c ∈ R^3에 매핑하는 함수 f_t로 텍스처 필드를 모델링한다.
텍스처 필드는 기하학에 의존하기 때문에, 우리는 c = f_t(p, w_1 + w_2), 여기서 +가 연결을 나타내도록 기하학 잠재 코드 w_1에 이 매핑을 추가로 조건화한다.
Network Architecture
우리는 3D 객체를 재구성하고 3D 인식 이미지를 생성하는 데 효율적이고 표현적인 3면 표현을 사용하여 텍스처 필드를 나타낸다[8].
구체적으로, 우리는 [8, 35]를 따르고 conditional 2D 컨볼루션 신경망을 사용하여 잠재 코드 w_1 + w_2를 N x N x (C x 3) 크기의 세 개의 축-정렬된 직교 피처 평면에 매핑한다, 여기서 N = 256은 공간 해상도를 나타내고 C = 32는 채널 수를 나타낸다.
피쳐 평면이 주어지면, 표면 점 p의 피쳐 벡터 f^t ∈ R^32는 f^t = ∑_e ρ(π_e(p))로 복구될 수 있다, 여기서 π_e(p)는 점 p의 피쳐 평면 e에 대한 투영이고 ρ(·)는 피쳐의 이중 선형 보간을 나타낸다.
그런 다음 추가 fully connected 레이어를 사용하여 집계된 피쳐 벡터 f^t를 RGB 색상 c에 매핑한다.
신경 필드 표현도 사용하는 3D 인식 이미지 합성[8, 25, 7, 57]에 대한 다른 연구와 달리, 우리는 표면 지점의 위치에서만 텍스처 필드를 샘플링하면 된다.
이는 고해상도 이미지를 렌더링하기 위한 계산 복잡성을 크게 줄이고 구성에 의해 다중 뷰 일관성 있는 이미지를 생성할 수 있도록 보장한다.
3.2 Differentiable Rendering and Training
학습 중 모델을 supervise하기 위해, 우리는 미분 가능한 렌더러를 활용하여 다중 뷰 3D 객체 재구성을 수행하는 Nvdiffrec[47]에서 영감을 얻는다.
구체적으로, 우리는 추출된 3D 메시와 텍스처 필드를 미분 가능한 렌더러[37]를 사용하여 2D 이미지로 렌더링하고, 이미지를 실제 개체와 구별하거나 생성된 개체에서 렌더링하려는 2D 판별기로 네트워크를 supervise한다.
Differentiable Rendering
우리는 데이터 세트의 이미지를 획득하는 데 사용된 카메라 분포 C가 알려져 있다고 가정한다.
생성된 모양을 렌더링하기 위해 C에서 카메라 c를 랜덤으로 샘플링하고, 고도로 최적화된 미분 가능 래스터라이저 Nvdiffrast[37]를 사용하여 3D 메시를 2D 실루엣뿐만 아니라 각 픽셀이 메시 표면의 해당 3D 포인트의 좌표를 포함하는 이미지로 렌더링한다.
이러한 좌표들은 또한 RGB 값을 얻기 위해 텍스처 필드를 쿼리하는 데 사용된다.
추출된 메시에서 직접 작동하기 때문에 고해상도 이미지를 고효율로 렌더링할 수 있어 1024x1024만큼 높은 이미지 해상도로 모델을 학습할 수 있다.
Discriminator & Objective
우리는 적대적 목표를 사용하여 모델을 학습한다.
우리는 StyleGAN[34]의 판별기 아키텍처를 채택하고, R1 정규화와 동일한 비채택 GAN objective를 사용한다[42].
우리는 경험적으로 RGB 이미지와 실루엣에 대한 두 개의 별도 판별기를 사용하면 두 가지 모두에서 작동하는 단일 판별기보다 더 나은 결과를 얻을 수 있다는 것을 발견했다.
D_x가 판별기를 나타내도록 하자, 여기서 x는 RGB 이미지 또는 실루엣일 수 있다.
적대적 objective는 다음과 같이 정의된다:

, 여기서 g(u)는 g(u) = -log(1+exp(-u)), p_x는 실제 이미지의 분포, R은 렌더링, λ는 하이퍼 파라미터로 정의된다.
R은 미분 가능하기 때문에 2D 이미지에서 3D 생성기로 그레디언트를 역전파할 수 있다.
Regularization
뷰에서 볼 수 없는 내부 부동면을 제거하기 위해, 우리는 인접한 정점의 SDF 값 사이에 정의된 교차 엔트로피 loss로 지오메트리 생성기를 추가로 정규화한다[47]:

, 여기서 H는 이진 교차 엔트로피 loss를, σ는 시그모이드 함수를 나타낸다.
식. 2의 합은 sign(s_i) ≠ sign(s_j)인 사면체 격자의 고유한 가장자리 S_e 집합에 대해 정의된다.
그런 다음 전체 loss 함수는

으로 정의됩니다, 여기서 μ는 정규화 레벨을 제어하는 초 매개 변수입니다.
4 Experiments
우리는 모델을 평가하기 위해 광범위한 실험을 수행한다.
먼저 GET3D에 의해 생성된 3D 텍스처 메시의 품질을 ShapeNet [9] 및 Turbosquid [4] 데이터 세트를 사용하여 기존 방법과 비교한다.
다음으로, 우리는 섹션 4.2에서 우리의 설계 선택을 축소한다.
마지막으로, 우리는 섹션 4.3에서 다운스트림 애플리케이션에 GET3D를 적용함으로써 GET3D의 유연성을 입증한다.
추가 실험 결과와 구현 세부 사항은 부록에 제공된다.
4.1 Experiments on Synthetic Datasets
Datasets
ShapeNet[9]에 대한 평가를 위해 복잡한 형상을 가진 세 가지 범주(각각 7497, 6778 및 337 형상을 포함하는 자동차, 의자 및 모터바이크)를 사용합니다.
우리는 각 범주를 랜덤으로 학습(70%), 검증(10%), 테스트(20%)로 나누고, 학습 세트에 중복된 테스트 세트 모양에서 추가로 제거한다.
학습 데이터를 렌더링하기 위해, 우리는 각 형상의 위쪽 반구에서 카메라 포즈를 랜덤으로 샘플링한다.
자동차 및 의자 범주의 경우 24개의 랜덤 뷰를 사용하는 반면, 모터바이크의 경우 모양 수가 적기 때문에 100개의 뷰를 사용합니다.
ShapeNet의 모델은 단순한 질감만 가지고 있기 때문에 TurboSquid[4]에서 수집한 동물 데이터 세트(442개의 모양)에서도 GET3D를 평가하며, 여기서 텍스처가 더 상세하고 위에서 정의한 대로 학습, 검증 및 테스트로 나눈다.
마지막으로, GET3D의 다용성을 입증하기 위해, 우리는 또한 Turbosquid(563개의 모양)에서 수집된 House 데이터 세트와 Renderpeople[2](500개의 모양)에서 수집된 인체 데이터 세트에 대한 정성적 결과를 제공한다.
우리는 각 범주에 대해 별도의 모델을 학습한다.
Baselines
우리는 GET3D를 두 그룹의 작업과 비교한다:
1) 3D supervision에 의존하는 3D 생성 모델: PointFlow [68] 및 OccNet [43].
이러한 메서드는 텍스처 없이 지오메트리만 생성합니다.
2) 3D 인식 이미지 생성 방법: GRAF [57], PiGAN [7] 및 EG3D [8].
Metrics
합성 품질을 평가하기 위해 생성된 형상의 기하학적 구조와 질감을 모두 고려한다.
기하학의 경우 [5]의 메트릭을 채택하고 Chamfer Distance (CD)와 Light Field Distance [10](LFD)를 모두 사용하여 커버리지 점수와 최소 일치 거리를 계산한다.
OccNet [43], GRAF [57], PiGAN [7] 및 EG3D [8]의 경우, 우리는 기본 지오메트리를 추출하기 위해 행진 큐브를 사용한다.
PointFlow [68]의 경우 LFD를 평가할 때 포아송 표면 재구성을 사용하여 포인트 클라우드를 메시로 변환합니다.
텍스처 품질을 평가하기 위해 이미지 합성을 평가하는 데 일반적으로 사용되는 FID [28] 메트릭을 채택한다.
특히 각 범주에 대해 테스트 모양을 2D 이미지로 렌더링하고, 각 모델에서 생성된 3D 모양을 동일한 카메라 분포를 사용하여 50k 이미지로 렌더링한다.
그런 다음 두 이미지 세트에서 FID를 계산한다.
3D 인식 이미지 합성[57, 7, 8]의 베이스라인은 질감이 있는 메시를 직접 출력하지 않으므로, 우리는 두 가지 방법으로 FID 점수를 계산한다: (i) 우리는 그들의 신경 볼륨 렌더링을 사용하여 2D 이미지를 얻는데, 우리는 이것을 FID-Ori라고 합니다, 그리고 (ii) 우리는 행진 큐브를 사용하여 신경 필드 표현에서 메시를 추출하고 렌더링한 다음 각 픽셀의 3D 위치를 사용하여 네트워크를 쿼리하여 RGB 값을 얻는다.
우리는 이 점수를 FID-3D라고 하는데, 이 점수는 실제 3D 모양을 더 잘 알고 있다.
평가 지표에 대한 자세한 내용은 부록 B.3을 참조하십시오.
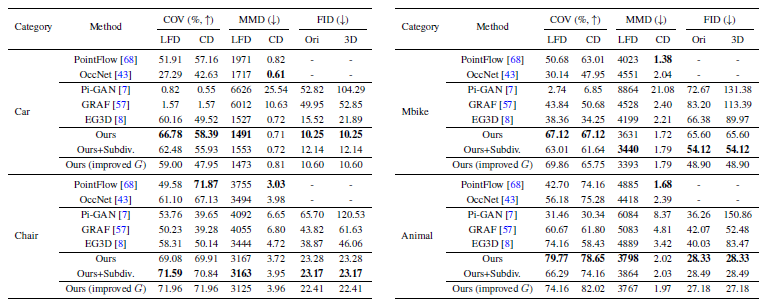


Experimental Results
정량적인 결과는 표 2에, 정성적인 예는 그림 3 및 그림 4에 제시한다.
추가 결과는 보충 비디오에서 확인할 수 있습니다.
학습 중에 3D supervision을 사용하는 OccNet[43]과 비교하여, GET3D는 다양성(COV)과 품질(MMD) 측면에서 더 나은 성능을 달성하며, 생성된 모양은 더 많은 기하학적 세부 정보를 가지고 있다.
PointFlow[68]는 CD의 MMD 측면에서 GET3D를 능가하는 반면, LFG의 MMD에서는 GET3D가 더 우수합니다.
우리는 이것이 PointFlow가 CD를 선호하는 포인트 위치에서 직접 최적화하기 때문이라고 가정한다.
GET3D는 또한 3D 인식 이미지 합성 방법과 비교할 때 모든 데이터 세트의 모든 메트릭 측면에서 PiGAN [7] 및 GRAF [57]보다 크게 개선된다.
우리가 생성한 모양은 또한 더 자세한 기하학적 구조와 질감을 포함한다.
최근 작업 EG3D[8]와 비교합니다.
우리는 2D 이미지 생성(FID-ori)에서 비슷한 성능을 달성하는 동시에 실제 3D 기하학 및 텍스처 학습에 대한 모델의 효과를 보여주는 FID-3D 측면에서 3D 형상 합성을 크게 향상시킨다.


질감이 있는 메시를 합성하기 때문에, 우리는 우리의 모양을 Blender로 내보낼 수 있다.
우리는 그림 1과 5에 렌더링 결과를 보여준다.
GET3D는 다양하고 고품질의 지오메트리와 토폴로지, 매우 얇은 구조물(모터바이크), 자동차, 동물 및 주택의 복잡한 질감을 가진 모양을 생성할 수 있다.

Shape Interpolation
또한 GET3D는 형상 보간을 가능하게 하여 편집 목적에 유용할 수 있다.
우리는 그림 6에서 GET3D의 잠재 공간을 탐색하는데, 여기서 우리는 잠재 코드를 보간하여 왼쪽에서 오른쪽으로 각각의 모양을 생성한다.
GET3D는 한 형태에서 다른 형태로 원활하고 의미 있는 전환을 충실히 생성할 수 있다.
우리는 잠재 코드를 임의의 방향으로 약간 교란시킴으로써 로컬 잠재 공간을 추가로 탐색한다.
GET3D는 잠재 공간에서 로컬 편집을 적용할 때 새롭고 다양한 모양을 생성한다(그림 7).

4.2 Ablations
우리는 두 가지 방법으로 모델을 축소한다: 1) 볼륨 세분화 있고, 없고, 2) 다른 이미지 해상도를 사용한 학습.
추가적인 ablations은 부록 C.3에 제공된다.
Ablation of Volume Subdivision
표 2에서 보는 바와 같이, 볼륨 세분화는 얇은 구조를 가진 클래스(예: 모터바이크)의 성능을 크게 향상시키는 반면, 다른 클래스에서는 이득을 얻지 못한다.
우리는 초기 사면체 해상도가 이미 의자와 자동차에 대한 자세한 기하학적 구조를 포착하기에 충분하며, 따라서 세분화는 더 이상의 개선을 제공할 수 없다고 가정한다.

Ablating Different Image Resolutions
우리는 표 3에서 학습 이미지 해상도의 효과를 축소한다.
예상대로, 이미지 해상도가 증가하면 네트워크가 저해상도 이미지에서 사용할 수 없는 더 많은 세부 정보를 볼 수 있기 때문에 FID 및 형상 품질 측면에서 성능이 향상된다.
이는 종종 암시적 기반 방법에 사용하기 어려운 높은 이미지 해상도를 가진 학습의 중요성을 입증한다.
4.3 Applications
4.3.1 Material Generation for View-dependent Lighting Effects
GET3D는 쉽게 확장되어 현대 그래픽 엔진에서 직접 사용할 수 있는 표면 재료를 생성할 수 있다.
특히 널리 사용되는 Disney BRDF[6, 32]를 따르고 기본 색상(R^3), 금속(R) 및 거칠기(R) 특성 측면에서 재료를 설명한다.
결과적으로, 우리는 텍스처 생성기를 사용하여 (RGB 대신) 5채널 반사 필드를 출력한다.
재료의 미분 가능한 렌더링을 수용하기 위해 효율적인 spherical Gaussian (SG) 기반 지연 렌더링 파이프라인을 채택한다[12].
구체적으로, 우리는 반사 필드를 G-buffer로 래스터화하고, 각 파노라마에 32개의 SG 로브를 장착하여 L_SG ∈ R^(32x7)을 얻는 실제 실외 HDR 파노라마 세트 S_light = {L_SG}_K에서 HDR 이미지를 랜덤으로 샘플링한다.
그런 다음 SG 렌더러[12]는 카메라 c를 사용하여 뷰 의존 조명 효과가 있는 RGB 이미지를 렌더링하는데, 이는 학습 중에 판별기에 공급된다.
GET3D는 학습 중에 재료 supervision을 필요로 하지 않으며 unsupervised 방식으로 분해된 재료를 생성하는 방법을 학습한다.

우리는 그림 8에서 생성된 표면 물질의 정성적 결과를 제공한다.
GET3D는 unsupervised에도 불구하고 흥미로운 물질 분해를 발견한다, 예를 들어, 창문은 차체보다 더 광택이 나도록 더 작은 거칠기 값으로 정확하게 예측되고, 차체는 더 많은 유전체로 발견된다.
생성된 물질은 다양한 조명 조건에서 복잡한 스펙터클 효과를 설명할 수 있는 현실적인 재조명 결과를 생성할 수 있다.

4.3.2 Text-Guided 3D Synthesis
이미지 GAN과 유사하게, GET3D는 CLIP[56]의 guidance에 따라 사전 학습된 모델을 미세 조정하여 텍스트-guided 3D 콘텐츠 합성을 지원한다.
우리의 최종 합성 결과는 질감이 있는 3D 메시이다.
이를 위해, 우리는 styleGAN-NADA[21]의 이중 생성기 설계를 따르며, 여기서 사전 학습된 생성기의 학습 가능 복사본 G_t와 동결된 복사본 G_f가 채택된다.
최적화 중에 G_t와 G_f는 모두 16개의 랜덤 카메라 뷰에서 이미지를 렌더링합니다.
텍스트 쿼리가 주어지면, 우리는 500쌍의 노이즈 벡터 z_1과 z_2를 샘플링한다.
각 샘플에 대해 G_t의 매개 변수를 최적화하여 방향 CLIP loss[21](해당 범주에 대한 소스 텍스트 레이블은 "자동차", "동물" 및 "집")을 최소화하고 loss가 최소인 샘플을 선택한다.
이 프로세스를 가속화하기 위해 먼저 500개 샘플에 대해 소수의 최적화 단계를 실행한 다음 loss가 가장 적은 상위 50개 샘플을 선택하고 300개 단계에 대해 최적화를 실행합니다.
SOTA 텍스트 기반 메시 스타일리시 방법인 Text2Mesh[44]에 대한 결과와 비교는 그림 9에 제공된다.
[44]에는 이 방법에 대한 입력으로 형상의 메시가 필요하다.
우리는 동결된 발전기에서 생성된 메시를 입력 메시로 제공한다.
정점 변위로 표면 세부 사항을 합성하려면 메시 정점이 조밀해야 하므로, 각 메시가 평균적으로 50k-150k 정점을 갖도록 중간 지점 세분화로 입력 메시를 추가로 세분화한다.
5 Conclusion
우리는 임의의 토폴로지로 고품질의 3D 텍스처 메시를 합성할 수 있는 새로운 3D 생성 모델인 GET3D를 소개했다.
GET3D는 2D 이미지만을 supervision으로 사용하여 학습된다.
우리는 여러 범주에서 이전의 SOTA 방법에 비해 3D 모양을 생성하는 데 있어 상당한 개선을 실험적으로 보여주었다.
우리는 이 작업이 AI를 이용한 3D 콘텐츠 제작의 민주화에 한 걸음 더 다가가기를 바란다.
Limitations
GET3D는 실질적으로 유용한 3D 텍스처 형태의 3D 생성 모델을 향한 중요한 발걸음을 내딛지만 여전히 몇 가지 한계가 있다.
특히, 우리는 여전히 학습 중 카메라 배포에 대한 지식뿐만 아니라 2D 실루엣에 의존한다.
결과적으로, GET3D는 현재 합성 데이터에서만 평가되었다.
유망한 확장은 인스턴스 segmentation 및 카메라 포즈 추정의 발전을 사용하여 이 문제를 완화하고 GET3D를 실제 데이터로 확장할 수 있다.
또한 GET3D는 범주별로 학습된다.
향후 여러 범주로 확장하면 범주 간 다양성을 더 잘 표현하는 데 도움이 될 수 있다.
Broader Impact
우리는 현재 그래픽 엔진으로 쉽게 가져올 수 있는 3D 텍스처 메시를 생성하는 새로운 3D 생성 모델을 제안했다.
우리 모델은 임의의 토폴로지, 고품질 텍스처 및 풍부한 기하학적 세부 정보로 모양을 생성할 수 있어 3D 콘텐츠 생성을 위한 AI 도구를 민주화할 수 있는 길을 열었다.
모든 머신러닝 모델과 마찬가지로 GET3D도 학습 데이터에 도입된 편향이 발생하기 쉽다.
따라서 GET3D는 이러한 애플리케이션에 맞게 조정되지 않기 때문에 3D 인체 생성과 같은 민감한 애플리케이션을 다룰 때 많은 주의를 기울여야 한다.
개인 정보 보호 또는 잘못된 인식이 잠재적인 오용 또는 기타 유해한 응용 프로그램으로 이어질 수 있는 경우 GET3D를 사용하지 않는 것이 좋습니다.
대신, 우리는 가능한 피부 톤, 인종 또는 성별 정체성의 공정하고 광범위한 분포를 묘사하기 위해 모델을 학습하기 전에 실무자가 데이터 세트를 주의 깊게 검사하고 편향을 제거하도록 권장한다.
A Detail of Our Model
섹션 3에서 우리는 GET3D에 대한 높은 수준의 설명을 제공했다.
여기서는 공간 부족으로 누락된 구현 세부 사항을 제공한다.
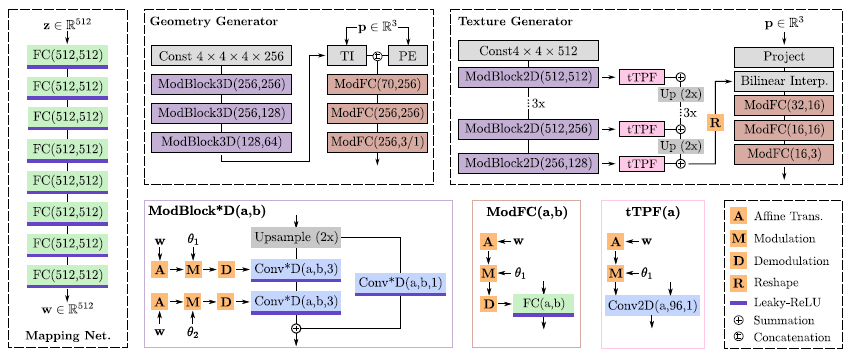
자세한 내용은 본 논문의 그림 B와 그림 2를 참조하십시오.
A.1 Mapping Network
StyleGAN[34, 35]에 이어, 우리의 매핑 네트워크 f_geo와 f_tex는 각각 fully-connected layer가 512개의 숨겨진 차원과 leaky-ReLU activation을 갖는 8계층 MLP이다(그림 B).
매핑 네트워크는 랜덤으로 샘플링된 노이즈 벡터 z_1 ∈ R^512와 z_2 ∈ R^512를 w_1 = f_geo(z_1) 및 w_2 = f_tex(z_2)로 잠재 벡터 w_1 ∈ R^512와 w_2 ∈ R^512에 매핑하는 데 사용된다.
A.2 Geometry Generator
GET3D의 지오메트리 생성기는 생성된 형상에 걸쳐 공유되는 랜덤으로 초기화된 피처 볼륨 F_geo ∈ R^(4x4x4x256)에서 시작하여 학습 중에 학습된다.
4개의 변조된 3D 컨볼루션 블록 시리즈(그림 B의 ModBlock3D)를 통해 초기 볼륨은 w_1에 조건화된 피처 볼륨 F'_geo ∈ R^(32x32x64)로 업샘플링된다.
구체적으로, 각 ModBlock3D에서 입력 피처 볼륨은 먼저 3선 보간을 사용하여 2의 인수만큼 업샘플링된다.
그런 다음 작은 3D ResNet을 통과하며, 여기서 잔여 경로는 커널 크기가 1x1x1인 3D 컨볼루션 레이어를 사용하고, 메인 경로는 커널 크기가 3x3x3인 조건부 3D 컨볼루션 레이어 2개를 적용한다.
조건화를 수행하기 위해, 우리는 StyleGAN2[35]를 따르고 먼저 학습된 아핀 변환(그림 B의 A)을 통해 잠재 벡터 w_1을 스타일 h에 매핑한다.
그런 다음 스타일 h는
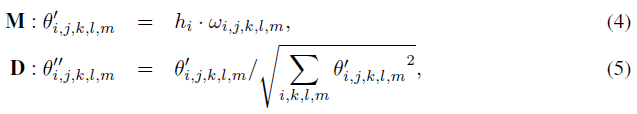
와 같이 컨볼루션 레이어의 가중치를 변조(M)하고 복조(D)하는 데 사용되며, 여기서 θ와 θ''는 각각 원래 및 변조된 가중치이다.
h_i는 i번째 입력 채널에 해당하는 style이고, j는 출력 채널 차원이며, k, l, m은 3D 컨볼루션 필터의 공간 차원을 나타낸다.
최종 피처 볼륨 F'_geo를 얻으면 사면체 그리드의 각 정점 v의 피처 벡터 f'_geo ∈ R^64를 3선 보간을 통해 얻을 수 있다.
우리는 추가적으로 포인트 p의 좌표를 [sin(p), cos(p)] 위치 인코딩(PE)에 공급하고 출력을 피쳐 벡터 f'_geo와 연결한다.
연결된 피처 벡터를 정점 오프셋 Δv ∈ R^3 또는 SDF 값 s ∈ R로 디코딩하기 위해, 우리는 그것을 세 가지 조건부 FC 레이어(그림 B의 ModFC)를 통과시킨다.
이들 레이어의 변조 및 복조는 식.5와 유사하게 수행된다.
마지막 레이어를 제외한 모든 레이어는 leaky-ReLU 활성화 함수에 따른다.
마지막 레이어에서, 우리는 SDF 예측을 [-1, 1] 이내로 정규화하거나 Δv를 [-1/tet-res, 1/tet-res] 내로 정규화하기 위해 tanh를 적용한다, 여기서 tet-res는 모든 실험에서 90으로 설정한 사면체 그리드의 해상도를 나타낸다.
단순성을 위해, 우리는 StyleGAN[34, 35]에서 모든 노이즈 벡터를 제거하고 입력 z에만 확률성을 가지고 있다는 점에 유의한다.
또한 DEFTET[22] 및 DMTET[60]의 관행에 따라 지오메트리 생성기의 복사본 2개를 사용한다.
하나는 정점 오프셋 Δv를 생성하고 다른 하나는 SDF 값을 출력합니다.
두 아키텍처는 마지막 레이어의 출력 차원과 활성화 함수를 제외하고 동일하다.
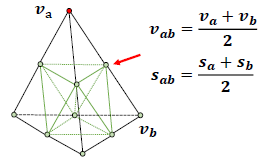
Volume Subdivision:
고해상도 모델링이 필요한 경우(예: 휠에 얇은 구조가 있는 모터바이크), DMTET[60]에 이어 볼륨 세분화를 추가로 사용한다.
그림 A에 표시된 바와 같이, 먼저 사면체 그리드를 세분화하고 가장자리의 SDF 값을 평균하여 새로운 정점(중간점)의 SDF 값을 계산한다.
그런 다음 SDF 부호가 다른 꼭짓점을 가진 사면체를 식별합니다.
이것들은 SDF에 의해 인코딩된 기본 표면과 교차하는 사면체이다.
세분화 후 증가된 그리드 해상도로 표면을 정제하기 위해, 우리는 식별된 사면체에서 정점의 업데이트 및 Δv에 대한 SDF 값 및 변형에 대한 잔류를 추가로 예측한다.
구체적으로, 우리는 추가적인 3D 컨볼루션 레이어를 사용하여 피쳐 볼륨 F'_geo를 w_1에 조건화된 형상 64x64x64x8의 F'_geo로 업샘플링한다.
그런 다음 위에서 설명한 단계에 따라 3선 보간을 사용하여 정점별 피쳐를 얻고 PE와 연결한 다음 조건부 FC 계층을 사용하여 잔차 δ_s 및 δ_v를 디코딩한다.
최종 SDF와 정점 오프셋은

로 계산된다.
A.3 Texture Generator
우리는 텍스처 필드의 3면 표현을 생성하기 위해 StyleGAN2[35]의 생성기 아키텍처를 적용한다.
지오메트리 생성기와 유사하게, 우리는 랜덤으로 초기화된 피처 그리드 F_tex ∈ R^(4x4x512)에서 시작하여, 모양에 걸쳐 공유되며, 학습 중에 학습된다.
이 초기 피처 그리드는 w_1과 w_2에 조건화된 피처 그리드 F'_tex ∈ R^(256x256x96)로 업샘플링된다.
구체적으로, 우리는 6개의 변조된 2D 컨볼루션 블록을 사용한다(그림 B의 ModBlock2D).
ModBlock2D 블록은 컨볼루션이 2D이고 조건화가 w_1 + w_2에 있다는 점을 제외하고 ModBlock3D 블록과 동일합니다, 여기서 +는 연결을 나타냅니다.
또한 각 ModBlock2D 블록의 출력은 커널 크기가 1x1인 조건부 2D 컨볼루션을 적용하는 조건부 tTPF 계층을 통해 전달됩니다.
StyleGAN2[35]의 실천요강에 따라 tTPF 레이어의 조절은 가중치의 변조(복조 없음)를 통해서만 수행된다는 점에 유의한다.
마지막 tTPF 레이어의 출력은 256x256x32 크기의 세 개의 축 정렬 피쳐 평면으로 재구성된다.
표면 점 p ∈ R^3의 피쳐 f_tex ∈ R^32를 얻기 위해, 우리는 먼저 각 평면에 p를 투영하고 피쳐의 이중 보간을 수행한 다음, 마지막으로 보간된 피쳐를 합한다:

, 여기서 π_e(p)는 피쳐 평면에 대한 점 p의 투영이고 ρ(·)는 피쳐의 이중 보간을 나타낸다.
p 지점의 c ∈ R^3 색상은 w_1 + w_2에 조건화된 3개의 조건부 FC 레이어(ModFC)를 사용하여 f에서 디코딩된다.
각 레이어의 숨겨진 차원은 16입니다.
StyleGAN2[35]에 이어 최종 출력에 정규화를 적용하지 않습니다.
A.4 2D Discriminator
우리는 GET3D를 학습시키기 위해 두 가지 판별기를 사용한다: 하나는 RGB 출력용이고 다른 하나는 2D 실루엣용입니다.
두 가지 모두에 대해, 우리는 StyleGAN의 판별기와 정확히 동일한 아키텍처를 사용한다[34].
경험적으로, 우리는 카메라 포즈에서 판별기를 조건화하는 것이 모양 방향의 표준화로 이어진다는 것을 관찰했다.
그러나 이 조건을 폐기하는 것은 섹션 C.3에 나온 것처럼 성능에 약간의 영향을 미칠 뿐이다.
실제로, 우리는 주로 이 조건화를 사용하여 평가 메트릭을 사용하여 기하학을 평가할 수 있으며, 이는 형상이 표준 프레임에서 생성된다고 가정한다.
'3D Vision' 카테고리의 다른 글
| Segment Anything in 3D with NeRFs (0) | 2024.05.16 |
|---|---|
| 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (0) | 2024.05.13 |
| Pyramid Stereo Matching Network (0) | 2022.03.25 |
| Mesh R-CNN (번역) (0) | 2022.03.23 |
| DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation (0) | 2022.03.18 |