2024. 5. 16. 10:23ㆍ3D Vision
Segment Anything in 3D with NeRFs
Jiazhong Cen, Zanwei Zhou, Jiemin Fang, Chen Yang, Wei Shen, Lingxi Xie, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian
Abstract
최근 Segment Anything Model (SAM)은 2D 이미지에서 모든 것을 세그먼트할 수 있는 강력한 비전 파운데이션 모델로 부상했습니다.
이 논문은 SAM을 3D 객체로 일반화하는 것을 목표로 합니다.
저희는 3D에서 비용이 많이 드는 데이터 획득 및 주석 절차를 복제하는 대신, 멀티-뷰 2D 이미지를 3D 공간에 연결하는 저렴하고 기성품인 Neural Radiance Field (NeRF)를 활용하여 효율적인 솔루션을 설계합니다.
저희는 제안된 솔루션을 3D의 Segment Anything의 경우 SA3D라고 부릅니다.
단일 뷰에서 타겟 객체에 대한 수동 세그먼트 프롬프트(예: 대략적인 지점)만 제공하면 되며, 이는 SAM을 사용하여 이 뷰에서 2D 마스크를 생성하는 데 사용됩니다.
다음으로, SA3D는 복셀 그리드로 구성된 타겟 객체의 3D 마스크를 반복적으로 완성하기 위해 다양한 뷰에 걸쳐 마스크 인버스 렌더링 및 교차 뷰 셀프-프롬프팅을 교대로 수행합니다.
전자는 현재 뷰에서 SAM이 얻은 2D 마스크를 NeRF에 의해 학습된 밀도 분포의 가이던스와 함께 3D 마스크에 투영합니다; 후자는 다른 뷰에서 NeRF 렌더링된 2D 마스크에서 SAM에 대한 입력으로 신뢰할 수 있는 프롬프트를 자동으로 추출합니다.
저희는 실험에서 SA3D가 다양한 장면에 적응하고 몇 분 이내에 3D 세그멘테이션을 달성한다는 것을 보여줍니다.
저희의 연구는 2D 모델이 여러 뷰에서 프롬프터블 세그멘테이션을 꾸준히 해결할 수 있는 한 2D 비전 파운데이션 모델의 기능을 3D로 끌어올릴 수 있는 잠재적인 방법론을 보여줍니다.
1 Introduction
컴퓨터 비전 커뮤니티는 모든 시나리오와 2D 또는 3D 이미지 데이터에 대해 기본 작업(예: 세그멘테이션)을 수행할 수 있는 비전 파운데이션 모델을 추구해 왔습니다.
최근 Segment Anything Model (SAM) [25]이 등장하여 2D 이미지에서 모든 것을 세그먼트할 수 있는 능력으로 인해 많은 관심을 끌었지만 SAM의 기능을 3D 장면에 일반화하는 것은 대부분 알려지지 않은 채로 남아 있습니다.
SAM의 파이프라인을 복제하여 대규모 3D 장면을 수집하고 반자동으로 주석을 달 수 있지만 대부분의 연구 그룹에서는 비용이 많이 드는 부담을 감당할 수 없는 것 같습니다.
저희는 대안적이고 효율적인 솔루션은 2D 파운데이션 모델(즉, SAM)에 3D 표현 모델을 통해 3D 인식을 갖추는 것이라는 것을 알고 있습니다.
즉, 3D 파운데이션 모델을 처음부터 구축할 필요가 없습니다.
그러나 전제 조건이 있습니다: 3D 표현 모델은 2D 뷰를 렌더링하고 2D 세그멘테이션 결과를 3D 장면에 등록할 수 있어야 합니다.
따라서 저희는 기성 솔루션으로 Neural Radiance Fields (NeRF) [38, 53, 3]를 사용합니다.
NeRF는 각 3D 장면을 여러 2D 뷰를 연결하는 3D prior 역할을 하는 심층 신경망으로 공식화하는 알고리즘 제품군입니다.

그림 1에서 볼 수 있듯이, 저희 솔루션의 이름은 Segment Anything in 3D (SA3D)입니다.
2D 이미지 세트에 대해 학습된 NeRF가 주어지면, SA3D는 단일 렌더링된 뷰에서 프롬프트(예: 객체의 점 클릭)를 입력으로 받아 SAM으로 이 뷰에서 2D 마스크를 생성하는 데 사용됩니다.
다음으로, SA3D는 다양한 뷰에서 두 단계를 교대로 수행하여 복셀 그리드로 구성된 객체의 3D 마스크를 반복적으로 완성합니다.
각 라운드에서 첫 번째 단계는 마스크 인버스 렌더링으로, NeRF가 제공하는 밀도 유도 인버스 렌더링을 통해 SAM에서 얻은 이전 2D 세그멘테이션 마스크가 3D 마스크에 투영됩니다.
두 번째 단계는 교차 뷰 셀프-프롬프팅으로, NeRF를 사용하여 3D 마스크와 다른 뷰의 이미지를 기반으로 2D 세그멘테이션 마스크(정확하지 않을 수 있음)를 렌더링한 다음 렌더링된 마스크에서 몇 개의 점 프롬프트가 자동으로 생성되어 SAM에 입력되어 보다 완벽하고 정확한 2D 마스크를 생성합니다.
위의 절차는 필요한 모든 뷰가 샘플링될 때까지 반복적으로 실행됩니다.
저희는 Replica [51] 및 NVOS [47] 데이터 세트에서 다양한(예: 객체, 부품 수준) 세그멘테이션 작업을 수행합니다.
SAM 또는 NeRF를 재학습/재설계하지 않고도 SA3D는 다양한 시나리오에 쉽고 효율적으로 적응합니다.
기존 접근 방식에 비해 SA3D는 일반적으로 몇 분 이내에 3D 세그멘테이션을 완료하는 단순화된 파이프라인을 즐깁니다.
SA3D는 3D로 무엇이든 세그멘팅할 수 있는 효율적인 도구를 제공할 뿐만 아니라 2D 파운데이션 모델을 3D 공간으로 리프트하는 일반적인 방법론을 보여줍니다.
유일한 전제 조건은 여러 뷰에 걸쳐 프롬프트할 세그멘테이션을 꾸준히 해결할 수 있는 능력에 있으며, 향후 2D 파운데이션 모델의 일반적인 속성이 되기를 바랍니다.
2 Related Work
2D Segmentation
FCN [36]이 제안된 이후, 2D 이미지 세그멘테이션에 대한 연구는 급속한 성장을 경험했습니다.
수많은 연구 [18, 24, 4, 71]에 의해 세그멘테이션의 다양한 하위 분야가 깊이 탐구되었습니다.
트랜스포머 [58, 10]가 세그멘테이션 분야에 진입함에 따라 많은 새로운 세그멘테이션 아키텍처 [72, 7, 6, 52, 63]가 제안되었고 전체 세그멘테이션 분야가 더욱 발전했습니다.
이 분야의 최근 중요한 돌파구는 Segment Anythy Model (SAM) [25]입니다.
새로운 비전 파운데이션 모델로서 SAM은 프롬프트 기반 세그멘테이션 패러다임을 도입하여 2D 세그멘테이션 작업을 통합하는 것을 목표로 하는 잠재적인 게임 체인저로 인식되고 있습니다.
SAM과 유사한 모델은 SEEM [75]으로, 인상적인 개방형 어휘 세그멘테이션 기능도 보여줍니다.
3D Segmentation
수많은 방법들이 3D 세그멘테이션을 수행하기 위해 다양한 유형의 3D 표현을 탐구해 왔습니다.
이러한 장면 표현에는 RGB-D 이미지 [60, 62, 64, 8], 포인트 클라우드 [44, 45, 70] 및 복셀 [21, 55, 35], 실린더 [74] 및 조감도 공간 [67, 16]과 같은 그리드 공간이 포함됩니다.
3D 세그멘테이션은 일정 기간 동안 개발되었지만 2D 세그멘테잉션에 비해 레이블이 지정된 데이터의 부족과 높은 계산 복잡성으로 인해 SAM과 유사한 통합 프레임워크를 설계하기가 어렵습니다.
Lifting 2D Vision Foundation Models to 3D
데이터 부족의 한계를 해결하기 위해 이전의 많은 연구 [23, 43, 9, 17, 69, 31, 65, 22]에서는 2D 파운데이션 모델을 3D로 리프팅하는 방법을 탐구했습니다.
이 연구에서 SA3D와 가장 관련이 높은 작업은 LERF [23]로, 래디언스 필드와 함께 비전-언어 모델(즉, CLIP [46])의 피처 필드를 학습합니다.
SA3D와 비교하여 LERF는 텍스트 프롬프트로 특정 객체를 coarse하게 위치시키는 데 초점을 맞추지만 세분화된 3D 세그멘테이션에는 중점을 두지 않습니다.
CLIP 피쳐에 의존하기 때문에 타겟 객체의 특정 위치 정보에 둔감합니다.
장면에 유사한 의미론을 가진 여러 객체가 있는 경우 LERF는 효과적인 3D 세그멘테이션을 수행할 수 없습니다.
나머지 방법은 주로 포인트 클라우드에 중점을 둡니다.
3D 포인트 클라우드와 특정 카메라 포즈를 2D 멀티뷰 이미지로 연결하면 2D 파운데이션 모델에 의해 추출된 피처를 3D 포인트 클라우드에 투영할 수 있습니다.
이러한 방법의 데이터 획득은 우리보다 비용이 많이 듭니다. 즉, NeRF에 대한 멀티뷰 이미지를 획득하는 데는 비용이 더 많이 듭니다.
Segmentation in NeRFs
Neural Radiance Fields (NeRF) [38, 53, 3, 1, 40, 19, 13, 61, 30, 12]는 일련의 3D 암시적 표현입니다.
3D 일관된 새로운 뷰 합성의 성공에 영감을 받아 수많은 연구에서 NeRF 내의 3D 세그멘테이션 영역을 탐구했습니다.
Zhi et al. [73]은 시맨틱을 외관과 지오메트리에 통합하는 방법인 Semantic-NeRF를 제안합니다.
그들은 레이블 전파 및 개선 분야에서 NeRF의 잠재력을 보여줍니다.
NVOS [47]는 맞춤형 설계된 3D 피쳐를 사용하여 경량 multi-layer perceptron (MLP)을 학습하여 NeRF에서 3D 객체를 선택하는 대화형 접근 방식을 도입합니다.
N3F [57], DFF [27], LERF [23] 및 ISRF [15]와 같은 다른 접근 방식은 추가 피쳐 필드 학습을 통해 2D 시각적 피쳐를 3D로 리프트하는 것을 목표로 합니다.
이러한 방법은 NeRF 모델을 재설계/재학습하는 데 필요하며 일반적으로 추가 피쳐 매칭 프로세스를 포함합니다.
NeRF와 결합된 몇 가지 다른 인스턴스 세그멘테이션 및 시맨틱 세그멘테이션 접근 방식[50, 41, 11, 68, 34, 20, 2, 14, 59, 28]도 있습니다.
3 Method
이 섹션에서는 먼저 Neural Radiance Fields (NeRFs)와 Segment Anything Model (SAM)에 대해 간략하게 설명합니다.
그런 다음 SA3D의 전체 파이프라인을 소개합니다.
마지막으로 SA3D의 각 구성 요소 설계를 자세히 시연합니다.
3.1 Preliminaries
Neural Radiance Fields (NeRFs)
멀티-뷰 2D 이미지의 학습 데이터 세트 I가 주어지면 NeRF [38]는 점의 공간 좌표 x ∈ R^3 및 뷰 방향 d ∈ S^2를 해당 컬러 c ∈ R^3 및 볼륨 밀도 σ ∈ R에 매핑하는 함수 f_θ: (x, d) → (c, σ)를 학습합니다.
θ는 일반적으로 multi-layer perceptron (MLP)으로 표현되는 함수 f의 학습 가능한 파라미터를 나타냅니다.
이미지 I_θ를 렌더링하기 위해 각 픽셀은 ray r(t) = x_o + td가 카메라 포즈를 통해 투사되는 ray 캐스팅 프로세스를 거칩니다.
여기서 x_o는 카메라 원점, d는 ray 방향, t는 원점에서 ray를 따라 있는 점의 거리를 나타냅니다.
ray r에 의해 결정된 위치의 RGB 컬러 I_θ(r)는 미분 가능한 볼륨 렌더링 알고리즘을 통해 얻어집니다:
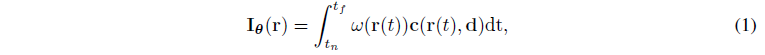
, 여기서 ω(r(t)) = exp(-∫ σ(r(s))ds · σ(r(t))), t_n 및 t_f는 각각 ray의 근거리 및 원거리를 나타냅니다.
Segment Anything Model (SAM)
SAM [25]은 이미지 I 및 프롬프트 세트 P를 입력으로 받아 해당 2D 세그멘테이션 마스크 M_SAM을 비트맵 형태, 즉

로 출력합니다.
프롬프트 p ∈ P는 포인트, 상자, 텍스트 및 마스크가 될 수 있습니다.

3.2 Overall Pipeline
저희는 데이터 세트 I에 대해 학습된 NeRF 모델이 이미 있다고 가정합니다.
본 논문에서는 달리 명시되지 않는 한 학습 및 렌더링의 우수한 효율성을 고려하여 TensoRF [3]를 NeRF 모델로 사용하기로 결정했습니다.
그림 2와 같이, 먼저 특정 뷰의 이미지 I^in이 사전 학습된 NeRF 모델로 렌더링됩니다.
프롬프트 세트(예: 본 논문에서는 포인트 세트를 자주 사용함) P^in이 렌더링된 이미지와 함께 SAM에 도입되고 공급됩니다.
뷰의 2D 세그멘테이션 마스크 M_SAM^in을 얻은 다음 제안된 마스크 인버스 렌더링 기술을 사용하여 3D 마스크 V ∈ R^3 구성 복셀 그리드에 투영됩니다(섹션 3.3).
그런 다음 새로운 뷰의 2D 세그멘테이션 마스크 M^(n)이 3D 마스크에서 렌더링됩니다.
렌더링된 마스크는 일반적으로 부정확합니다.
저희는 렌더링된 마스크에서 포인트 프롬프트 P^(n)을 추출하고 추가로 SAM에 공급하는 교차-뷰 셀프-프롬프팅 방법(섹션 3.4)을 제안합니다.
따라서 이 새로운 뷰의 보다 정확한 2D 마스크 M_SAM^(n)이 생성되고 복셀 그리드에도 투영되어 3D 마스크가 완성됩니다.
위의 절차는 더 많은 뷰가 통과하면서 반복적으로 실행됩니다.
한편, 3D 마스크는 점점 더 완성됩니다.
전체 프로세스는 2D 세그멘테이션 결과와 3D 세그멘테이션 결과를 효율적으로 연결합니다.
3D 마스크 외에는 최적화할 필요가 없습니다.
3.3 Mask Inverse Rendering
식 (1)과 같이 렌더링된 이미지에서 각 픽셀의 색상은 해당 ray를 따라 가중된 색상의 합에 의해 결정됩니다.
가중치 ω(r(t))는 3차원 공간 내의 객체 구조를 나타내며, 여기서 가중치가 높으면 객체의 표면에 가까운 해당 지점을 나타냅니다.
마스크 인버스 렌더링은 이러한 가중치에 기초하여 3차원 마스크를 형성하기 위해 2D 마스크를 3차원 공간에 투영하는 것을 목표로 합니다.
형식적으로 3D 마스크는 복셀 그리드 V ∈ R^(L×W×H)로 표현되며, 여기서 각 그리드 정점은 제로-초기화된 소프트 마스크 신뢰 점수를 저장합니다.
이러한 복셀 그리드를 기반으로 한 뷰에서 2D 마스크의 각 픽셀은

으로 렌더링되며, 여기서 r(t)는 마스크 픽셀을 통한 ray 캐스팅이며, ω(r(t)는 사전 학습된 NeRF의 밀도 값에서 상속되며, V(r(t)는 복셀 그리드 V에서 얻은 위치 r(t)에서의 마스크 신뢰 점수를 나타냅니다.
M_SAM(r)을 SAM에서 생성된 해당 마스크로 표시하십시오.
M_SAM(r) = 1일 때 마스크 인버스 렌더링의 목표는 ω(r(t))에 대한 V(r(t)를 증가시키는 것입니다.
실제로는 그래디언트 하강 알고리즘을 사용하여 이를 최적화할 수 있습니다.
이를 위해 마스크 투영 loss를 M_SAM(r)과 M(r) 사이의 음의 곱으로 정의합니다:

, 여기서 R(I)는 이미지 I의 ray 세트를 나타냅니다.
마스크 투영 loss는 NeRF의 지오메트리와와 SAM의 세그멘테이션 결과가 모두 정확하다는 가정을 기반으로 구성됩니다.
그러나 실제로는 항상 그렇지는 않습니다.
멀티뷰 마스크 일관성에 따라 3D 마스크 그리드를 최적화하기 위해 loss에 음의 개선 항을 추가합니다:

, 여기서 λ는 음의 항의 크기를 결정하는 하이퍼 파라미터입니다.
이 음의 개선 항을 사용하면 SAM이 다른 뷰에서 영역을 전경으로 일관되게 예측하는 경우에만 SA3D는 해당 3D 영역을 전경으로 표시합니다.
각 반복에서 3D 마스크 V는 그래디언트 하강이 있는 V ← V - η ∂L_proj/∂ V를 통해 업데이트되며, 여기서 η는 학습률을 나타냅니다.
3.4 Cross-view Self-prompting
마스크 인버스 렌더링을 통해 2D 마스크를 3D 공간에 투영하여 타겟 객체의 3D 마스크를 형성할 수 있습니다.
정확한 3D 마스크를 구성하려면 다양한 뷰에서 상당한 2D 마스크를 투영해야 합니다.
SAM은 적절한 프롬프트가 주어지면 고품질의 세그멘테이션 결과를 제공할 수 있습니다.
그러나 모든 뷰에서 수동으로 프롬프트를 선택하는 것은 시간이 많이 걸리고 비현실적입니다.
저희는 다양한 새로운 뷰에 대한 프롬프트를 자동으로 생성하는 교차-뷰 셀프-프롬프팅 메커니즘을 제안합니다.
구체적으로, 저희는 먼저 식 (3)에 따라 3D 마스크 그리드 V에서 새로운 뷰 2D 세그멘테이션 마스크 M^(n)을 렌더링합니다.
이 마스크는 특히 SA3D의 예비 반복 시 일반적으로 부정확합니다.
그런 다음 특정 전략으로 렌더링된 마스크에서 몇 가지 포인트 프롬프트를 얻습니다.
위의 프로세스를 교차-뷰 셀프-프롬프팅이라고 합니다.
이 전략에는 여러 가지 가능한 솔루션이 있지만, 효과적인 것으로 입증된 실현 가능한 솔루션을 제시합니다.
Self-prompting Strategy
부정확한 2D 렌더링 마스크 M^(n)이 주어지면 셀프-프롬프팅 전략은 여기서 프롬프트 포인트 P_s 세트를 추출하는 것을 목표로 하며, 이는 SAM이 2D 세그멘테이션 결과를 가능한 한 정확하게 생성하는 데 도움이 될 수 있습니다.
M^(n)은 일반적인 2D 비트맵이 아니라 식 (3)을 사용하여 계산된 신뢰 점수 맵이라는 점에 유의해야 합니다.
각 이미지 픽셀 p는 렌더링 뷰에서 ray r에 해당하기 때문에 이미지에서 프롬프트 선택 전략을 더 쉽게 시연하기 위해 p를 사용합니다.
P_s가 빈 세트로 초기화되면 마스크 신뢰도 점수가 가장 높은 포인트로 첫 번째 프롬프트 포인트 p_0이 선택됩니다: p_0 = arg max_p M^(n)(p).
새로운 프롬프트 포인트를 선택하기 위해 먼저 각 기존 포인트 프롬프트 ˆp ∈ P_s를 중심으로 하는 M^(n)의 정사각형 모양 영역을 마스킹합니다.
depth z(p)는 사전 학습된 NeRF에 의해 추정될 수 있음을 고려하여 2D 픽셀 p를 3D 점 G(p) = (x(G(p)), y(G(p)), z(G(p))로 변환합니다:
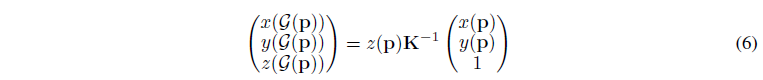
, 여기서 x(p), y(p)는 p의 2차원 좌표를 나타내고, K는 카메라 intrinsics을 나타냅니다.
새로운 프롬프트 포인트는 기존 프롬프트 포인트에 가깝지만 높은 신뢰도 점수를 가질 것으로 예상됩니다.
두 요소를 고려하여 신뢰도 점수에 감쇠 항을 도입합니다.
d(·,·)를 최소-최대 정규화 유클리드 거리로 표시합니다.
M^(n)의 각 나머지 포인트 p에 대해 감쇠 항은

입니다.
그런 다음 감쇠 마스크 신뢰도 점수 ˜ M^(n)(p)는

과 같이 계산됩니다.
가장 높은 감쇠 점수를 가진 나머지 지점, 즉 p∗ = arg max_(p/∈ P_s) ˜ M^(n)(p)가 프롬프트 세트에 추가됩니다: P_s = P_s ∪ {p∗}.
상기 선택 프로세스는 프롬프트 수 |P_s|가 미리 정의된 임계값 n_p에 도달하거나 ˜ M^(n)(p)의 최대값이 0보다 작을 때까지 반복됩니다.
IoU-aware View Rejection
타겟 객체가 심하게 가려진 뷰로 렌더링되면 SAM이 잘못된 세그멘테이션 결과를 생성하고 3D 마스크의 품질을 저하시킬 수 있습니다.
이러한 상황을 방지하기 위해 렌더링된 마스크 M^(n)과 SAM 예측 M_SAM^(n) 사이의 intersection-over-union (IoU)을 기반으로 하는 추가 뷰 거부 메커니즘을 도입합니다.
IoU가 미리 정의된 임계값 τ 아래에 있으면 두 마스크 간의 중첩이 좋지 않음을 나타냅니다.
SAM의 예측이 거부되고 이 반복에서 마스크 인버스 렌더링 단계가 생략됩니다.
4 Experiments
이 섹션에서는 다양한 데이터 세트에서 SA3D의 세그멘테이션 능력을 정량적으로 평가합니다.
그런 다음 인스턴스 세그멘테이션, 파트 세그멘테이션, 텍스트 프롬프트 세그멘테이션 등을 수행할 수 있는 SA3D의 다양한 활용성을 정성적으로 보여줍니다.
4.1 Datasets
정량적 실험을 위해 Neural Volumetric Object Selection (NVOS) [47], SPIn-NeRF [39] 및 Replica [51] 데이터 세트를 사용합니다.
NVOS [47] 데이터 세트는 여러 개의 전방 장면을 포함하는 LLFF 데이터 세트 [37]를 기반으로 합니다.
각 장면에 대해 NVOS는 scribble 참조 뷰와 2D 세그멘테이션 마스크에 주석이 달린 타겟 뷰를 제공합니다.
NVOS와 유사하게 SPIn-NeRF [39]는 대화형 3D 세그멘테이션 성능을 평가하기 위해 일부 데이터에 수동으로 주석을 달습니다.
이러한 주석은 널리 사용되는 일부 NeRF 데이터 세트 [37, 38, 29, 26, 13]를 기반으로 합니다.
Replica [51] 데이터 세트는 깨끗한 조밀 지오메트리, 고해상도 및 고동적 범위 텍스처, 유리 및 거울 표면 정보, 시맨틱 클래스, 평면 세그멘테이션 및 인스턴스 세그멘테이션 마스크를 포함한 다양한 실내 장면의 고품질 재구성 ground truth를 제공합니다.
정성적 분석을 위해 LLFF [37] 데이터 세트와 360˚ 데이터 세트 [1]를 사용합니다.
SA3D는 보다 현실적이고 어려운 장면을 포함하는 LERF [23] 데이터 세트에 추가로 적용됩니다.
4.2 Quantitative Results
NVOS Dataset
공정한 비교를 위해 원본 NVOS [47]의 실험 설정을 따릅니다.
저희는 먼저 참조 뷰 (NVOS 데이터 세트 제공)에 scribble하여 3D 세그멘테이션을 수행한 다음 타겟 뷰에 3D 세그멘테이션 결과를 렌더링하고 제공된 ground truth를 사용하여 IoU 및 픽셀별 정확도를 평가합니다.
scribble는 SAM의 요구 사항을 충족하도록 전처리됩니다.
자세한 내용은 부록에서 확인할 수 있습니다.
표 1에서 볼 수 있듯이 SA3D는 이전 접근 방식을 큰 폭으로 능가합니다, 즉, 이전 SOTA ISRF보다 +6.5mIoU, NVOS보다 +20.2mIoU입니다.

SPIn-NeRF Dataset
저희는 평가를 위해 SPIn-NeRF [39]를 따라 레이블 전파를 수행합니다.
타겟 객체의 특정 참조 뷰가 주어지면 이 뷰의 2D ground-truth 마스크를 사용할 수 있습니다.
프롬프트 입력 작업은 생략되지만 참조 뷰의 타겟 객체의 2D ground-truth 마스크는 3D 마스크 그리드의 초기화에 직접 사용됩니다.
대부분의 상황에서 사용자는 입력 프롬프트를 정제하여 SAM이 참조 뷰에서 가능한 한 정확하게 2D 마스크를 생성할 수 있도록 도울 수 있기 때문에 합리적입니다.
3D 마스크 그리드가 초기화되면 후속 단계는 섹션 3에서 설명한 것과 정확히 동일합니다.
3D 마스크 그리드가 완료되면 다른 뷰의 2D 마스크가 렌더링되어 2D ground-truth 마스크로 IoU를 계산합니다.
결과는 표 2에서 확인할 수 있습니다.
SA3D는 forward-facing 및 360˚ 장면 모두에서 우수한 것으로 입증되었습니다.
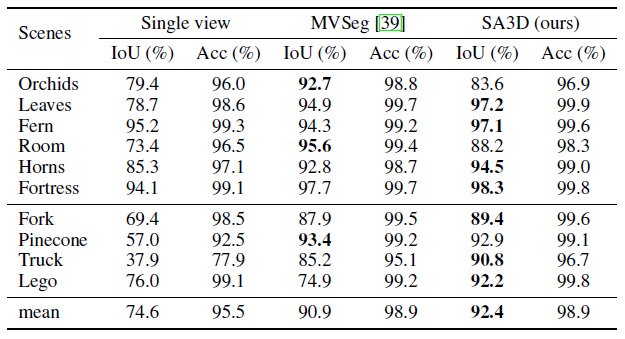

표 2와 3에서 "Single view"는 참조 뷰의 2D ground-truth 마스크 전용 마스크 인버스 렌더링을 수행하는 것을 의미합니다.
이 프로세스는 후속 학습/업데이트 단계 없이 해당 depth 정보를 기반으로 2D 마스크를 3D 공간에 매핑하는 것과 동일합니다.
저희는 프레임워크에서 대체된 프로세스의 이점을 입증하기 위해 이러한 결과를 제시합니다.
표 2에서 볼 수 있듯이 SA3D는 대부분의 장면에서 MVSeg [39]보다 성능이 뛰어나며, 특히 Truck의 +5.6mIoU와 Lego의 +17.3mIoU를 능가합니다.
또한 "Single view" 모델과 비교하여 상당한 프로모션, 즉 +17.8mIoU가 달성되어 우리 방법의 효과를 더욱 입증했습니다.
Replica Dataset
저희는 Zhi et al. [73]에서 제공한 2D 인스턴스 레이블이 있는 처리된 Replica 데이터를 사용하여 SA3D의 세그멘테이션 성능을 평가합니다.
저희는 각 개체를 포함하는 모든 뷰를 검색하고 하나의 참조 뷰를 지정합니다.
SPIn-NeRF 데이터 세트에 대한 유사한 실험 설정으로 참조 뷰의 ground-truth 마스크를 사용하고 SA3D를 수행하여 평가를 위해 레이블 전파를 수행합니다.
Replica의 각 장면에 대해 약 20개의 개체가 평가를 위해 선택됩니다.
자세한 내용은 부록을 참조하십시오.
표 3과 같이 다양한 장면에서 사용 가능한 모든 개체에 대해 평균 IoU(mIoU)가 보고됩니다.
개체는 Replica의 실내 장면에서 몇 개의 뷰에만 나타나기 때문에 픽셀 단위 정확도 메트릭을 제외합니다.
Replica의 복잡한 실내 장면에서 비디오 세그멘테이션을 기반으로 한 MVSeg의 전략은 효과가 없는 것으로 판명되었으며, 이는 정제를 위해 Semantic-NeRF[73]를 사용하더라도 수많은 부정확한 2D pseudo-레이블을 생성합니다.
결과적으로 MVSeg의 최종 3D 세그멘테이션 결과는 "Single view" 방법으로 달성한 결과보다 성능이 떨어집니다.
대조적으로 SA3D는 복잡한 3D 장면에서 세그멘트된 객체를 정확하게 캡처합니다.
시각화 결과는 그림 3에 나와 있습니다.

4.3 Qualitative Results
저희는 세 가지 종류의 세그멘테이션 작업을 수행합니다: 객체 세그멘테이션, 파트 세그멘테이션 및 텍스트 프롬프팅 세그멘테이션.
처음 두 가지는 SA3D의 핵심 기능입니다.
그림 3에서 볼 수 있듯이 SA3D는 객체가 작은 규모의 경우에도 다양한 장면에 걸쳐 다양한 3D 객체를 세그멘트할 수 있는 능력을 보여줍니다.
또한 SA3D는 어려운 파트 세그멘테이션도 처리할 수 있습니다.
그림의 마지막 행은 Lego bulldozer의 버킷, 작은 바퀴 및 돔 라이트에 대한 SA3D의 정확한 세그멘테이션을 보여줍니다.
그림 4는 언어 모델과 결합하는 데 있어 SA3D의 잠재력을 보여줍니다.
텍스트 구문이 주어지면 해당 객체를 정확하게 잘라낼 수 있습니다.
텍스트 프롬프팅 세그멘테이션은 텍스트 프롬프트를 기반으로 객체에 대한 바운딩 박스를 생성할 수 있는 모델인 Grounding-DINO [33]를 기반으로 합니다.
이러한 바운딩 박스는 세그멘테이션 프로세스에서 SA3D의 입력 프롬프트 역할을 합니다.

4.4 Ablation Study
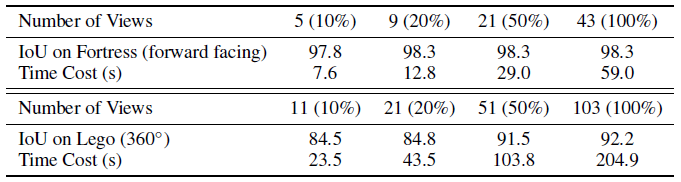
Number of Views
마스크 인버스 렌더링 및 교차 뷰 셀프-프롬프팅 프로세스는 서로 다른 뷰에 걸쳐 번갈아 사용됩니다.
기본적으로 저희는 학습 세트 I에서 사용 가능한 모든 뷰를 활용합니다.
그러나 3D 세그멘테이션 절차를 신속하게 진행하기 위해 뷰 수를 줄일 수 있습니다.
표 4에서 볼 수 있듯이 SPIn-NeRF [39] 데이터 세트에서 두 개의 대표적인 장면에 대한 실험을 수행하여 이러한 특성을 입증합니다.
뷰는 정렬된 학습 세트에서 균일하게 샘플링됩니다.
카메라 포즈의 범위가 제한된 전방 장면에서는 몇 개의 뷰만 선택하여 만족스러운 결과를 얻을 수 있습니다.
Nvidia RTX 3090 GPU에서는 5개의 뷰로 3D 세그멘테이션 프로세스를 10초 이내에 완료할 수 있습니다.
반대로 카메라 포즈의 범위가 더 넓은 장면에서는 더 많은 수의 뷰가 필요하여 더 큰 개선을 얻을 수 있습니다.
50개의 뷰를 사용하더라도 세그멘테이션 작업을 2분 이내에 완료할 수 있습니다.
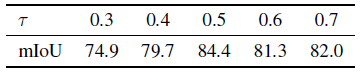

Hyper-parameters
SA3D는 세 가지 하이퍼 파라미터를 포함합니다: IoU 거부 임계값 τ, 식 (5)의 loss 균형 계수 λ 및 셀프-프롬프팅 포인트 n_p의 수.
표 6과 같이 너무 작은 τ 값은 불안정한 SAM 예측으로 이어져 3D 마스크에 노이즈를 도입합니다.
너무 큰 τ 값은 3D 마스크가 상당한 정보를 얻는 것을 방해합니다.
표 7은 λ 계수를 가진 음의 항을 약간 도입하면 마스크 투영에 대한 노이즈를 줄일 수 있음을 나타냅니다.
그러나 너무 큰 음의 항은 마스크 완성 프로세스를 불안정하게 만들고 성능 저하를 유발할 수 있습니다.
SAM은 개체의 세부 정보를 캡처하는 과도한 세그먼트 결과를 생성하는 경향이 있기 때문에 n_p의 선택은 특정 세그멘테이션 타겟에 따라 달라집니다.
그림 5와 같이 상대적으로 규모가 크고 구조가 복잡한 개체의 경우 더 큰 n_p가 더 나은 결과를 생성합니다.
경험적으로 np를 3으로 설정하면 대부분의 상황의 요구 사항을 충족할 수 있습니다.

Self-prompting Strategy
3D 거리 기반 신뢰도 붕괴(식 (7))가 없으면 셀프-프롬프팅 전략은 신뢰도 점수가 가장 높은 프롬프트 지점을 선택한 다음 주변 영역을 마스킹하는 간단한 2D NMS (Non-Maximum Suppression)로 저하됩니다.
설계의 효율성을 보여주기 위해 NVOS 벤치마크를 사용하여 실험을 수행하고 심층 분석을 위해 장면별 결과를 제시합니다.

표 5는 간단한 NMS 셀프-프롬프팅이 대부분의 경우에 충분하다는 것을 보여줍니다.
그러나 많은 수의 depth가 점프하는 'LLFF-trex' (그림 5와 같은 trex 골격)와 같은 하드 케이스의 경우 신뢰 붕괴 항이 많은 기여를 합니다.
이러한 상황에서 부정확한 마스크는 전경의 틈을 통해 배경으로 출혈합니다.
셀프-프롬프팅 메커니즘이 이러한 부정확한 영역에 대해 프롬프트를 생성하면 SAM은 IoU 거부 메커니즘을 속일 수 있는 그럴듯한 세그멘테이션 결과를 생성하고 마지막으로 세그멘테이션 결과에는 원하지 않는 배경 영역이 포함됩니다.
2D Segmentation Models
SAM 외에도 SA3D의 일반화 능력을 입증하기 위해 4개의 다른 프롬프트 기반 2D 세그멘테이션 모델[75, 49, 32, 5]을 프레임워크에 통합했습니다.
NVOS 데이터 세트에 대한 평가 결과는 표 8에 나와 있습니다.

5 Discussion
실험 결과 외에도 SAM과 NeRF를 통합하는 예비 연구, 즉 2D 파운데이션 모델과 3D 표현 모델에서 몇 가지 통찰력을 제공하기를 바랍니다.

먼저, NeRF는 SAM의 세그멘테이션 품질을 향상시킵니다.
그림 6에서 저희는 SA3D가 SAM의 세그멘테이션 오류를 제거하고 구멍 및 가장자리와 같은 세부 정보를 효과적으로 캡처할 수 있음을 보여줍니다.
지각적으로 다른 2D 인식 모델뿐만 아니라 SAM도 종종 관점에 민감하며, NeRF는 3D 모델링의 기능을 제공하므로 인식을 지원하는 보완성을 제공합니다.
또한 SA3D는 파운데이션 모델이 셀프-프롬프트할 수 있는 능력이 있는 한 NeRF 또는 기타 3D 구조적 prior를 사용하는 것이 비전 파운데이션 모델을 2D에서 3D로 끌어올리는 리소스 효율적인 방법임을 영감을 줍니다.
이 방법론은 많은 양의 3D 데이터 말뭉치를 수집하는 데 비용이 많이 들기 때문에 많은 리소스를 절약할 수 있습니다.
저희는 2D 파운데이션 모델의 3D 인식 능력을 향상시키기 위한 연구 노력(예: 2D 사전 학습에 3D 인식 loss 주입)을 기대합니다.
Limitation
SA3D는 panoptic 세그멘테이션에 한계가 있습니다.
첫째, 현재 패러다임은 첫 번째 뷰 프롬프트에 의존합니다.
프롬프트를 위한 뷰에 일부 개체가 나타나지 않으면 후속 세그멘테이션 프로세스에서 생략됩니다.
둘째, 장면의 동일한 부분은 다른 뷰에서 유사한 의미를 가진 다른 인스턴스로 세그멘트될 수 있습니다.
이러한 모호성은 현재 메커니즘 설계 하에서 쉽게 제거될 수 없으며 불안정한 학습으로 이어집니다.
이러한 문제는 향후 작업으로 남겨 둡니다.
6 Conclusion
이 논문에서는 neural radiance fields (NeRF)를 구조적 prior로 사용하여 SAM을 3D 객체를 세그멘트하는 새로운 프레임워크인 SA3D를 제안합니다.
학습된 NeRF와 단일 뷰의 프롬프트 세트를 기반으로 SA3D는 새로운 2D 뷰 렌더링, 2D 세그멘테이션을 위한 SAM 셀프-롬프팅, 세그멘테이션을 다시 3D 마스크 그리드에 투영하는 반복 절차를 수행합니다.
SA3D는 광범위한 3D 세그멘테이션 작업에 효율적으로 적용될 수 있습니다.
저희 연구는 비전 파운데이션 모델을 2D에서 3D로 리프트하는 자원 효율적인 방법론을 조명합니다.
'3D Vision' 카테고리의 다른 글
| Compact 3D Gaussian Representation for Radiance Field (1) | 2025.01.13 |
|---|---|
| LRM: Large Reconstruction Model for Single Image to 3D (0) | 2024.05.29 |
| 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (0) | 2024.05.13 |
| GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images (0) | 2023.02.01 |
| Pyramid Stereo Matching Network (0) | 2022.03.25 |