2025. 1. 13. 12:17ㆍ3D Vision
Compact 3D Gaussian Representation for Radiance Field
Joo Chan Lee, Daniel Rho, Xiangyu Sun, Jong Hwan Ko, Eunbyung Park
Abstract
Neural Radiance Fields (NeRFs)는 복잡한 3D 장면을 높은 충실도로 캡처하는 데 있어 놀라운 잠재력을 보여주었습니다.
그러나 NeRFs의 광범위한 채택을 방해하는 지속적인 도전 과제 중 하나는 볼륨 렌더링으로 인한 계산 병목 현상입니다.
반면, 3D Gaussian splatting (3DGS)은 최근 3D 가우시안 기반 표현을 활용하고, 볼륨 렌더링 대신 래스터화 파이프라인을 채택하여 이미지를 렌더링하는 대안적인 표현으로 떠오르고 있습니다, 이는 매우 빠른 렌더링 속도와 유망한 이미지 품질을 달성합니다.
그러나 3DGS는 렌더링된 이미지의 높은 충실도를 유지하기 위해 상당한 수의 3D 가우시안을 필요로 하기 때문에 상당한 단점이 발생합니다.
이 중요한 문제를 해결하기 위해, 우리는 두 가지 주요 목표를 특별히 강조합니다: 성능을 희생하지 않으면서 가우시안 포인트의 수를 줄이고 뷰 의존 색상 및 공분산과 같은 가우시안 속성을 압축합니다.
이를 위해 우리는 고성능을 유지하면서 가우시안의 수를 크게 줄이는 학습 가능한 마스크 전략을 제안합니다.
또한, 구형 고조파에 의존하지 않고 그리드 기반의 신경망을 사용하여 뷰 의존 색상을 간결하지만 효과적으로 표현할 수 있는 방법을 제안합니다.
마지막으로, 벡터 양자화를 통해 가우시안의 기하학적 속성을 간결하게 표현하는 코드북을 학습합니다.
양자화 및 엔트로피 코딩과 같은 모델 압축 기법을 통해 3DGS에 비해 25배 이상의 저장 공간을 줄이고 렌더링 속도를 향상시키면서도 장면 표현의 품질을 유지합니다.
우리의 연구는 3D 장면 표현을 위한 포괄적인 프레임워크를 제공하여 고성능, 빠른 학습, 간결성 및 실시간 렌더링을 달성합니다.
1. Introduction
신경 렌더링 분야는 최근 몇 년 동안 제한된 입력 데이터로 사진사실적인 3D 장면을 렌더링하려는 노력에 힘입어 상당한 발전을 이루었습니다.
선구적인 접근 방식 중에서 Neural Radiance Field (NeRF) [28]은 다양한 응용 분야에서 오직 2D 이미지 모음만으로 고화질 이미지를 생성하고 장면을 3D로 재구성하는 놀라운 능력으로 상당한 주목을 받고 있습니다.
후속 연구 노력은 이미지 품질을 향상시키고 [2, 30], 학습 및 렌더링 속도를 가속화하며 [7, 8, 10, 11, 30, 34], 메모리 및 저장 공간을 줄이는 데 전념하고 있습니다 [35, 40].
막대한 노력에도 불구하고 NeRF의 광범위한 채택을 방해하는 지속적인 도전 과제 중 하나는 볼륨 렌더링으로 인한 계산 병목 현상입니다.
픽셀을 렌더링하기 위해 ray를 따라 밀집된 포인트 샘플링이 필요하고, 이는 상당한 계산 자원을 필요로 하기 때문에 NeRF는 종종 핸드헬드 장치나 저가형 GPU에서 실시간 렌더링을 달성하지 못합니다.
이 도전 과제는 다양한 인터랙티브 3D 애플리케이션과 같이 빠른 렌더링 속도가 필수적인 실제 시나리오에서는 NeRF의 사용을 제한합니다.
3D Gaussian splatting (3DGS) [18]은 최근 매우 빠른 렌더링 속도와 유망한 이미지 품질을 달성한 대체 표현으로 떠오르고 있습니다.
이 접근 방식은 3D 가우시안 속성과 관련된 포인트 기반 표현을 활용하며, 볼륨 렌더링 대신 래스터화 파이프라인을 채택하여 이미지를 렌더링합니다.
병렬성을 극대화하기 위해 고도로 최적화된 맞춤형 쿠다 커널과 영리한 알고리즘 트릭을 통해 이미지 품질을 저하시키지 않으면서 전례 없는 렌더링 속도를 가능하게 합니다.
그러나 3DGS는 렌더링된 이미지의 높은 충실도를 유지하기 위해 상당한 수의 3D 가우시안을 필요로 하기 때문에 상당한 단점이 발생합니다 (그림 1 참조), 이는 많은 양의 메모리와 저장 (예: 대규모 실제 장면을 표현하기 위해 종종 1GB 이상)을 필요로 합니다.

3DGS에서 중요한 대용량 메모리 및 저장 문제를 해결하기 위해, 우리는 컴팩트 3D 가우시안 표현 프레임워크를 제안합니다.
이 접근 방식은 그림 1과 같이 고품질 재구성, 빠른 학습 속도 및 실시간 렌더링을 보여주면서 메모리 및 저장 효율성을 크게 향상시킵니다.
우리는 두 가지 주요 목표에 특별히 중점을 둡니다.
첫째, 성능을 희생하지 않으면서 장면 표현에 필요한 가우시안 포인트의 수를 줄이는 것을 목표로 합니다.
가우시안의 수는 복제와 분할로 구성된 규칙적인 밀도화 과정에 따라 증가하며, 이는 장면의 세부 사항을 표현하는 데 중요한 요소였습니다.
그러나 현재의 밀도화 알고리즘은 쓸모없고 불필요한 가우시안을 많이 생성하여 높은 메모리 및 저장 요구 사항을 초래한다는 것을 관찰했습니다.
우리는 전체 성능에 미치는 영향을 최소화하는 비필수 가우시안을 식별하고 제거하는 새로운 볼륨 기반 마스킹 전략을 소개합니다.
제안된 마스킹 방법을 사용하여 학습 중에 높은 성능을 달성하면서 가우시안의 수를 줄이는 방법을 학습합니다.
효율적인 메모리 및 저장 사용 외에도 계산 복잡성이 가우시안의 수에 선형적으로 비례하기 때문에 더 빠른 렌더링 속도를 달성할 수 있습니다.
둘째, 뷰 의존 색상 및 공분산과 같은 가우시안 속성을 압축할 것을 제안합니다.
원래 3DGS에서는 각 가우시안이 고유한 속성을 가지고 있으며, 다양한 유형의 신호 압축에 널리 사용되어 온 공간 중복성을 활용하지 않습니다.
예를 들어, 인접한 가우시안은 유사한 색상 속성을 공유할 수 있으며, 인접한 가우시안의 유사한 색상을 재사용할 수 있습니다.
이러한 동기를 고려하여, 우리는 뷰 의존 색상을 효율적으로 표현하기 위해 그리드 기반 신경망을 통합합니다.
쿼리 가우시안 포인트가 제공되면, 각 가우시안에 대해 별도로 저장할 필요 없이 컴팩트 그리드 표현에서 색상 속성을 추출합니다.
초기 접근 방식에서는 컴팩트성과 빠른 처리 속도로 인해 여러 후보 중에서 해시 기반 그리드 표현(Instant NGP [30])을 선택했습니다.
이 선택은 3DGS의 공간 복잡도를 크게 감소시켰습니다.
색상 속성과 달리, 대부분의 가우시안은 스케일과 회전 속성의 변화가 제한적인 유사한 지오메트리를 보입니다.
3DGS는 수많은 작은 가우시안들이 집합적으로 존재하는 장면을 나타내며, 각 가우시안 프리미티브는 높은 다양성을 보이지 않을 것으로 예상됩니다.
따라서 우리는 가우시안의 지오메트리를 모델링하기 위한 코드북 기반 접근 방식을 소개합니다.
이 접근 방식은 각 장면에서 공유되는 유사한 패턴이나 지오메트리를 찾는 방법을 학습하고 각 가우시안에 대한 코드북 인덱스만 저장하여 매우 간결한 표현을 제공합니다.
게다가 코드북 크기가 상당히 작을 수 있기 때문에 학습 중 공간 및 계산 오버헤드가 크지 않습니다.
우리는 제안된 컴팩트 3D 가우시안 표현을 실제 장면과 합성 장면을 포함한 다양한 데이터셋에서 광범위하게 테스트했습니다.
데이터셋에 관계없이 실험을 통해 약 15배 감소된 저장 공간과 향상된 렌더링 속도를 일관되게 보여주면서도 장면 표현의 품질은 3DGS에 비해 유지했습니다.
또한, 우리의 방법은 양자화 및 엔트로피 코딩과 같은 간단한 후처리를 통해 데이터셋 전반에 걸쳐 25배 이상의 압축을 달성할 수 있습니다.
특히 실제 데이터셋인 Deep Blending [16]에서의 평가에서는 저장 효율성이 28배 이상 향상되고 렌더링 속도가 거의 40% 증가하여 새로운 SOTA 벤치마크를 설정하는 등 3DGS를 능가하는 성능을 보였습니다.
2. Related Work
2.1. Neural Radiance Fields
Neural radiance fields (NeRF)는 3D 장면 재구성과 새로운 뷰 합성의 지평을 크게 확장시켰습니다.
NeRF [28]는 Multilayer Perceptrons (MLP)을 활용하여 볼륨 피쳐를 표현하고 볼륨 렌더링을 도입하는 새로운 3D 장면 합성 접근 방식을 도입했습니다.
초기부터 다양한 재구성 해상도 [2, 3], 학습 샘플 수 감소 [32, 36, 42, 44, 47], 대형 현실 장면 [29, 24, 33] 및 동적 장면 [12, 23, 33] 등 다양한 시나리오에서 성능을 향상시키기 위한 다양한 작업이 제안되었습니다.
그러나 NeRF의 MLP 의존도는 특히 느린 학습과 추론을 초래하는 병목 현상을 초래했습니다.
이러한 한계를 해결하기 위한 노력의 일환으로 그리드 기반 방법이 유망한 대안으로 떠올랐습니다.
명시적인 복셀 그리드 구조를 사용하는 이러한 접근 방식 [4, 9, 10, 25, 26, 39]은 전통적인 MLP 기반 NeRF 방법에 비해 학습 속도가 크게 향상된 것으로 나타났습니다.
그럼에도 불구하고, 이러한 발전에도 불구하고 그리드 기반 방법은 여전히 상대적으로 느린 추론 속도로 인해 많은 양의 메모리가 필요합니다.
이는 보다 실용적이고 널리 적용 가능한 솔루션으로 나아가는 데 상당한 장애물이 되었습니다.
후속 연구 노력은 그리드 인수분해 [6, 7, 11, 13, 15, 31], 해시 그리드 [30], 그리드 양자화 [38, 40] 또는 프루닝 [10, 35]을 통해 성능 품질을 유지하거나 향상시키면서 메모리 사용량을 줄이는 방향으로 진행되었습니다.
이러한 방법들은 또한 3D 장면 표현의 빠른 학습에 중요한 역할을 하여 계산 자원을 보다 효율적으로 활용할 수 있게 되었습니다.
그러나 여전히 남아 있는 지속적인 도전 과제는 대규모 장면의 실시간 렌더링을 달성하는 능력입니다.
이러한 방법들에 내재된 볼륨 샘플링은 그 발전에도 불구하고 여전히 한계를 가지고 있습니다.
2.2. Point-based Rendering and Radiance Field
Point-NeRF [45]는 볼륨 렌더링을 통해 래디언스 필드를 표현하기 위해 포인트를 사용했습니다.
비록 유망한 성능을 보여주지만, 볼륨 렌더링은 실시간 렌더링을 방해합니다.
NeRF 스타일의 볼륨 렌더링과 포인트 기반 α-블렌딩은 기본적으로 동일한 렌더링 모델을 공유하지만 렌더링 알고리즘에서는 크게 다릅니다 [18].
NeRF는 전체 볼륨을 빈 공간이나 점유된 공간으로 연속적으로 피쳐 표현할 수 있으며, 이는 픽셀을 렌더링하는 데 비용이 많이 드는 볼륨 샘플링을 필요로 하여 높은 계산 요구를 초래합니다.
반면, 포인트는 포인트의 생성, 파괴 및 이동에 의해 볼륨 지오메트리의 비정형적이고 이산적인 표현을 제공하며, 픽셀과 겹치는 여러 정렬된 포인트를 혼합하여 픽셀을 렌더링합니다.
이는 불투명도와 위치를 최적화하여 [20] 전체 볼륨 표현에 내재된 한계를 극복하고 놀랍도록 빠른 렌더링을 달성함으로써 달성됩니다.
포인트 기반 방법은 3D 장면을 렌더링하는 데 널리 사용되어 왔으며, 가장 간단한 형태는 포인트 클라우드입니다.
그러나 포인트 클라우드는 구멍이나 앨리어싱과 같은 시각적 아티팩트를 초래할 수 있습니다.
이를 완화하기 위해 포인트 기반 신경 렌더링 방법이 제안되었으며, 래스터화 기반 포인트 스플랫팅과 미분 가능한 래스터화를 통해 포인트를 처리했습니다 [22, 43, 46].
포인트들은 신경 피쳐로 표현되었고 CNN으로 렌더링되었습니다 [1, 20, 27].
그러나 이러한 방법들은 초기 지오메트리를 위해 Multi-View Stereo (MVS)에 크게 의존하며, 특히 피쳐가 없는 영역, 반짝이는 표면 또는 fine 구조와 같은 도전적인 시나리오에서 그 한계를 물려받습니다.
Neural Point Catacostics [21]은 MLP를 사용하여 뷰 의존적 효과 문제를 해결했지만, 여전히 입력에 있어 MVS 지오메트리에 의존합니다.
MVS 없이 Zhang et al. [49]은 방향 제어를 위해 Spherical Harmonics (SH)를 통합했습니다.
그러나 이 방법은 단일 객체로 장면을 관리하는 데 제한이 있으며 초기화 단계에서 마스크를 사용해야 합니다.
최근에는 3D Gaussian Splatting (3DGS) [18]이 실시간 신경 렌더링을 위한 기본 요소로 3D 가우시안을 사용하는 것을 제안했습니다.
3DGS는 고도로 최적화된 맞춤형 CUDA 커널과 독창적인 알고리즘 접근 방식을 활용하여 이미지 품질을 희생하지 않으면서도 탁월한 렌더링 속도를 달성합니다.
3DGS는 각 ray에 대해 밀집된 샘플링을 필요로 하지 않지만, 결과적으로 렌더링된 이미지에서 높은 품질을 유지하기 위해서는 상당한 수의 3D 가우시안이 필요합니다.
또한, 각 가우시안은 공분산 행렬이나 높은 차수의 SH와 같은 여러 렌더링 관련 속성으로 구성되어 있기 때문에 3DGS는 현실적인 장면을 위해 1GB를 초과하는 등 상당한 메모리 및 저장 자원을 필요로 합니다.
우리의 연구는 높은 렌더링 품질, 빠른 학습 및 실시간 렌더링을 유지하면서 이러한 매개변수 집약적인 요구 사항을 완화하는 것을 목표로 합니다.
3. Method
Background.
우리의 접근 방식에서는 3D 장면을 표현하기 위한 3D 가우시안 속성과 관련된 포인트 기반 표현인 3D Gaussian Splatting (3DGS) [18]을 기반으로 합니다.
각 가우시안은 3D 위치, 불투명도, 지오메트리 (3D 스케일 및 3D 회전을 쿼터니언으로 나타냄), 그리고 뷰 의존 색상에 대한 spherical harmonics (SH)를 나타냅니다.
3DGS는 COLMAP [37]과 같이 Structure-from-Motion (SfM)으로 얻은 희소 데이터 포인트에서 파생된 초기 3D 가우시안을 구성합니다.
이러한 가우시안은 복제, 분할, 프루닝 및 정제되어 장면의 정확한 묘사를 위해 anisotropic 공분산을 향상시킵니다.
이 학습 과정은 불필요한 계산 없이 빈 공간에서 미분 가능한 렌더링의 그래디언트를 기반으로 하며, 이는 학습 및 렌더링을 가속화합니다.
그러나 3DGS의 고품질 재구성은 메모리 및 저장 요구 사항, 특히 학습 중에 수많은 가우시안과 관련 속성이 증가하는 대가를 치르게 됩니다.

Overall architecture.
우리의 주요 objective는 1) 가우시안의 수를 줄이고 2) 원래 성능을 유지하면서 속성을 간결하게 표현하는 것입니다.
이를 위해 최적화 과정과 함께 성능에 최소한의 영향을 미치고 지오메트리 속성을 코드북으로 나타내는 가우시안을 그림 2와 같이 마스킹합니다.
우리는 색상 속성을 각 가우시안마다 직접 저장하지 않고 그리드 기반 신경망을 사용하여 표현합니다.
스케일 및 회전과 같은 지오메트리 속성의 경우, 이러한 속성의 제한된 변형을 충분히 활용할 수 있는 코드북 기반 방법을 사용할 것을 제안합니다.
마지막으로, 이미지 렌더링을 위한 투영 및 래스터화를 포함한 후속 렌더링 단계에서 컴팩트 속성을 가진 소수의 가우시안을 사용합니다.
3.1. Gaussian Volume Mask
3DGS는 원래 복제나 분할을 통해 큰 그래디언트를 가진 가우시안을 밀집시킵니다.
가우시안 수의 증가를 조절하기 위해 특정 간격마다 불투명도를 소수로 설정하고, 일부 반복 후에는 여전히 불투명도가 최소인 가우시안을 제거합니다.
이 불투명도 기반 제어는 일부 플로터들을 효과적으로 제거하지만, 우리는 경험적으로 중복된 가우시안이 여전히 상당히 존재한다는 것을 발견했습니다 (그림 3에서 유사한 성능을 보였습니다).

각 가우시안의 스케일 속성에 따라 3D 볼륨이 결정되며, 이는 렌더링 과정에 반영됩니다.
작은 크기의 가우시안은 최소한의 볼륨으로 인해 전체 렌더링 품질에 미치는 기여도가 미미하며, 종종 그 효과가 본질적으로 감지되지 않을 정도입니다.
이러한 경우, 이러한 불필요한 가우시안을 식별하고 제거하는 것이 매우 유익해집니다.
이를 위해, 우리는 가우시안의 부피와 투명성을 기반으로 학습 가능한 마스킹을 제안합니다.
우리는 비음수 스케일 속성 s ∈ R_+^(N×3)에 이진 마스크를 적용하여 N 가우시안의 부피 지오메트리를 결정합니다, 여기서 N은 가우시안의 밀도화에 따라 달라질 수 있습니다.
우리는 추가적인 마스크 매개변수 m ∈ R^N을 소개하며, 이를 바탕으로 이진 마스크 M ∈ {0, 1}^N을 생성합니다.
이진화된 마스크로부터 그래디언트를 계산하는 것이 불가능하기 때문에, 우리는 직관적인 추정기 [5]를 사용합니다.
보다 구체적으로, 마스크된 스케일 ˆs ∈ R_+^(N×3)와 마스크된 불투명도 ˆo ∈ [0, 1]^N은 다음과 같이 공식화됩니다,

, 여기서 n은 가우시안 지수, ϵ는 마스킹 임계값, sg(·)는 스탑 그래디언트 연산자, 그리고 1[·]과 σ(·)는 각각 지표 함수와 시그모이드 함수입니다.
이 방법은 가우시안 볼륨과 렌더링의 투명성을 기반으로 마스킹 효과를 통합할 수 있게 해줍니다.
두 가지 측면을 함께 고려하면 두 가지 측면만 고려하는 것보다 더 효과적인 마스킹을 할 수 있습니다.
다음과 같이 마스킹 loss L_m을 추가하여 정확한 렌더링과 학습 중 제거된 가우시안 수를 균형 있게 조정합니다

모든 밀집화에서 우리는 이진 마스크에 따라 가우시안을 제거합니다.
또한, 학습 도중 밀집화를 멈추고 가우시안의 수를 끝까지 유지하는 기존의 3DGS와 달리, 전체 학습 과정을 일관되게 마스킹하여 불필요한 가우시안을 효과적으로 줄이고 학습 단계 전반에 걸쳐 낮은 GPU 메모리로 효율적인 계산을 보장합니다(그림 3).
학습이 완료되면 마스크된 가우시안을 제거했기 때문에 마스크 매개변수 m을 저장할 필요가 없습니다.
3.2. Geometry Codebook
여러 가우시안들이 하나의 장면을 함께 구성하며, 전체 볼륨에서 유사한 지오메트릭 구성 요소를 공유할 수 있습니다.
우리는 대부분의 가우시안의 지오메트릭 형태가 매우 유사하며, 스케일과 회전 특성에서 약간의 차이만 보인다는 것을 관찰했습니다.
또한, 장면은 많은 작은 가우시안들로 구성되어 있으며, 각 가우시안 원시는 넓은 범위의 다양성을 나타내지 않을 것으로 예상됩니다.
이러한 동기를 바탕으로, 우리는 vector quantization (VQ) [14]를 사용하여 스케일과 회전을 포함한 대표적인 지오메트릭 속성을 표현하도록 학습된 코드북을 제안합니다.
벡터 양자화를 나이브하게 적용하려면 계산 복잡성과 대용량 GPU 메모리가 필요하므로, 우리는 코드북 크기 C로 VQ의 L 단계를 계단식으로 변환하는 residual vector quantization (R-VQ) [48]을 채택합니다 (그림 4)

, 여기서 r ∈ R^(N×4)는 입력 회전 벡터이고, ˆr^l ∈ R^(N×4)는 l 단계 후 출력 회전 벡터이며, n은 가우시안 지수입니다.
Z^l ∈ R^(C×4)는 l단계의 코드북이고, i^l ∈ {0, . . ., C - 1}^N은 l단계의 코드북의 선택된 인덱스이며, Z[i] ∈ R^4는 코드북 Z의 인덱스 i에서의 벡터를 나타냅니다.

코드북을 학습하기 위한 objective 함수는 다음

과 같습니다, 여기서 sg[·]는 스탑 그래디언트 연산자입니다.
우리는 최종 단계 ˆr^L의 출력을 사용합니다 (앞으로는 간결성을 위해 위첨자 L을 생략하겠습니다), R-VQ 과정은 마스킹하기 전에 스케일 s에도 유사하게 적용됩니다 (스케일 L_s에 대해서도 objective 함수를 유사하게 사용합니다).
3.3. Compact View-dependent Color
3DGS의 각 가우시안은 뷰 방향에 따라 다양한 색상을 모델링하기 위해 총 59개의 매개변수 중 48개의 매개변수가 SH (최대 3도)를 나타내야 합니다.
나이브하고 매개변수가 비효율적인 접근 방식 대신 그리드 기반 신경망을 활용하여 각 가우시안의 뷰 의존적인 색상을 표현할 것을 제안합니다.
이를 위해, 우리는 mip-NeRF 360 [3]에서 영감을 받아 무한 위치 p ∈ R^(N×3)을 유한 범위로 축소하고, 카메라 중심점을 기준으로 각 가우시안에 대한 3D 뷰 방향 d ∈ R^3을 계산합니다.
hash grids [30]와 작은 MLP를 활용하여 색상을 표현합니다.
여기서 우리는 해시 그리드에 위치를 입력한 다음, 결과적으로 생성된 피쳐와 뷰 방향을 MLP에 입력합니다.
보다 형식적으로, 위치 p_n ∈ R^3에서 가우시안의 뷰 의존 색상 c_n(·)은

로 표현될 수 있으며, 여기서 f(·; θ), contract(·) : R^3 → R^3는 각각 매개변수 θ를 가진 신경 필드와 수축 함수를 나타냅니다.
SH의 0도 구성 요소 (RGB와 동일한 채널 수이지만 뷰 의존적이지 않음)를 사용한 다음 RGB 색상을 직접 표현하는 것에 비해 성능이 약간 향상되어 RGB 색상으로 변환합니다.
3.4. Training
여기에는 이미지 렌더링에 사용되는 N개의 가우시안과 그 속성, 위치 p_n, 불투명도 o_n, 회전 ˆr_n, 스케일 ˆs_n, 뷰 의존 색상 c_n(·)이 있습니다.
전체 모델은 렌더링 loss L_ren, GT와 렌더링된 이미지 간의 L1 및 SSIM loss의 가중 합을 기반으로 종단 간 학습을 수행합니다.
마스킹 L_m과 지오메트리 코드북 L_r, L_s에 대한 loss를 더하여 전체 loss L은 다음과 같습니다

, 여기서 λ_m은 가우시안의 수를 정규화하기 위한 하이퍼파라미터입니다.
과중한 계산을 피하고 빠르고 최적의 학습을 보장하기 위해, 우리는 R-VQ를 적용하고 마지막 1K iterations에 한해 K-means 초기화가 적용된 코드북을 학습합니다.
그 기간을 제외하고, 우리는 L_r, L_s를 0으로 설정합니다.
4. Experiment
4.1. Implementation Details
우리는 세 가지 실제 데이터셋 (Mip-NeRF 360 [3], Tanks&Temple [19], 그리고 Deep Blending [16])과 합성 데이터셋(NeRF-Synthetic [28])을 대상으로 접근 방식을 테스트했습니다.
3DGS에 이어, Tanks&Temple과 Deep Blending의 두 장면을 선택했습니다.
제안된 방법 (Ours로 표시됨)을 사용한 모델들은 30K iterations 동안 학습되었으며, 하프텐서를 사용하여 위치 p와 불투명도 o를 16비트 precision으로 저장했습니다.
또한, 우리는 모델 속성에 대해 간단한 후처리 기법을 구현했으며, 이 변형을 Ours+PP라고 부릅니다.
이러한 후처리 단계에는 다음이 포함됩니다:
• 불투명도 및 해시 그리드 매개변수에 8비트 min-max 양자화 적용.
• 값이 0.1 미만인 해시 그리드 매개변수 프루닝.
• 양자화된 불투명도 및 해시 매개변수와 R-VQ 인덱스에 Huffman encoding [17]을 적용합니다.
추가 구현 세부 사항은 보충 자료에 제공됩니다.

4.2. Performance Evaluation
Real-world scenes.
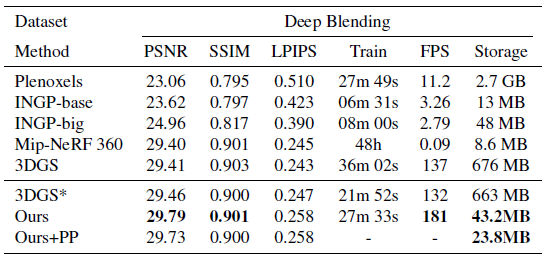
표 1과 표 2는 실제 장면에서 평가된 정성적 결과를 보여줍니다.
우리의 접근 방식은 저장 요구 사항을 지속적으로 크게 줄이고 렌더링 속도를 향상시키면서 3DGS에 필적하는 정확한 재구성을 수행합니다.
특히 Deep Blending 데이터셋 (표 2)의 경우, 우리의 방법은 시각적 품질 (PSNR 및 SSIM으로 측정) 측면에서 기존 3DGS를 능가하여 가장 빠른 렌더링 속도와 컴팩트함 (3DGS에 비해 거의 40% 더 빠른 렌더링 속도와 15배 이상의 컴팩트함)으로 SOTA 성능을 달성했습니다.
그림 5의 정성적 결과는 또한 3DGS에 비해 저장 공간을 크게 줄인 고품질 재구성을 보여줍니다.

Synthetic scenes.
우리는 또한 합성 장면에서 우리의 방법을 평가합니다.
3DGS는 시각적 품질, 렌더링 속도 및 학습 시간 면에서 다른 베이스라인에 비해 효과적임을 입증했기 때문에, 우리의 방법과 3DGS를 비교하는 데 중점을 두고 우리의 방법이 개선된 점을 강조합니다.
표 3에서 볼 수 있듯이, 우리의 접근 방식은 약간 더 많은 학습 시간이 필요하지만, 3DGS에 비해 10배 이상의 압축과 50% 더 빠른 렌더링을 달성하여 고품질의 재구성을 유지합니다.

With post-processings, 우리의 모델은 데이터셋에 관계없이 40% 이상 축소되었습니다.
그 결과, 높은 성능을 유지하면서 3DGS에서 25배 이상의 압축을 달성했습니다.

4.3. Ablation Study
Learnable volume masking.
표 4에 나타난 바와 같이, 제안된 볼륨 기반 마스킹은 시각적 품질을 유지하면서도 가우시안의 수를 크게 줄이며 (심지어 약간 증가시키는) 불필요한 가우시안을 효과적으로 제거함을 보여줍니다.
축소된 가우시안은 몇 가지 추가적인 장점을 보여줍니다: 학습 시간, 저장 및 테스트 시간을 줄입니다.
특히 Playroom 장면에서 볼륨 마스크는 저장 효율성이 140% 증가하고 렌더링 속도가 65% 증가하는 것으로 나타났습니다.
또한, 그림 6에서 가우시안을 시각화하여 렌더링의 실제 영향을 검증했습니다.
시각화에서 희소한 포인트들로 인해 가우시안의 수가 눈에 띄게 줄어들었지만, 렌더링된 결과는 가시적인 차이 없이 높은 품질을 유지합니다.
이러한 결과는 제안된 방법의 효과와 효율성을 정량적 및 정성적으로 입증합니다.

Compact view-dependent color.
신경망을 기반으로 한 제안된 색상 표현은 학습 및 렌더링에 약간 더 많은 시간이 필요함에도 불구하고 직접 저장하는 고차 SH에 비해 가우시안 수가 약간 줄어들어 저장 효율성이 3배 이상 향상되었습니다.
그럼에도 불구하고, 마스킹 전략을 사용한 제안된 색상 표현은 3DGS와 비교했을 때 더 빠르거나 비슷한 렌더링 속도를 보여줍니다.

Geometry codebook.
우리가 제안한 지오메트리 코드북 접근 방식은 재구성 품질, 학습 시간 및 렌더링 속도를 유지하면서 저장 요구 사항을 약 30% 줄였습니다.
이러한 성능 향상의 이유를 더 깊이 탐구하기 위해, 먼저 그림 7-(a)에 나타난 것처럼 가우시안을 시각화하는 것으로 시작합니다.
대부분의 가우시안은 R-VQ의 적용 여부에 관계없이 시각화에서 동일한 지오메트리를 유지하며, 소수의 가우시안만이 거의 눈에 띄지 않는 매우 미묘한 지오메트리 왜곡을 보이는 것으로 관찰되었습니다.
이러한 결과는 우리 방법의 효과를 입증하지만, 그림 7-(b)에 나타난 바와 같이 R-VQ의 각 단계에서 학습된 지표의 패턴도 탐구합니다.
초기 단계는 큰 크기의 코드와 함께 짝수 분포를 보입니다.
단계가 진행됨에 따라 코드의 크기가 감소하여 각 단계의 잔차가 지오메트리를 나타내도록 효과적으로 학습되었음을 나타냅니다.

Effect of post-processing.
표 5는 후처리 기법을 적용한 경우와 적용하지 않은 경우의 각 속성 크기를 설명합니다.
종단 간 학습 가능한 프레임워크는 상당한 효과를 보여주지만 색상 표현을 위해 상대적으로 큰 저장 공간이 필요합니다.
그럼에도 불구하고 표에 나와 있듯이 간단한 후처리를 통해 이를 효과적으로 줄일 수 있습니다.
5. Conclusion
우리는 3D 장면을 위한 컴팩트한 3D 가우시안 표현을 제안했으며, 새로운 볼륨 기반 마스킹을 통해 성능 저하 없이 가우시안 포인트의 수를 줄였습니다.
또한, 이 연구는 신경망을 결합하고 학습 가능한 코드북을 활용하여 가우시안 속성을 컴팩트하게 표현할 것을 제안했습니다.
광범위한 실험에서 우리의 접근 방식은 3DGS에 비해 고품질 재구성을 유지하면서 저장 공간을 10배 이상 줄이고 렌더링 속도를 현저히 향상시키는 것을 입증했습니다.
이 결과는 고성능, 빠른 학습, 컴팩트함, 실시간 렌더링을 갖춘 새로운 벤치마크를 설정합니다.
따라서 우리의 프레임워크는 효율적이고 고품질의 3D 장면 표현을 요구하는 다양한 분야에서 더 넓은 채택과 적용의 길을 열어주는 종합적인 솔루션으로 자리매김하고 있습니다.
'3D Vision' 카테고리의 다른 글
| LRM: Large Reconstruction Model for Single Image to 3D (0) | 2024.05.29 |
|---|---|
| Segment Anything in 3D with NeRFs (0) | 2024.05.16 |
| 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (0) | 2024.05.13 |
| GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images (0) | 2023.02.01 |
| Pyramid Stereo Matching Network (0) | 2022.03.25 |