2024. 5. 29. 11:32ㆍ3D Vision
LRM: Large Reconstruction Model for Single Image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, Hao Tan
Abstract
저희는 단일 입력 이미지에서 객체의 3D 모델을 단 5초 이내에 예측하는 최초의 Large Reconstruction Model (LRM)을 제안합니다.
카테고리별 방식으로 ShapeNet과 같은 소규모 데이터 세트에서 학습하는 이전의 많은 방법과 달리, LRM은 5억 개의 학습 가능한 매개 변수가 있는 확장성이 높은 트랜스포머 기반 아키텍처를 채택하여 입력 이미지에서 neural radiance fields (NeRF)를 직접 예측합니다.
저희는 Objaverse의 합성 렌더링과 MVImgNet의 실제 캡처를 모두 포함하여 약 100만 개의 객체가 포함된 대규모 멀티뷰 데이터에 대해 종단간 방식으로 모델을 학습합니다.
이러한 대용량 모델과 대규모 학습 데이터의 조합을 통해 모델은 매우 일반화 가능하고 생성 모델에 의해 생성된 실제 야생 캡처 및 이미지를 포함한 다양한 테스트 입력에서 고품질의 3D 재구성을 생성할 수 있습니다.
1 Introduction
임의의 물체의 단일 이미지에서 3D 모양을 즉시 만들 수 있다고 상상해 보세요.
산업 디자인, 애니메이션, 게임 및 AR/VR의 광범위한 응용 분야에서 이 오랜 목표를 향한 일반적이고 효율적인 접근 방식을 모색하는 데 있어 관련 연구에 강력한 동기를 부여했습니다.
단일 뷰에서 3D 지오메트리의 근본적인 모호성으로 인해 초기 학습 기반 방법은 일반적으로 전체 모양을 추론하기 전에 범주 데이터를 활용하여 특정 범주에서 잘 수행됩니다 (Yu et al., 2021).
최근에는 DALL-E (Ramesh et al., 2021) 및 Stable Diffusion (Rombach et al., 2022)과 같은 이미지 생성의 발전으로 인해 2D 디퓨전 모델의 놀라운 일반화 기능을 활용하여 멀티뷰 supervision을 가능하게 하는 연구가 시작되었습니다 (Liu et al., 2023b; Tang et al., 2023).
그러나 이러한 방법 중 많은 부분은 섬세한 매개 변수 조정 및 정규화가 필요하며, 그 결과는 사전 학습된 2D 생성 모델에 의해 제한됩니다.
한편 일관된 지오메트리를 구성하기 위해 형상별 최적화(예: NeRF (Mildenhall et al., 2021; Chan et al., 2022; Chen et al., 2022a; M¨uller et al., 2022; Sun et al., 2022) 최적화)에 의존하는 많은 접근 방식이 있으며, 이 프로세스는 종종 느리고 비현실적입니다.
반면에 자연어 처리 (Devlin et al., 2018; Brown et al., 2020; Chowdhery et al., 2022) 및 이미지 처리 (Caron et al., 2021; Radford et al., 2021; Alayrac et al., 2022; Ramesh et al., 2022) 분야에서 큰 성공을 거둔 것은 크게 세 가지 중요한 요인에 기인합니다: (1) 트랜스포머 (Vaswani et al., 2017)와 같이 확장성이 높고 효과적인 신경망을 사용하여 데이터 분포를 모델링하고, (2) 일반 학습 priors을 위한 거대한 데이터 세트와 (3) 모델이 높은 확장성을 유지하면서 기본 데이터 구조를 발견하도록 장려하는 self-supervised-like 학습 objective를 사용합니다.
예를 들어, GPT (generative pre-trained transformer) 시리즈 (Radford et al., 2019; Brown et al., 2020; OpenAI, 2023)는 거대한 트랜스포머 네트워크, 대규모 데이터 및 간단한 다음 단어 예측 작업을 통해 대규모 언어 모델을 구축합니다.
이를 고려하여 3D에도 동일한 질문을 제기합니다: 충분한 3D 데이터와 대규모 학습 프레임워크가 주어지면 단일 이미지에서 객체를 재구성하기 위한 일반적인 3D prior 학습이 가능합니까?
이 논문에서는 단일 image-to-3D로의 Large Reconstruction Model (LRM)을 제안합니다.
저희의 방법은 데이터 기반 방식으로 단일 이미지에서 객체의 3D 표현을 학습하기 위해 대규모 트랜스포머 기반 인코더-디코더 아키텍처를 채택합니다.
저희의 방법은 이미지를 입력으로 받아 triplane (Chan et al., 2022) 표현의 형태로 NeRF를 회귀합니다.
특히, LRM은 사전 학습된 시각적 트랜스포머 DINO (Caron et al., 2021)를 이미지 인코더로 활용하여 이미지 피쳐를 생성하고 image-to-triplane 트랜스포머 디코더를 학습하여 크로스 어텐션을 통해 2D 이미지 피쳐를 3D triplane에 투영하고 셀프 어텐션을 통해 공간적으로 구조된 triplane 토큰 간의 관계를 모델링합니다.
디코더의 출력 토큰은 최종 triplane 피쳐 맵으로 재구성되고 업샘플링됩니다.
그 후 각 지점의 triplane 피쳐를 추가적인 공유 multi-layer perceptron (MLP)으로 디코딩하여 색상과 밀도를 얻고 볼륨 렌더링을 수행하여 임의의 뷰로 이미지를 렌더링할 수 있습니다.
LRM의 전반적인 설계는 높은 확장성과 효율성을 유지합니다.
완전한 트랜스포머 기반 파이프라인을 사용하는 것 외에도 triplane NeRF는 볼륨 및 포인트 클라우드와 같은 다른 표현에 비해 계산 친화적이기 때문에 간결하고 확장 가능한 3D 표현입니다.
또한 Shap-E (Jun & Nichol, 2023)에서와 같이 NeRF의 모델 가중치를 토큰화하는 것에 비해 이미지 입력과 관련하여 더 나은 로컬리티를 가지고 있습니다.
또한 LRM은 과도한 3D-aware 정규화 또는 섬세한 하이퍼파라미터 튜닝 없이 새로운 뷰에서 렌더링된 이미지와 ground truth 이미지 간의 차이를 간단히 최소화하여 학습하므로 모델이 학습에 매우 효율적이고 광범위한 멀티뷰 이미지 데이터 세트에 적응할 수 있습니다.
2 Related Work
Single Image to 3D Reconstruction
포인트 클라우드 (Fan et al., 2017; Wu et al., 2020), 복셀 (Choy et al., 2016; Tulsiani et al., 2017; Chen & Zhang, 2019), 메시 (Wang et al., 2018; Gkioxari et al., 2019)를 탐색하는 초기 학습 기반 방법과 SDF (Park et al., 2019; Mittal et al., 2022), 점유 네트워크 (Mescheder et al., 2019), NeRF (Jang & Agapito, 2021;M¨uller et al., 2022)와 같은 암시적 표현을 학습하는 다양한 접근 방식을 포함하여 이 문제를 해결하기 위해 광범위한 노력을 기울였습니다.
3D 템플릿 (Roth et al., 2016; Goel et al., 2020; Kanazawa et al., 2018; Kulkarni et al., 2020), 시맨틱 (Li et al., 2020) 및 포즈 (Bogo et al., 2016; Novotny et al., 2019)를 형상 prior로 활용하는 것도 범주별 재구성에서 널리 연구되었습니다.
범주에 구애받지 않는 방법은 큰 일반화 가능성 (Yan et al., 2016; Niemeyer et al., 2020)을 보여주지만 공간적으로 정렬된 로컬 이미지 피쳐 (Xu et al., 2019; Yu et al., 2021)를 활용하는 경우에도 세분화된 세부 정보를 생성할 수 없는 경우가 많습니다.
매우 최근에는 사전 학습된 이미지/언어 모델 (Radford et al., 2021; Li et al., 2022; 2023b; Saharia et al., 2022; Rombach et al., 2022)을 사용하여 image-to-3D 재구성 (Liu et al., 2023b; Tang et al., 2023; Deng et al., 2023; Shen et al., 2023b; Anciukeviˇcius et al., 2023; Melas-Kyriazi et al., 2023; Metzer et al., 2023; Xu et al., 2023; Qian et al., 2023; Li et al., 2023a)을 위한 시맨틱 및 멀티뷰 가이던스를 도입하는 추세가 부상하고 있습니다.
예를 들어, Zero-1-to-3은 Stable Diffusion 모델을 파인튜닝하여 입력 이미지와 카메라 포즈 (Liu et al., 2023b)를 조정하여 새로운 뷰를 생성합니다; Liu et al. (2023a)은 뷰 일관성과 재구성 효율성을 더욱 향상시켰습니다.
Make-It-3D (Tang et al., 2023)는 BLIP를 사용하여 입력 이미지에 대한 텍스트 설명을 생성하고(text-to-image 디퓨전을 가이드하는 데 적용됨) score distillation sampling loss (Poole et al., 2022)와 CLIP 이미지 loss로 모델을 학습하여 지오메트릭적이고 의미론적으로 그럴듯한 모양을 만듭니다.
이 모든 방법과 달리, 우리의 LRM은 야생에서 임의의 객체를 재구성하는 방법을 배우는 순수 데이터 기반 접근 방식입니다.
최소한의 확장 가능한 3D supervision (즉, 3D 객체의 2D 이미지를 렌더링하거나 캡처)으로 학습되었으며, 사전 학습된 비전-언어 대조 또는 생성 모델의 어떤 가이던스에도 의존하지 않습니다.
Learning 3D Representations from Images
단일 이미지에서 3D 재구성은 생성 속성을 가진 모델에서 자주 다루어지는 ill-posed 문제입니다.
이전의 많은 작업은 인코더-디코더 프레임워크를 적용하여 image-to-3D 데이터 분포 (Choy et al., 2016; Yan et al., 2016; Dai et al., 2017; Xu et al., 2019; Wu et al., 2020; M¨uller et al., 2022; Sajjadi et al., 2022; Goel et al., 2023)를 모델링하며, 여기서 컴팩트한 잠재 코드는 타겟의 텍스처, 지오메트리 및 포즈 세부 정보를 전달하도록 학습됩니다.
그러나 이러한 표현 표현 표현을 학습하려면 일반적으로 능력 있는 네트워크와 풍부한 3D 데이터가 필요하며, 이는 획득하는 데 매우 비용이 많이 듭니다.
따라서 이러한 방법의 대부분은 몇 가지 범주에만 초점을 맞추고 매우 coarse 결과를 생성합니다.
GINA-3D (Shen et al., 2023a)는 시각적 트랜스포머 인코더 및 크로스 어텐션 (LRM에서와 같은 트랜스포머 디코더 대신)을 적용하여 이미지를 triplane 표현으로 변환하는 모델을 구현합니다.
그러나 모델과 학습은 규모가 훨씬 작고, 범주별 생성에 대한 작업의 초점이 다릅니다.
최근의 데이터 기반 접근 방식인 MCC (Wu et al., 2023)는 입력 이미지와 투영되지 않은 포인트 클라우드의 점유율과 색상을 예측하기 위해 CO3D-v2 데이터 (Reizenstein et al., 2021)로 일반화 가능한 트랜스포머 기반 디코더를 학습시킵니다.
MCC는 실제 이미지와 생성된 장면을 처리할 수 있지만, 결과는 일반적으로 지나치게 매끄럽고 세부 정보를 잃습니다.
Multimodal 3D
2D 멀티모달 학습 (Tan & Bansal, 2019; Chen et al., 2020; 2022b; Yu et al., 2022; Singh et al., 2022; Wang et al., 2022; Alayrac et al., 2022; Girdhar et al., 2023)의 큰 발전에 힘입어 LRM은 3D를 새로운 양식으로 간주하고 크로스 어텐션을 통해 2D 피쳐 맵을 3D triplane에 직접 접지합니다.
이 방향에는 인코딩된 이미지와 3D 표현 (Girdhar et al., 2016; Mandikal et al., 2018)의 차이를 최소화하는 초기 시도와 대조 학습을 통해 3D, 언어 및 이미지를 연결하는 최근 연구인 ULIP (Xue et al., 2023) 및 CLIP^2 (Zeng et al., 2023)가 있습니다.
LERF (Kerr et al., 2023)는 학습 ray를 따라 CLIP 임베딩을 렌더링하여 NeRF 내부의 언어 필드를 학습합니다.
이와는 대조적으로, 저희의 방법은 일반적인 단일 image-to-3D 재구성에 중점을 둡니다.
저희는 BLIP (Li et al., 2023b)를 적용하여 다양한 뷰의 캡션을 생성하고 GPT-4 (OpenAI, 2023)를 사용하여 요약한 다음 이러한 언어-3D 쌍을 사용하여 text-to-3D 생성 모델 (Nichol et al., 2022; Poole et al., 2022; Jun & Nichol, 2023)을 학습하는 동시 작업 Cap3D (Luo et al., 2023)에 대해 언급하고자 합니다.
3D-LLM (Hong et al., 2023) 및 LLM-Grounder (Yang et al., 2023)와 같은 3D와 대규모 언어 모델을 연결하는 최근 작업도 있습니다.
3 Method
이 섹션에서는 제안된 LRM 아키텍처를 자세히 설명합니다(그림 1).
LRM에는 패치별 피쳐 토큰에 입력 이미지를 인코딩하는 이미지 인코더가 포함되어 있으며 (섹션 3.1), 크로스 어텐션을 통해 이미지 피쳐를 triplane 토큰에 투영하는 image-to-triplane 디코더가 포함되어 있습니다 (섹션 3.2).
출력된 triplane 토큰은 업샘플링되어 최종 triplane 표현으로 재구성되며, 이는 3D 포인트 피쳐를 쿼리하는 데 사용됩니다.
마지막으로, 3D 포인트 피쳐는 multi-layer perceptron으로 전달되어 볼륨 렌더링을 위한 RGB와 밀도를 예측합니다 (섹 3.3).
학습 objective와 데이터는 섹션 3.4와 섹션 4.1에 설명되어 있습니다.
3.1 Image Encoder
RGB 이미지가 입력으로 주어지면 LRM은 먼저 사전 학습된 visual transformer (ViT) (Dosovitskiy et al., 2020)를 적용하여 이미지를 패치별 피쳐 토큰 {h_i}_(i=1)^n ∈ R^(d_E)에 인코딩합니다, 여기서 i는 i번째 이미지 패치, n은 총 패치 수, d_E는 인코더의 잠재 차원입니다.
특히, 이미지에서 두드러진 콘텐츠의 구조와 텍스처에 대해 해석 가능한 어텐션을 학습하는 self-distillation으로 학습된 모델인 DINO (Caron et al., 2021)를 사용합니다.
ImageNet이 사전 학습한 ResNet (He et al., 2016) 또는 CLIP (Radford et al., 2021)의 시각적 피쳐와 같은 다른 시맨틱-지향 표현에 비해, DINO의 자세한 구조 및 텍스처 정보는 LRM이 3D 공간에서 지오메트리와 색상을 재구성하는 데 사용할 수 있기 때문에 우리의 경우 더 중요합니다.
따라서 패치별 피쳐를 집계하는 ViT 사전 정의 클래스 토큰 [CLS]만 사용하는 대신 전체 피쳐 시퀀스 {h_i}_(i=1)^n도 활용하여 이 정보를 더 잘 보존합니다.
3.2 Image-to-Triplane Decoder
저희는 트랜스포머 디코더를 구현하여 이미지 및 카메라 피쳐를 학습 가능한 공간 위치 임베딩에 투영하고 이를 triplane 표현으로 변환합니다.
이 디코더는 단일 이미지 재구성의 모호성을 보완하기 위해 필요한 지오메트릭 및 외관 정보를 제공하기 위해 대규모 데이터로 학습된 prior 네트워크로 간주될 수 있습니다.
Camera Features
저희는 4x4 카메라 extrinsic 행렬 E(camera-to-world 변환을 나타냄)를 평탄화하여 입력 이미지의 카메라 피쳐 c ∈ R^20을 구성하고 카메라 초점 거리 foc 및 주점 pp와 c = [E_(1x16), foc_x, foc_y, pp_x, pp_y]로 연결합니다.
또한 모든 입력 카메라가 동일한 축에 정렬되도록 유사성 변환을 통해 카메라 extrinsic E를 정규화합니다(룩업 방향이 z축에 정렬됨).
LRM은 객체의 canonical 포즈에 의존하지 않으며 ground truth c는 학습에만 적용됩니다.
정규화된 카메라 매개 변수에 대한 조건화는 triplane 피쳐의 최적화 공간을 크게 줄이고 모델 수렴을 용이하게 합니다(섹션 4.2의 자세한 내용 참조).
카메라 피쳐를 임베드하기 위해 multi-layer perceptron (MLP)을 구현하여 카메라 피쳐를 고차원 카메라 임베딩 ˜c에 매핑합니다.
Intrinsics (focal 및 주점)은 MLP 레이어로 전송하기 전에 이미지의 높이와 너비에 의해 정규화됩니다.
Triplane Representation
저희는 이전 작업 (Chan et al., 2022; Gao et al., 2022)을 따라 재구성 주체의 간결하고 표현적인 피쳐 표현으로 triplane을 적용했습니다.
triplane T에는 세 개의 축 정렬 피쳐 평면 T_XY, T_YZ 및 T_XZ가 포함되어 있습니다.
구현에서 각 평면은 차원 (64x64) x d_T이며, 여기서 64x64는 공간 해상도이고, d_T는 피쳐 채널의 수입니다.
NeRF 객체 바운딩 박스 [-1, 1]^3의 모든 3D 포인트에 대해 각 평면에 투영하고 쌍선형 보간을 통해 해당 포인트 피쳐 (T_xy, T_yz, T_xz)를 쿼리한 다음 MLP^nerf를 통해 NeRF 색상 및 밀도로 디코딩할 수 있습니다 (섹션 3.3).
triplane 표현 T를 얻기 위해 image-to-3D 투영을 가이드하고 크로스 어텐션을 통해 이미지 피쳐를 쿼리하는 데 사용되는 학습 가능한 공간 위치 임베딩 f^init 차원(3x32x32) x d_D를 정의합니다, 여기서 d_D는 트랜스포머 디코더의 숨겨진 차원입니다.
f^init의 토큰 수는 최종 triplane 토큰 수(3x64x64)보다 작습니다; 트랜스포머 f^out의 출력을 최종 T로 업샘플링합니다.
포워드 패스에서 카메라의 컨디셔닝은 ˜c 및 이미지 피쳐 {h_i}_(i=1)^n을 포함하며, image-to-triplane 트랜스포머 디코더의 각 레이어는 초기 위치 임베딩 f^init를 각각 변조 및 크로스 어텐션을 통해 최종 triplane 피쳐로 점진적으로 업데이트합니다.
두 가지 다른 조건부 연산을 적용하는 이유는 카메라가 전체 모양의 방향과 왜곡을 제어하는 반면 이미지 피쳐는 triplane에 임베딩해야 하는 세분화된 지오메트릭 및 색상 정보를 전달하기 때문입니다.
두 연산에 대한 자세한 내용은 아래에서 설명합니다.
Modulation with Camera Features
우리의 카메라 변조는 디노이징 타임스텝과 클래스 레이블로 이미지 잠재력을 변조하기 위해 adaptive layer norm (adaLN)을 구현하는 DiT (Peebles & Xie, 2022)에서 영감을 얻었습니다.
{f_j}가 트랜스포머의 벡터 시퀀스라고 가정하고 카메라 피쳐 c를

로 사용하여 변조 함수 ModLN_c(f_j)를 정의하며, 여기서 γ와 β는 MLP^mod에 의한 스케일 및 시프트 (Huang & Belongie, 2017) 출력이고 LN은 Layer Normalization (Ba et al., 2016)입니다.
이러한 변조는 다음에 지정될 각 어텐션 하위 레이어에 적용됩니다.

Transformer Layers
각 트랜스포머 레이어에는 크로스 어텐션 하위 레이어, 셀프 어텐션 하위 레이어 및 multi-layer perceptron 하위 레이어 (MLP)이 포함되어 있으며, 여기서 각 하위 레이어에 대한 입력 토큰은 카메라 피쳐에 의해 변조됩니다.
피쳐 시퀀스 f^in이 트랜스포머 레이어의 입력이라고 가정하면, f^in은 최종 triplane 피쳐 T에 해당하기 때문에 triplane 히든 피쳐로 간주할 수 있습니다.
그림 1의 디코더 부분에서 볼 수 있듯이 크로스 어텐션 모듈은 먼저 triplane 히든 피쳐 f^in에서 이미지 피쳐 {h_i}_(i=1)^n으로 이동하여 이미지 정보를 triplane에 연결하는 데 도움이 될 수 있습니다.
여기서는 2D 이미지와 3D triplane 히든 피쳐 사이의 공간 정렬을 명시적으로 정의하지 않고 3D를 독립적인 양식으로 간주하고 모델이 스스로 2D-to-3D 대응을 학습하도록 요청합니다.
업데이트된 triplane 히든 피쳐는 공간적으로 구조화된 triplane 항목에 걸쳐 모달 내 관계를 추가로 모델링하는 셀프 어텐션 하위 레이어로 전달됩니다.
그런 다음 원래 트랜스포머 (Vaswani et al., 2017) 설계에서와 같이 multi-layer perceptron 하위 계층(MLP^tfm)이 다음과 같습니다.
마지막으로 출력된 triplane 피쳐 f^out이 다음 트랜스포머 레이어의 입력이 됩니다.
이러한 설계는 Perceiver network (Jaegle et al., 2021)와 유사하지만, 저희 모델은 잠재 병목 현상에 입력을 투영하는 대신 어텐션 레이어에 걸쳐 고차원 표현을 유지합니다.
전반적으로 각 레이어의 각 j번째 triplane 항목에 대한 이 프로세스를
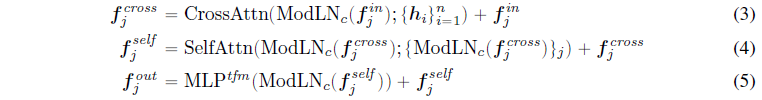
으로 표현할 수 있습니다.
하위 레이어 (즉, CrossAttn, SelfAttn, MLP^tfm)의 ModLN 연산자는 레이어 정규화 및 변조 MLP^mod에서 학습 가능한 매개 변수 세트를 사용합니다.
명확성을 위해 위첨자를 추가하지 않습니다.
트랜스포머 레이어는 순차적으로 처리됩니다.
모든 트랜스포머 레이어가 끝나면 마지막 레이어에서 출력 triplane 피쳐 f^out을 디코더의 출력으로 얻습니다.
이 최종 출력은 학습 가능한 디콘볼루션 레이어에 의해 업샘플링되고 최종 triplane 표현 T로 재구성됩니다.
3.3 Triplane-NeRF
저희는 triplane-NeRF 공식 (Chan et al., 2022)을 사용하고 MLP^nerf를 구현하여 triplane 표현 T에서 쿼리한 점 피쳐에서 RGB 및 밀도 σ을 예측합니다.
MLP^nerf에는 ReLU 활성화 (Nair & Hinton, 2010)가 있는 여러 선형 레이어가 포함되어 있습니다.
MLP^nerf의 출력 차원은 4이며, 여기서 처음 세 차원은 RGB 색상이고 마지막 차원은 필드의 밀도에 해당합니다.
NeRF 볼륨 렌더링에 대한 자세한 내용은 부록을 참조합니다.
3.4 Training Objectives
LRM은 단일 입력 이미지에서 3D 모양을 생성하고 추가 측면 뷰를 활용하여 학습 중 재구성을 가이드합니다.
학습 데이터의 각 모양에 대해 supervision을 위해 랜덤으로 선택된 (V-1) 측면 뷰를 고려합니다; V 렌더링 뷰 ˆx와 ground truth 뷰 x^GT(입력 뷰 및 측면 뷰 포함) 사이에 간단한 이미지 재구성 objectives를 적용합니다.
더 정확하게는 모든 입력 이미지 x에 대해

을 최소화하며, 여기서 L_MSE는 정규화된 픽셀 단위의 L2 loss, L_LPIPS는 the perceptual image patch similarity (Zhang et al., 2018), λ는 맞춤형 가중치 계수입니다.
4 Experiments
4.1 Data
LRM은 각각 합성 3D 자산과 실제 객체의 비디오로 구성된 Objaverse (Deitke et al., 2023) 및 MVImgNet (Yu et al., 2023)의 풍부한 3D 데이터에 의존하여 일반화 가능한 교차 모양 3D prior 학습을 수행합니다.
Objaverse의 각 3D 자산에 대해 월드 스페이스에서 모양을 [-1, 1]^3 상자로 정규화하고 동일한 카메라가 임의의 포즈로 모양을 가리키는 32개의 랜덤 뷰를 렌더링합니다.
렌더링된 이미지의 해상도는 1024x1024이며 카메라 포즈는 반지름 [1.5, 3.0]이고 높이는 [-0.75, 1.60] 범위의 공에서 샘플링됩니다.
각 비디오에 대해 데이터 세트에서 추출된 프레임을 활용합니다.
해당 프레임의 타겟 모양은 랜덤 위치에 있을 수 있기 때문에 객체가 결과 프레임의 중심에 있도록 예측된 객체 마스크를 사용하여 모든 프레임을 잘라내고 크기를 조정합니다.
따라서 저희의 방법은 배경을 모델링하지 않으므로 순수한 흰색 배경으로 Objaverse의 이미지를 렌더링하고 기성 패키지를 사용하여 비디오 프레임의 배경을 제거합니다.
총 730,648개의 3D 자산과 220,219개의 비디오를 사전 처리했습니다.
임의 이미지에 대한 LRM의 성능을 평가하기 위해 Objaverse (Deitke et al., 2023), MvImgNet (Yu et al., 2023), ImageNet (Deng et al., 2009), Google Scaned Objects (Downs et al., 2022), Amazon Berkeley Objects (Collins et al., 2022)에서 새로운 이미지를 수집하고 실제 이미지를 캡처한 후 Adobe Firefly로 이미지를 생성하여 재구성했습니다.
저희는 섹션 2.3.1과 부록에 그 결과를 시각화했습니다.
접근 방식의 설계 선택을 수치적으로 연구하기 위해 Objaverse에서 보이지 않는 3D 모양 50개와 MvImgNet 데이터 세트에서 보이지 않는 비디오 50개를 각각 랜덤으로 획득했습니다.
각 모양에 대해 15개의 참조 뷰를 전처리하고 그 중 5개를 모델에 하나씩 전달하여 동일한 객체를 재구성하고 15개의 참조 뷰를 모두 사용하여 렌더링된 이미지를 평가합니다(부록의 분석 참조).
4.2 Implementation Details
Camera Normalization
저희는 image-to-triplane 모델링을 용이하게 하기 위해 입력 이미지에 해당하는 카메라 포즈를 정규화합니다.
구체적으로, Objaverse의 합성 3D 자산에서 렌더링된 이미지의 경우 카메라의 해당 위치에 관계없이 입력 카메라 포즈를 월드 프레임의 위쪽 z축과 정렬된 카메라 수직 축으로 [0,-2, 0] 위치로 정규화합니다.
비디오 데이터의 경우 카메라가 타겟에서 임의의 거리에 있을 수 있고 객체가 이미지 중심에 있지 않기 때문에 카메라 포즈를 [0,-dis, 0]으로만 정규화합니다, 여기서 dis는 월드 원점과 카메라 원점 사이의 원래 거리입니다.
Network Architecture
저희는 사전 학습된 DINO의 ViT-B/16 모델을 이미지 인코더로 적용하여 512x512개의 RGB 이미지를 입력으로 받아 1025개의 피쳐 토큰(1024개의 패치별 피쳐와 768(d_E)의 하나의 [CLS] 피쳐)을 생성합니다 (Caron et al., 2021).
image-to-triplane 디코더와 MLP^nerf는 각각 히든 차원 1024(d^D)와 64를 가진 16개와 10개의 레이어입니다.
triplane 차원은 80(d^T)입니다.
신경 렌더링을 위해 LRM은 각 ray에 대해 128개의 포인트를 균일하게 샘플링하고 supervision을 위해 128x128 해상도 이미지를 렌더링합니다.
또한 GPU 메모리를 절약하기 위해 ARF (Zhang et al., 2022)에 도입된 지연 역전파를 사용합니다.
Training
저희는 배치 크기가 1024(반복마다 1024개의 모양)인 128개의 NVIDIA (40G) A100 GPU에서 LRM을 30개의 에포크 동안 학습하여 완료하는 데 약 3일이 걸립니다.
각 에포크에는 합성 데이터와 실제 데이터의 양의 균형을 맞추기 위해 Objaverse의 렌더링된 이미지 데이터 사본 1개와 MvImgNet의 비디오 프레임 데이터 사본 3개가 포함되어 있습니다.
각 샘플에 대해 랜덤으로 선택된 3개의 측면 뷰(즉, 총 뷰 V=4)를 사용하여 모양 재구성을 supervise하고 L_LPIPS의 경우 계수 λ =2.0을 설정합니다.
저희는 AdamW 옵티마이저 (Loshchilov & Hutter, 2017)를 적용하고 코사인 스케줄 (Loshchilov & Hutter, 2016)과 함께 학습률을 4x10^-4로 설정합니다.
저희는 부록에서 데이터, 학습 및 모델 하이퍼 파라미터의 영향을 수치적으로 분석합니다.
Inference
추론하는 동안 LRM은 임의의 이미지를 입력(제곱 및 배경 제거)으로 간주하고 알 수 없는 카메라 매개 변수를 Objaverse 데이터를 학습하기 위해 적용한 정규화된 카메라로 가정합니다.
저희는 재구성된 triplane-NeRF에서 384x384 포인트의 해상도를 쿼리하고 Marching Cubes (Lorensen & Cline, 1998)를 사용하여 메시를 추출합니다.
이 전체 프로세스는 단일 NVIDIA A100 GPU에서 완료하는 데 5초 미만밖에 걸리지 않습니다.


4.3 Results
우리는 다양한 데이터 세트의 실제, 생성 및 렌더링 이미지에서 재구성된 새로운 뷰의 모양을 시각화하고(그림 2), 우리의 방법을 동시 작업과 비교하고 (Liu et al., 2023a)(그림 3), 우리 방법의 몇 가지 실패 사례를 요약합니다(섹션 4.3.2).
다른 방법과의 수치 비교 및 데이터, 모델 아키텍처 및 supervision 분석은 부록에서 확인할 수 있습니다.
4.3.1 Visualization
그림 2는 단일 이미지에서 재구성된 모양의 몇 가지 예를 시각화한 것입니다.
전반적으로, 결과는 뚜렷한 텍스처를 가진 다양한 피사체의 실제, 생성 및 렌더링 이미지를 포함하여 다양한 입력에 대해 매우 높은 충실도를 보여줍니다.
복잡한 지오메트리가 올바르게 모델링되었을 뿐만 아니라(예: 꽃, 깃대, 닦기) 나무 피새의 질감과 같은 고주파 세부 사항도 보존되어 모델의 뛰어난 일반화 능력을 반영합니다.
비대칭 예인 기린, 펭귄 및 곰에서 LRM이 의미론적으로 합리적인 모양의 폐색 부분을 추론할 수 있음을 알 수 있으며, 이는 효과적인 교차 모양 priors 학습이 이루어졌음을 의미합니다.
그림 3에서는 LRM과 2D 디퓨전 모델로 멀티뷰 이미지를 생성하여 3D 재구성에 SOTA 단일 이미지를 달성하는 동시 작업인 One-2-3-45를 비교합니다(Liu et al., 2023a).
체리 피킹을 피하기 위해 논문이나 데모 페이지에 제공된 예시 이미지에서 직접 방법을 테스트합니다.
우리는 우리의 방법이 훨씬 더 선명한 세부 정보와 일관된 표면을 생성한다는 것을 알 수 있습니다.
그림의 마지막 행에서 우리는 그림 2에 사용된 두 가지 예를 사용하여 One-2-3-45를 테스트하여 훨씬 더 나쁜 재구성 결과를 보여줍니다.

4.3.2 Limitations
우리가 보여준 고품질 단일 image-to-3D 결과에도 불구하고, 우리의 방법에는 여전히 몇 가지 한계가 있습니다.
첫째, 우리의 LRM은 그림 4와 같이 가려진 영역에 대해 블러한 텍스처를 생성하는 경향이 있습니다.
우리는 이것이 단일 image-to-3D 문제가 본질적으로 확률적이라는 사실, 즉 보이지 않는 영역에 대해 여러 개의 그럴듯한 솔루션이 존재하기 때문이라고 추측합니다.
둘째, 추론 시간 동안, 우리는 테스트 이미지에 고정 카메라 intrinsics 및 extrinsics (Objaverse 학습 데이터와 동일) 세트를 할당합니다.
이러한 카메라 매개 변수는 특히 이미지를 잘라내고 크기를 조정하여 Field-of-View (FoV) 및 주요 지점에 큰 변화를 일으킬 때 ground truth와 잘 정렬되지 않을 수 있습니다.
그림 4는 카메라 매개 변수의 잘못된 가정이 왜곡된 모양 재구성으로 이어질 수 있음을 보여줍니다.
셋째, 우리는 배경이 없는 객체의 이미지만 다룹니다 (Zhang et al., 2020; Barron et al., 2022); 복잡한 장면뿐만 아니라 배경을 다루는 것은 이 작업의 범위를 벗어납니다.
마지막으로, 우리는 Lambertian 물체를 가정하고 예측된 NeRF에서 뷰 의존적 모델링을 생략합니다 (Mildenhall et al., 2021).
따라서 우리는 일부 실제 재료, 예를 들어 반짝이는 금속, 광택 세라믹 등의 뷰 의존적 외관을 충실하게 재구성할 수 없습니다.
5 Conclusion
이 논문에서는 단일 이미지에서 객체를 재구성하기 위해 백만 개의 3D 데이터에서 표현형 3D prior를 학습한 최초의 대형 트랜스포머 기반 프레임워크인 LRM을 제안합니다.
LRM은 훈련 및 추론에 매우 효율적이며; 간단한 이미지 재구성 loss로 종단 간으로 학습할 수 있는 완전한 미분 가능한 네트워크이며, 충실도가 높은 3D 모양을 렌더링하는 데 5초밖에 걸리지 않으므로 광범위한 실제 응용 프로그램이 가능합니다.
대규모 학습 시대에 우리의 아이디어가 향후 연구에서 임의의 야생 이미지로 잘 일반화되는 데이터 기반 3D 대형 재구성 모델을 탐색하는 데 영감을 줄 수 있기를 바랍니다.
Future Directions
섹션 4.3.2에서 언급한 한계를 해결하는 것 외에도, 저희는 향후 연구의 두 가지 방향을 제안합니다;
(1) 모델 및 학습 데이터 확장: 가장 간단한 트랜스포머 기반 설계와 최소한의 정규화를 통해 LRM은 더 큰 이미지 인코더를 적용하고 image-to-triplane 디코더에 더 많은 어텐션 레이어를 추가하며 triplane 표현의 해상도를 높이는 것을 포함하여 더 크고 더 능력 있는 네트워크로 쉽게 확장할 수 있습니다.
반면, LRM은 supervision을 위해 다시점 이미지만 필요하므로 광범위한 3D, 비디오 및 이미지 데이터 세트를 학습에서 활용할 수 있습니다.
저희는 두 가지 접근 방식 모두 모델의 일반화 능력과 재구성 품질을 향상시키는 데 유망할 것으로 예상합니다.
(2) 멀티모달 3D 생성 모델로의 확장: LRM 모델은 text-to-image 생성 모델을 활용하여 먼저 2D 이미지를 생성함으로써 언어에서 새로운 3D 모양을 생성할 수 있는 경로를 구축합니다.
그러나 더 흥미로운 것은 학습된 표현적 triplane 표현을 언어 설명과 3D를 직접 연결하여 효율적인 text-to-3D 생성 및 편집을 가능하게 하는 데 적용할 수 있다고 제안합니다(예: 잠재 디퓨전 (Rombach et al., 2022)).
저희는 향후 연구에서 이러한 아이디어를 탐구할 것입니다.
'3D Vision' 카테고리의 다른 글
| VGGT: Visual Geometry Grounded Transformer (CVPR 2025 Best Paper) (0) | 2025.06.17 |
|---|---|
| Compact 3D Gaussian Representation for Radiance Field (1) | 2025.01.13 |
| Segment Anything in 3D with NeRFs (0) | 2024.05.16 |
| 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (0) | 2024.05.13 |
| GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images (0) | 2023.02.01 |