2025. 6. 17. 11:20ㆍ3D Vision
VGGT: Visual Geometry Grounded Transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, David Novotny
Abstract
VGGT는 카메라 파라미터, 포인트 맵, depth 맵, 3D 포인트 추적 등 장면의 모든 주요 3D 속성을 하나, 몇 개, 수백 개의 뷰에서 직접 추론하는 피드포워드 신경망입니다.
이 접근 방식은 모델이 일반적으로 단일 작업에 제한되고 전문화되어 온 3D 컴퓨터 비전에서 한 걸음 더 나아간 것입니다.
또한 간단하고 효율적이며, 1초 이내에 이미지를 재구성할 수 있으며, 시각적 지오메트리 최적화 기법을 사용한 후처리가 필요한 대안들보다 여전히 뛰어난 성능을 발휘합니다.
이 네트워크는 카메라 파라미터 추정, 멀티 뷰 depth 추정, 밀집 포인트 클라우드 재구성, 3D 포인트 추적 등 여러 3D 작업에서 SOTA 결과를 달성합니다.
또한 사전 학습된 VGGT를 피쳐 백본으로 사용하면 비강체 포인트 추적 및 피드포워드 새로운 뷰 합성과 같은 다운스트림 작업이 크게 향상된다는 것을 보여줍니다.

1. Introduction
우리는 피드포워드 신경망을 활용하여 이미지 세트에 캡처된 장면의 3D 속성을 추정하는 문제를 고려합니다.
전통적으로 3D 재구성은 Bundle Adjustment (BA) [45]과 같은 반복 최적화 기법을 활용하여 시각-기하학적 방법으로 접근해 왔습니다.
머신러닝은 종종 피쳐 매칭 및 단안 depth 예측과 같이 기하학만으로는 해결할 수 없는 과제를 해결하는 중요한 보완적 역할을 해왔습니다.
통합은 점점 더 타이트해지고 있으며, 이제 VGGSfM [125]과 같은 SOTA Structure-from-Motion (SfM) 방법은 머신러닝과 시각 기하학을 미분 가능한 BA를 통해 종단 간 결합합니다.
그럼에도 불구하고 시각 기하학은 여전히 3D 재구성에서 중요한 역할을 하며, 이는 복잡성과 계산 비용을 증가시킵니다.
네트워크가 점점 더 강력해짐에 따라, 우리는 마지막으로 3D 작업을 신경망에 의해 직접 해결할 수 있는지 묻습니다, 이는 기하학적 후처리를 거의 완전히 회피하는 것입니다.
최근 DUSt3R [129] 및 그 진화 MASt3R [62]와 같은 기여는 이 방향에서 유망한 결과를 보여주었지만, 이러한 네트워크는 한 번에 두 개의 이미지만 처리할 수 있으며 후처리에 의존하여 더 많은 이미지를 재구성하고 쌍별 재구성을 융합합니다.
이 논문에서는 후처리에서 3D 지오메트리를 최적화할 필요성을 제거하기 위한 한 걸음 더 나아갑니다.
우리는 장면의 하나, 몇 개 또는 수백 개의 입력 뷰에서 3D 재구성을 수행하는 피드포워드 신경망인 Visual Geometry Grounded Transformer (VGGT)를 도입하여 이를 수행합니다.
VGGT는 카메라 파라미터, depth 맵, 포인트 맵, 3D 포인트 추적을 포함한 전체 3D 속성을 예측합니다.
단 한 번의 전진 패스로, 몇 초 만에 그렇게 합니다.
놀랍게도 추가 처리 없이도 최적화 기반 대안을 능가하는 경우가 많습니다.
이는 사용 가능한 결과를 얻기 위해 여전히 비용이 많이 드는 반복적인 사후 최적화가 필요한 DUSt3R, MASt3R, 또는 VGGSfM에서 상당히 벗어난 것입니다.
우리는 또한 3D 재구성을 위해 특별한 네트워크를 설계할 필요가 없다는 것을 보여줍니다.
대신, VGGT는 프레임 단위와 전역 어텐션을 번갈아 가며 사용하는 것을 제외하고는 특정 3D 또는 기타 귀납적 편향이 없는 상당히 표준적인 대형 트랜스포머 [119]를 기반으로 하지만, 3D 주석이 포함된 다수의 공개 데이터셋을 기반으로 학습되었습니다.
따라서 VGGT는 GPT [1, 29, 148], CLIP [86], DINO [10, 78], Stable Diffusion [34]와 같은 자연어 처리 및 컴퓨터 비전을 위한 대형 모델과 동일한 틀에서 구축됩니다.
이들은 새로운 특정 작업을 파인튜닝하여 해결할 수 있는 다용도 백본으로 부상했습니다.
마찬가지로, 우리는 VGGT로 계산된 피쳐들이 동적 비디오에서의 포인트 추적 및 새로운 뷰 합성과 같은 다운스트림 작업을 크게 향상시킬 수 있음을 보여줍니다.
최근 DepthAnything [142], MoGe [128], LRM [49] 등 대형 3D 신경망의 몇 가지 예가 있습니다.
그러나 이러한 모델은 단안 depth 추정이나 새로운 뷰 합성과 같은 단일 3D 작업에만 초점을 맞춥니다.
반면, VGGT는 공유 백본을 사용하여 모든 관심 3D 양을 함께 예측합니다.
우리는 이러한 상호 연관된 3D 속성을 예측하는 학습이 잠재적인 중복성에도 불구하고 전체 정확도를 향상시킨다는 것을 입증합니다.
동시에, 우리는 추론 과정에서 depth와 카메라 파라미터를 개별적으로 예측하여 포인트 맵을 도출할 수 있으며, 전용 포인트 맵 헤드를 직접 사용하는 것보다 더 나은 정확도를 얻을 수 있음을 보여줍니다.
요약하자면, 우리는 다음과 같은 기여를 합니다:
(1) 우리는 VGGT라는 대형 피드포워드 트랜스포머를 소개합니다, VGGT는 장면의 하나, 몇 개, 심지어 수백 개의 이미지가 주어졌을 때, 카메라 intrinsics 및 extrinsics, 포인트 맵, depth 맵, 3D 포인트 추적을 포함한 모든 주요 3D 속성을 몇 초 만에 예측할 수 있습니다.
(2) 우리는 VGGT의 예측이 직접 사용 가능하며, 경쟁력이 높고 보통 느린 후처리 최적화 기법을 사용하는 SOTA 방법들보다 더 우수하다는 것을 입증합니다.
(3) 또한 BA 후처리와 추가로 결합하면 VGGT는 일부 3D 작업에 특화된 방법과 비교하더라도 전반적으로 SOTA 결과를 달성하여 품질이 크게 향상되는 경우가 많다는 것을 보여줍니다.
2. Related Work
Structure from Motion은 카메라 파라미터를 추정하고 다양한 시점에서 촬영한 정적 장면의 이미지 세트에서 희소 포인트 클라우드를 재구성하는 고전적인 컴퓨터 비전 문제입니다 [45, 77, 80].
전통적인 SfM 파이프라인 [2, 36, 70, 94, 103, 134]은 이미지 매칭, 삼각 측량, 번들 조정 등 여러 단계로 구성되어 있습니다.
COLMAP [94]는 전통적인 파이프라인을 기반으로 한 가장 인기 있는 프레임워크입니다.
최근 몇 년 동안 딥러닝은 SfM 파이프라인의 많은 구성 요소를 개선하여 키포인트 감지 [21, 31, 116, 149]와 이미지 매칭 [11, 67, 92, 99]이 주요 초점 영역으로 자리 잡았습니다.
최근 방법 [5, 102, 109, 112, 113, 118, 122, 125, 131, 160]들은 종단 간 미분 가능한 SfM을 탐구했으며, 여기서 VGGSfM [125]은 도전적인 포토투어리즘 시나리오에서 전통적인 알고리즘을 능가하기 시작했습니다.
Multi-view Stereo는 여러 겹의 이미지에서 장면의 지오메트리를 조밀하게 재구성하는 것을 목표로 하며, 일반적으로 알려진 카메라 파라미터를 가정하여 SfM으로 추정되는 경우가 많습니다.
MVS 방법은 세 가지 범주로 나눌 수 있습니다: 전통적인 수작업 [38, 39, 96, 130], 전역 최적화 [37, 74, 133, 147], 그리고 학습 기반 방법 [42, 72, 84, 145, 157].
SfM과 마찬가지로 학습 기반 MVS 접근 방식도 최근 많은 발전을 보이고 있습니다.
여기서 DUSt3R [129]과 MASt3R [62]는 MVS와 유사하지만 카메라 파라미터 없이 한 쌍의 뷰에서 정렬된 밀집 포인트 클라우드를 직접 추정합니다.
일부 동시 연구 [111, 127, 141, 156]는 DUSt3R의 테스트 시간 최적화를 신경망으로 대체하는 것을 탐구하지만, 이러한 시도는 DUSt3R과 최적이 아니거나 비슷한 성능만을 달성합니다.
대신, VGGT는 DUSt3R과 MASt3R을 큰 차이로 능가합니다.
Tracking-Any-Point는 Particle Video [91]에서 처음 도입되었으며, 딥러닝 시대에 PIP [44]에 의해 부활되었습니다, 이는 동적 동작을 포함한 비디오 시퀀스 전반에서 관심 지점을 추적하는 것을 목표로 합니다.
비디오와 일부 2D 쿼리 포인트가 주어지면, 이 작업은 다른 모든 프레임에서 이러한 포인트의 2D 대응을 예측하는 것입니다.
TAP-Vid [23]는 이 작업을 위한 세 가지 벤치마크를 제안했으며, 이후 TAPIR [24]에서 간단한 베이스라인 방법이 개선되었습니다.
CoTracker [55, 56]는 서로 다른 지점 간의 상관관계를 활용하여 폐색을 추적한 반면, DOT [60]은 폐색을 통한 밀집 추적을 가능하게 했습니다.
최근 TAPTR [63]은 이 작업을 위한 종단 간 트랜스포머를 제안했으며, LocoTrack [13]은 일반적으로 사용되는 포인트별 피쳐를 인근 지역으로 확장했습니다.
이 모든 방법은 전문적인 포인트 트래커입니다.
여기서 우리는 VGGT의 피쳐가 기존 포인트 트래커와 결합될 때 SOTA 추적 성능을 발휘한다는 것을 입증합니다.
3. Method
우리는 VGGT라는 대형 트랜스포머를 소개합니다, 이는 이미지 세트를 입력으로 받아 다양한 3D 양을 출력으로 생성합니다.
우리는 섹션 3.1에서 문제를 소개하는 것으로 시작하여, 섹션 3.2에서 우리의 아키텍처와 섹션 3.3에서 예측 헤드를 소개하고, 마지막으로 섹션 3.4에서 학습 설정을 진행합니다.

3.1. Problem definition and notation
입력은 동일한 3D 장면을 관찰하는 N개의 RGB 이미지 I_i ∈ R^(3×H×W)의 시퀀스 (I_i)입니다.
VGGT의 트랜스포머는 이 시퀀스를 프레임당 하나씩 해당 3D 주석 세트에 매핑하는 함수입니다:

따라서 트랜스포머는 각 이미지 I_i를 카메라 파라미터 g_i ∈ R^9(intrinsics 및 extrinsics), depth 맵 D_i ∈ R^(H×W), 포인트 맵 P_i ∈ R^(3×H×W), 포인트 추적을 위한 C차원 피쳐의 그리드 T_i ∈ R^(C×H×W)에 매핑합니다.
다음으로 이것들이 어떻게 정의되는지 설명하겠습니다.
카메라 파라미터 g_i의 경우, [125]의 매개변수화를 사용하여 회전 쿼터니언 q ∈ R^4, 변환 벡터 t ∈ R^3, field of view f ∈ R^2를 연결한 g = [q, t, f]를 설정합니다.
카메라의 주요 지점이 이미지 중심에 있다고 가정하며, 이는 SfM 프레임워크에서 흔히 볼 수 있습니다 [95, 125].
이미지 I_i의 도메인을 I(I_i) = {1, ... , H} × {1, ... , W}, 즉 픽셀 위치 집합으로 나타냅니다.
depth 맵 D_i는 i번째 카메라에서 관찰된 각 픽셀 위치 y ∈ I(I_i)를 해당 depth 값 D_i(y) ∈ R^+와 연관시킵니다.
마찬가지로, 포인트 맵 P_i는 각 픽셀을 해당 3D 장면 포인트 P_i(y) ∈ R^3와 연관시킵니다.
중요한 것은 DUSt3R [129]에서와 같이 포인트 맵이 시점 불변이라는 점입니다, 이는 3D 포인트 P_i(y)가 첫 번째 카메라 g_1의 좌표계에서 정의된다는 것을 의미하며, 이를 월드 기준 프레임으로 삼습니다.
마지막으로, 키포인트 추적을 위해 [25, 57]과 같은 track-any-point 방법을 따릅니다.
즉, 쿼리 이미지 I_q에 고정된 쿼리 이미지 포인트 y_q가 주어지면 네트워크는 모든 이미지 I_i에서 해당 2D 포인트 y_i ∈ R^2에 의해 형성된 트랙 T⋆(y_q) = (y_i)를 출력합니다.
위의 트랜스포머 f는 트랙을 직접 출력하지 않고 추적에 사용되는 T_i ∈ R^(C×H×W)을 피쳐로 합니다.
추적은 T((y_j), (T_i) = (ˆy_(j,i)) 함수를 구현하는 별도의 모듈에 위임됩니다.
쿼리 포인트 y_q와 트랜스포머 f에 의해 출력된 밀집 추적 피쳐 T_i를 수집한 다음 트랙을 계산합니다.
두 네트워크 f와 T는 엔드 투 엔드로 공동으로 학습됩니다.
Order of Predictions.
입력 시퀀스의 이미지 순서는 임의적이지만, 첫 번째 이미지가 참조 프레임으로 선택되는 경우는 제외됩니다.
네트워크 아키텍처는 첫 번째 프레임을 제외한 모든 프레임에 대해 순열 등가로 설계되었습니다.
Over-complete Predictions.
특히, VGGT에 의해 예측된 모든 양이 독립적인 것은 아닙니다.
예를 들어, DUSt3R [129]에서 볼 수 있듯이 카메라 파라미터 g는 불변 포인트 맵 P에서 추론할 수 있습니다, 예를 들어, Perspective-n-Point (PnP) 문제를 해결함으로써 [35, 61]을 도출할 수 있습니다.
또한, depth 맵은 포인트 맵과 카메라 파라미터로부터 추론할 수 있습니다.
그러나 섹션 4.5에서 볼 수 있듯이, 학습 중에 앞서 언급한 모든 양을 명시적으로 예측하여 VGGT를 작업하면 폐쇄형 관계에 의해 관련된 경우에도 상당한 성능 향상을 가져올 수 있습니다.
한편, 추론 과정에서 독립적으로 추정된 depth 맵과 카메라 파라미터를 결합하면 전문화된 포인트 맵 브랜치를 직접 사용하는 것보다 더 정확한 3D 포인트가 생성되는 것으로 관찰되었습니다.
3.2. Feature Backbone
최근 3D 딥러닝 연구 [53, 129, 132]에 이어, 우리는 최소한의 3D 귀납적 편향을 가진 간단한 아키텍처를 설계하여 모델이 충분한 양의 3D 주석 데이터로부터 학습할 수 있도록 합니다.
특히, 우리는 모델 f를 대형 트랜스포머로 구현합니다 [119].
이를 위해 각 입력 이미지 I는 처음에 DINO [78]을 통해 K개의 토큰 t^I ∈ R^(K×C)로 패치됩니다.
모든 프레임에서 결합된 이미지 토큰 세트, 즉 t_I = ∪{t_i^I}는 이후 메인 네트워크 구조를 통해 프레임별 및 전역 셀프 어텐션 레이어를 번갈아 가며 처리됩니다.
Alternating-Attention.
우리는 Alternating-Attention (AA)을 도입하여 표준 트랜스포머 설계를 약간 조정하고, 트랜스포머가 각 프레임 내에서 그리고 전역적으로 번갈아 가며 초점을 맞추도록 합니다.
구체적으로, 프레임별 셀프 어텐션은 각 프레임 내의 토큰 t_k^I에 개별적으로 집중하고, 전역 셀프 어텐션은 모든 프레임에서 토큰 t^I에 공동으로 집중합니다.
이는 다양한 이미지에 걸쳐 정보를 통합하는 것과 각 이미지 내 토큰의 활성화를 정규화하는 것 사이의 균형을 맞춥니다.
디폴트로 우리는 L = 24개의 전역 및 프레임 단위 어텐션을 사용합니다.
섹션 4에서 우리는 AA 아키텍처가 상당한 성능 향상을 가져온다는 것을 입증합니다.
우리의 아키텍처는 크로스-어텐션 레이어를 사용하지 않으며, 오직 셀프-어텐션 레이어만을 사용합니다.
3.3. Prediction heads
여기에서는 f가 카메라 파라미터, depth 맵, 포인트 맵 및 포인트 추적을 예측하는 방법을 설명합니다.
먼저, 각 입력 이미지 I_i에 대해 추가적인 카메라 토큰 t_i^g ∈ R^(1×C′)와 네 개의 레지스터 토큰 [19] t_i^R ∈ R^(4×C′)로 해당 이미지 토큰 t_i^I를 보강합니다.
(t_i^I, t_i^g, t_i^R)의 concatenation은 AA 트랜스포머로 전달되어 출력 토큰 (ˆt_i^I, ˆt_i^g, ˆt_i^R)을 생성합니다.
여기서 첫 번째 프레임(t_i^g := ¯t^g, t_1^R := ¯t^R)의 카메라 토큰과 레지스터 토큰은 다른 모든 프레임 (t_i^g := t^g, t_i^R := t^R, i ∈ [2, . . ,N])의 토큰 세트와 다른 학습 가능 토큰으로 설정됩니다.
이를 통해 모델은 첫 번째 프레임과 나머지 프레임을 구별하고 첫 번째 카메라의 좌표 프레임에서 3D 예측을 표현할 수 있습니다.
정제된 카메라와 레지스터 토큰은 이제 프레임별로 달라집니다—이는 AA 트랜스포머에 프레임 단위의 셀프 어텐션 레이어가 포함되어 있어 트랜스포머가 카메라와 일치하고 동일한 이미지에서 해당 토큰으로 토큰을 등록할 수 있기 때문입니다.
일반적인 관행에 따라 출력 레지스터 토큰 ˆt_i^R은 폐기되고 ˆt_i^I, ˆt_i^g는 예측에 사용됩니다.
Coordinate Frame.
위에서 언급한 바와 같이, 우리는 첫 번째 카메라 g_1의 좌표 프레임에서 카메라, 포인트 맵, depth 맵을 예측합니다.
따라서 첫 번째 카메라의 extrinsics 카메라 출력은 아이덴티티로 설정됩니다, 즉, 첫 번째 회전 쿼터니언은 q_1 = [0, 0, 0, 1]이고 첫 번째 변환 벡터는 t_1 = [0, 0, 0]입니다.
특수 카메라와 레지스터 토큰 t_1^g := t^g, t_1^R := t^R을 사용하면 트랜스포머가 첫 번째 카메라를 식별할 수 있다는 점을 기억하세요.
Camera Predictions.
카메라 매개변수 (ˆg^i)는 출력 카메라 토큰 (ˆt_i^g)에서 네 개의 추가 셀프 어텐션 레이어와 선형 레이어를 사용하여 예측됩니다.
이것은 카메라 intrinsics와 extrinsics를 예측하는 카메라 헤드를 형성합니다.
Dense Predictions.
출력 이미지 토큰 ˆt_i^I는 밀도가 높은 출력, 즉 depth 맵 D_i, 포인트 맵 P_i, 추적 피쳐 T_i를 예측하는 데 사용됩니다.
보다 구체적으로, ˆt_i^I는 먼저 DPT 레이어 [87]가 있는 조밀한 피쳐 맵 F_i ∈ R^(C′′×H×W)로 변환됩니다.
각 F_i는 해당 depth와 포인트 맵 D_i 및 P_i에 3×3 컨볼루션 레이어로 매핑됩니다.
또한 DPT 헤드는 추적 헤드에 입력 역할을 하는 조밀한 피쳐인 T_i ∈ R&(C×H×W)도 출력합니다.
또한 각 depth 맵과 포인트 맵에 대해 각각 aleatoric uncertainty [58, 76] ∑_i^D ∈ R_+^(H×W)과 ∑_i^P ∈ R_+^(H×W)을 예측합니다.
섹션 3.4에서 설명한 바와 같이, 불확실성 맵은 loss에 사용되며, 학습 후 모델의 예측 신뢰도에 비례합니다.
Tracking.
추적 모듈 T를 구현하기 위해 밀집 추적 피쳐 T_i를 입력으로 사용하는 CoTracker2 아키텍처 [57]를 사용합니다.
보다 구체적으로, 쿼리 이미지 I_q에서 쿼리 포인트 y_j가 주어지면 (학습 중에는 항상 q = 1로 설정하지만, 다른 이미지는 쿼리로 사용할 수 있습니다), 추적 헤드 T는 y와 동일한 3D 포인트에 해당하는 모든 이미지 I_i에서 2D 포인트 T ((y_j), (T_i) = ((y_(j,i))의 집합을 예측합니다.
이를 위해 쿼리 이미지의 피쳐 맵 T_q를 쿼리 포인트 y_j에서 이진 샘플링하여 피쳐를 얻습니다.
이 피쳐는 다른 모든 피쳐 맵 T_i, i ̸= q와 상관관계를 맺어 일련의 상관관계 맵을 얻습니다.
이 맵들은 셀프 어텐션 레이어에 의해 처리되어 최종 2D 포인트 ˆy_i를 예측하며, 이는 모두 y_j와 일치합니다.
VGGSfM [125]과 마찬가지로, 우리의 트래커는 입력 프레임의 시간 순서를 가정하지 않으므로 비디오뿐만 아니라 모든 입력 이미지 세트에 적용할 수 있습니다.
3.4. Training
Training Losses.
우리는 멀티태스크 loss를 사용하여 VGGT 모델 f를 종단 간으로 학습시킵니다:

카메라 (L_camera), depth (L_depth), 포인트 맵(L_pmap) loss의 범위가 비슷하며 서로 가중치를 둘 필요가 없다는 것을 발견했습니다.
추적 loss L_track은 λ = 0.05의 계수로 가중치가 낮아집니다.
각 loss 항목을 차례로 설명합니다.
카메라 loss L_camera는 카메라를 supervise합니다 ˆg: L_camera = ∑ ∥ˆg_i - g_i ∥_ϵ, Huber loss | · |_ϵ을 사용하여 예측된 카메라 ˆg_i와 ground truth g_i를 비교합니다.
depth loss L_depth는 DUSt3R [129]을 따르며, 예측된 depth ˆD_i와 실제 depth D_i 사이의 불일치를 측정하는 aleatoric-uncertainty loss [59, 75]를 예측된 불확실성 맵 ˆ∑_i^D로 구현합니다.
DUSt3R과 달리, 우리는 단안 depth 추정에서 널리 사용되는 그래디언트 기반 항도 적용합니다.
따라서 depth loss는 L_depth = ∑∥∑_i^D ⊙ (ˆD_i -D_i)∥+∥∑_i^D⊙ (∇ˆD_i -∇D_i)∥-α log∑_i^D이며, 여기서 ⊙는 채널-broadcast 요소별 곱입니다.
포인트 맵 loss는 유사하게 정의되지만 포인트 맵 불확실성 σ_i^P: L_pmap = ∑∥ ∑_i^P ⊙ (ˆ P_i - P_i)∥ + ∥ ∑_i^P ⊙ (∇ˆP_i - ∇P_i)∥ - α log ∑_i^P로 정의됩니다.
마지막으로, 추적 loss는 L_track = ∑∑∥y_(j,i) - ˆy_(j,i)∥에 의해 주어집니다.
여기서 외부 합은 쿼리 이미지 I_q의 모든 ground truth 쿼리 지점 y_j에 대해 실행되며, y_(j,i)는 이미지 I_i의 ground truth 대응 관계이며, ˆ y_(j,i)는 추적 모듈의 애플리케이션 T(((y_j)), (T_i)에 의해 얻어진 해당 예측입니다.
또한 CoTracker2 [57]에 따라 주어진 프레임에서 점이 보이는지 여부를 추정하기 위해 가시성 loss (이진 교차 엔트로피)를 적용합니다.
Ground Truth Coordinate Normalization.
장면을 축소하거나 전역 참조 프레임을 변경하면 장면의 이미지는 전혀 영향을 받지 않으므로 이러한 변형은 3D 재구성의 정당한 결과입니다.
우리는 데이터를 정규화하여 이 모호성을 제거하고, 따라서 트랜스포머가 이 특정 변형을 출력하도록 정준적인 선택과 작업을 수행합니다.
우리는 [129]를 따르고 먼저 첫 번째 카메라 g_1의 좌표 프레임에서 모든 양을 표현합니다.
그런 다음 포인트 맵 P에서 원점까지의 모든 3D 포인트의 평균 유클리드 거리를 계산하고 이 척도를 사용하여 카메라 변환 t, 포인트 맵 P, depth 맵 D를 정규화합니다.
중요한 것은 [129]와 달리, 우리는 트랜스포머가 출력하는 예측에 이러한 정규화를 적용하지 않고, 대신 학습 데이터에서 선택한 정규화를 학습하도록 강제한다는 점입니다.
Implementation Details.
기본적으로, 우리는 각각 L = 24개의 전역 어텐션 레이어와 프레임 단위 어텐션 레이어를 사용합니다.
이 모델은 총 약 12억 개의 매개변수로 구성되어 있습니다.
우리는 16만 번의 반복을 위해 AdamW 옵티마이저를 사용하여 학습 loss (2)를 최적화하여 모델을 학습시킵니다.
우리는 최대 학습률 0.0002와 8K 반복 워밍업을 갖춘 코사인 학습률 스케줄러를 사용합니다.
각 배치마다 랜덤 학습 장면에서 2-24 프레임을 랜덤으로 샘플링합니다.
입력 프레임, depth 맵 및 포인트 맵의 크기는 최대 518픽셀로 조정됩니다.
화면 비율은 0.33에서 1.0 사이에서 랜덤으로 조정됩니다.
또한 프레임에 색상 지터, 가우시안 블러, 그레이스케일 증강을 랜덤으로 적용합니다.
이 학습은 9일 동안 64개의 A100 GPU에서 실행됩니다.
학습 안정성을 보장하기 위해 임계값 1.0의 그래디언트 노름 클리핑을 사용합니다.
우리는 GPU 메모리와 계산 효율성을 향상시키기 위해 bfloat16 정밀도와 그래디언트 체크포인트를 활용합니다.
Training Data.
이 모델은 다음을 포함한 크고 다양한 데이터 세트를 사용하여 학습되었습니다: Co3Dv2 [88], BlendMVS [146], DL3DV [69], MegaDepth [64], Kubric [41], WildRGB [135], ScanNet [18], HyperSim [89], Mapillary [71], Habitat [107], Replica [104], MVS-Synth [50], PointOdyssey [159], Virtual KITTI [7], Aria Synth Environments [82], Aria Digital Twin [82] 및 Objaverse [20]와 유사한 아티스트 생성 자산의 합성 데이터셋.
이러한 데이터셋은 실내 및 실외 환경을 포함한 다양한 영역에 걸쳐 있으며, 합성 및 실제 시나리오를 포괄합니다.
이 데이터셋에 대한 3D 주석은 직접 센서 캡처, 합성 엔진 또는 SfM 기법과 같은 여러 출처에서 파생되었습니다 [95].
우리 데이터셋의 조합은 크기와 다양성 면에서 MASt3R [30]과 대체로 비슷합니다.
4. Experiments
이 섹션에서는 여러 작업에서 우리의 방법을 SOTA 접근 방식과 비교하여 그 효과를 보여줍니다.

4.1. Camera Pose Estimation
우리는 먼저 CO3Dv2 [88] 및 RealEstate10K [161] 데이터셋을 사용하여 카메라 포즈 추정 방법을 평가합니다, 이는 표 1에 나와 있습니다.
[124]에 따라 장면당 10개의 이미지를 랜덤으로 선택하고 RRA와 RTA를 결합한 표준 지표 AUC@30을 사용하여 평가합니다.
RRA (Relative Rotation Accuracy)와 RTA (Relative Translation Accuracy)는 각각의 이미지 쌍에 대해 회전과 평행 이동의 상대 각도 오차를 계산합니다.
그런 다음 이러한 각도 오차를 임계값으로 설정하여 정확도 점수를 결정합니다.
AUC는 다양한 임계값에 걸쳐 RRA와 RTA 사이의 최소값을 정확도 임계값 곡선 아래에 있는 영역입니다.
표 1의 (학습 가능한) 방법은 RealEstate10K가 아닌 Co3Dv2에서 학습되었습니다.
우리의 피드포워드 모델은 두 데이터셋 모두에서 경쟁 방법들을 일관되게 능가합니다, 여기에는 일반적으로 10초 이상의 시간이 필요한 DUSt3R/MASt3R의 전역 정렬 및 VGGSfM의 번들 조정과 같은 계산 비용이 많이 드는 최적화 후 단계를 사용하는 방법들도 포함됩니다.
반면, VGGT는 피드포워드 방식으로만 작동하면서도 동일한 하드웨어에서 0.2초만 소요되는 뛰어난 성능을 달성합니다.
동시 작업 [111, 127, 141, 156] (‡로 표시됨)과 비교했을 때, 우리의 방법은 가장 빠른 변형 Fast3R [141]과 유사한 속도로 상당한 성능 이점을 보여줍니다.
또한, 우리 모델의 성능 우위는 표 1에 제시된 방법 중 어느 것도 학습되지 않은 RealEstate10K 데이터셋에서 더욱 두드러집니다.
이것은 VGGT의 우수한 일반화를 입증합니다.
우리의 결과는 또한 VGGT를 BA와 같은 시각 기하학 최적화 방법과 결합함으로써 더욱 향상시킬 수 있음을 보여줍니다.
특히, 예측된 카메라 포즈와 트랙을 BA로 정제하면 정확도가 더욱 향상됩니다.
우리의 방법은 정확도에 가까운 포인트/depth 맵을 직접 예측하며, 이는 BA에 좋은 초기화 역할을 할 수 있습니다.
이렇게 하면 [125]에서 수행한 것처럼 BA에서 삼각 측량과 반복적인 정제가 필요 없게 되어, 우리의 접근 방식이 훨씬 더 빨라집니다 (BA를 사용하더라도 약 2초 정도밖에 걸리지 않습니다).
따라서 VGGT의 피드포워드 모드는 피드포워드 모드든 아니든 이전의 모든 대안을 능가하지만, 최적화 후에도 여전히 이점이 있기 때문에 개선의 여지가 있습니다.

4.2. Multi-view Depth Estimation
MASt3R [62]에 이어, 우리는 DTU [51] 데이터셋에 대한 멀티 뷰 depth 추정 결과를 추가로 평가합니다.
우리는 정확도 (예측에서 ground truth까지의 가장 작은 유클리드 거리), 완전성 (ground truth에서 예측까지의 가장 작은 유클리드 거리), 그리고 이들의 평균 전체적인(즉, Chamfer 거리)을 포함한 표준 DTU 지표를 보고합니다.
표 2에서 DUSt3R과 VGGT는 실제 카메라 없이 작동하는 유일한 두 가지 방법입니다.
MASt3R은 ground truth 카메라를 사용하여 일치하는 데이터를 삼각 측량하여 depth 맵을 도출합니다.
한편, GeoMVSNet과 같은 심층 멀티뷰 스테레오 방법은 ground truth 카메라를 사용하여 비용 볼륨을 구성합니다.
우리의 방법은 DUSt3R을 크게 능가하여 전체 점수를 1.741에서 0.382로 낮췄습니다.
더 중요한 것은 테스트 시 실제 카메라를 알고 있는 방법과 비슷한 결과를 달성한다는 점입니다.
성능이 크게 향상된 이유는 DUSt3R과 같이 여러 쌍의 카메라 삼각 측량을 평균화하는 임시 정렬 절차에 의존하는 대신, 멀티 뷰 삼각 측량을 기본적으로 추론하도록 가르치는 모델의 멀티 이미지 학습 방식 때문일 가능성이 높습니다.
4.3. Point Map Estimation
또한 ETH3D [97] 데이터셋에서 예측된 포인트 클라우드의 정확도를 DUSt3R 및 MASt3R과 비교합니다.
각 장면마다 랜덤으로 10개의 프레임을 샘플링합니다.
예측된 포인트 클라우드는 Umeyama [117] 알고리즘을 사용하여 실제 데이터와 일치합니다.
결과는 공식 마스크를 사용하여 잘못된 점을 걸러낸 후 보고됩니다.
우리는 포인트 맵 추정을 위해 정확성, 완전성, 그리고 전체적인 (Chamfer 거리)을 보고합니다.
표 3에서 볼 수 있듯이, DUSt3R과 MASt3R은 비용이 많이 드는 최적화 (전역 정렬 – 장면당 약 10초)를 수행하지만, 우리의 방법은 단순한 피드포워드 방식에서는 재구성당 0.2초로 여전히 이들을 크게 능가합니다.

한편, 추정된 포인트 맵을 직접 사용하는 것에 비해 depth와 카메라 헤드의 예측 (예: 예측된 카메라 매개변수를 사용하여 예측된 depth 맵을 3D로 투영 해제)이 더 높은 정확도를 제공한다는 것을 발견했습니다.
학습 중에 카메라, depth 맵, 포인트 맵이 공동으로 supervise되더라도 복잡한 작업 (포인트 맵 추정)을 더 간단한 하위 문제(depth 맵 및 카메라 예측)로 분해하는 이점이 있기 때문이라고 생각합니다.


우리는 그림 3의 야생 장면과 그림 4의 추가 예시에서 DUSt3R과의 질적 비교를 제시합니다.
VGGT는 고품질 예측을 출력하고 잘 일반화하여 유화, 겹치지 않는 프레임, 사막과 같이 반복되거나 균일한 질감을 가진 장면과 같은 도전적인 도메인 외부 예제에서 뛰어납니다.
4.4. Image Matching
2-뷰 이미지 매칭은 컴퓨터 비전 분야에서 널리 연구되고 있는 주제입니다 [68, 93, 105].
이는 두 가지 뷰로만 제한되는 엄격한 포인트 추적의 특정 사례를 나타내며, 따라서 우리 모델이 이 작업에 특화되어 있지 않더라도 추적 정확도를 측정하기에 적합한 평가 벤치마크입니다.
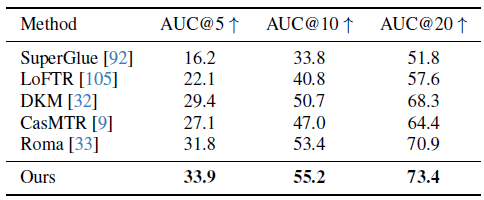
우리는 ScanNet 데이터셋 [18]에서 표준 프로토콜 [33, 93]을 따르고 있으며, 그 결과를 표 4에 보고합니다.
각 이미지 쌍에 대해 일치하는 항목을 추출하고 이를 사용하여 필수 행렬을 추정한 다음 상대적인 카메라 포즈로 분해합니다.
마지막 지표는 AUC로 측정한 상대 포즈 정확도입니다.
평가를 위해 ALIKEED [158]을 사용하여 키포인트를 감지하고 쿼리 포인트 y_q로 처리합니다.
이들은 두 번째 프레임에서 대응 관계를 찾기 위해 추적 지점 T로 전달됩니다.
우리는 Roma [33]의 평가 하이퍼파라미터 (예: 일치 횟수, RANSAC 임계값)를 채택합니다.
두 시점 매칭에 대해 명시적으로 학습되지 않았음에도 불구하고, 표 4는 VGGT가 모든 베이스라인 중에서 가장 높은 정확도를 달성한다는 것을 보여줍니다.
4.5. Ablation Studies
Feature Backbone.
먼저 제안된 Alternating-Attention 설계의 효과를 두 가지 alternating attention 아키텍처와 비교하여 검증합니다: (a) 전역 셀프 어텐션 전용, (b) 크로스-어텐션.
공정한 비교를 위해 모든 모델 변형은 총 2L 어텐션 레이어를 사용하여 동일한 수의 매개변수를 유지합니다.
크로스 어텐션 변형의 경우, 각 프레임은 다른 모든 프레임의 토큰을 독립적으로 처리하여 교차 프레임 정보 융합을 극대화하지만, 특히 입력 프레임의 수가 증가함에 따라 런타임이 크게 증가합니다.
히든 차원과 헤드 수와 같은 하이퍼파라미터는 동일하게 유지됩니다.
포인트 맵 추정 정확도는 장면 기하학과 카메라 매개변수에 대한 모델의 공동 이해를 반영하기 때문에 ablation 연구의 평가 지표로 선택됩니다.
표 5의 결과는 Alternating-Attention 아키텍처가 두 가지 베이스라인 변형 모두에서 뚜렷한 차이로 우수하다는 것을 보여줍니다.
또한, 우리의 다른 예비 탐색 실험들은 크로스 어텐션을 사용하는 아키텍처가 셀프 어텐션만을 사용하는 아키텍처에 비해 전반적으로 성능이 낮다는 것을 일관되게 보여주었습니다.


Multi-task Learning.
우리는 또한 단일 네트워크가 여러 3D 양을 동시에 학습하도록 학습할 때의 이점을 검증합니다, 비록 이러한 출력이 잠재적으로 겹칠 수 있지만 (예: depth 맵과 카메라 파라미터를 함께 사용하면 포인트 맵을 생성할 수 있습니다).
표 6에서 볼 수 있듯이 카메라, depth 또는 트랙 추정 없이 학습할 때 포인트 맵 추정의 정확도가 눈에 띄게 감소합니다.
특히 카메라 매개변수 추정을 통합하면 포인트 맵 정확도가 명확하게 향상되는 반면, depth 추정은 약간의 개선만 기여합니다.

4.6. Finetuning for Downstream Tasks
이제 VGGT 사전 학습된 피쳐 추출기가 다운스트림 작업에서 재사용될 수 있음을 보여줍니다.
피드포워드 새로운 뷰 합성 및 동적 포인트 추적을 위해 이를 보여줍니다.
Feed-forward Novel View Synthesis이 빠르게 진행되고 있습니다 [8, 43, 49, 53, 108, 126, 140, 155].
대부분의 기존 방법은 알려진 카메라 매개변수가 있는 이미지를 입력으로 받아 새로운 카메라 시점에 해당하는 타겟 이미지를 예측합니다.
명시적인 3D 표현에 의존하는 대신, 우리는 LVSM [53]을 따르고 VGGT를 수정하여 타겟 이미지를 직접 출력합니다.
그러나 입력 프레임에 대해 알려진 카메라 매개변수는 가정하지 않습니다.
우리는 LVSM의 학습 및 평가 프로토콜을 면밀히 따릅니다, 예를 들어, 4개의 입력 뷰를 사용하고 타겟 시점을 나타내기 위해 Pl¨ucker ray를 채택합니다.
VGGT를 간단히 수정합니다.
이전과 마찬가지로 입력 이미지는 DINO에 의해 토큰으로 변환됩니다.
그런 다음 타겟 뷰에 대해 컨볼루션 레이어를 사용하여 Pl¨ucker ray 이미지를 토큰으로 인코딩합니다.
입력 이미지와 타겟 뷰를 모두 나타내는 이 토큰들은 AA 트랜스포머에 의해 연결되고 처리됩니다.
그 후, DPT 헤드를 사용하여 타겟 뷰의 RGB 색상을 회귀시킵니다.
소스 이미지에 대해 Pl¨ucker ray를 입력하지 않는다는 점에 유의하는 것이 중요합니다.
따라서 모델에는 이러한 입력 프레임에 대한 카메라 매개변수가 주어지지 않습니다.

LVSM은 Objaverse 데이터셋 [20]을 사용하여 학습되었습니다.
우리는 Objaverse 크기의 약 20% 크기의 유사한 내부 데이터셋을 사용합니다.
학습 및 평가에 대한 자세한 내용은 [53]에서 확인할 수 있습니다.
표 7에 나타난 바와 같이, 입력 카메라 매개변수가 필요 없고 LVSM보다 적은 학습 데이터를 사용함에도 불구하고, 우리 모델은 GSO 데이터셋에서 경쟁력 있는 결과를 얻었습니다 [28].
더 큰 학습 데이터셋을 사용하면 더 나은 결과를 얻을 수 있을 것으로 기대합니다.
정성적인 예시는 그림 6에 나와 있습니다.

Dynamic Point Tracking은 최근 몇 년 동안 매우 경쟁력 있는 작업으로 부상했으며 [25, 44, 57, 136], 학습된 피쳐에 대한 또 다른 다운스트림 애플리케이션으로 사용되고 있습니다.
표준 관행에 따라 다음과 같은 포인트 추적 지표를 보고합니다: Occlusion Accuracy (OA)는 폐색 예측의 이진 정확도로 구성되며, δ_avg^vis는 특정 픽셀 임계값 내에서 정확하게 추적된 가시 지점의 평균 비율로 구성되며, Average Jaccard (AJ)는 추적 및 폐색 예측 정확도를 함께 측정합니다.
우리는 SOTA CoTracker2 모델 [57]을 사전 학습된 피쳐 백본으로 대체하여 적용합니다.
이는 VGGT가 순차적인 비디오가 아닌 정렬되지 않은 이미지 컬렉션에 대해 학습되기 때문에 필요합니다.
우리의 백본은 추적 피쳐 T_i를 예측하여 피쳐 추출기의 출력을 대체하고 나중에 CoTracker2 아키텍처의 나머지 부분에 들어가 최종적으로 트랙을 예측합니다.
우리는 Kubric [41]에서 수정된 전체 추적기를 파인튜닝합니다.
표 8에 나타난 바와 같이, 사전 학습된 VGGT의 통합은 TAPVid 벤치마크에서 CoTracker의 성능을 크게 향상시킵니다 [23].
예를 들어, VGGT의 추적 피쳐는 TAPVid RGB-S 데이터셋에서 δ_avg^vis 메트릭을 78.9에서 84.0으로 향상시킵니다.
TAP-Vid 벤치마크에 다양한 데이터 소스에서 빠른 동적 움직임을 보여주는 비디오가 포함되었음에도 불구하고, 우리 모델의 강력한 성능은 명시적으로 설계되지 않은 시나리오에서도 그 기능의 일반화 능력을 입증합니다.

5. Discussions
Limitations.
우리의 방법은 다양한 현장 장면에 강한 일반화를 보이지만, 몇 가지 한계가 남아 있습니다.
첫째, 현재 모델은 fisheye 이미지나 파노라마 이미지를 지원하지 않습니다.
또한 극단적인 입력 회전이 필요한 조건에서는 재구성 성능이 저하됩니다.
게다가, 우리 모델은 약간의 비강체 운동이 있는 장면을 처리하지만, 상당한 비강체 변형이 포함된 시나리오에서는 실패합니다.
그러나 우리 접근 방식의 중요한 장점은 유연성과 적응의 용이성입니다.
이러한 한계를 해결하기 위해서는 최소한의 아키텍처 수정으로 타겟 데이터셋에서 모델을 파인튜닝함으로써 간단하게 달성할 수 있습니다.
이 적응성은 우리의 방법을 기존 접근 방식과 명확하게 구분합니다, 이 접근 방식은 일반적으로 이러한 특수한 시나리오를 수용하기 위해 테스트 시간 최적화 시 광범위한 재설계가 필요합니다.

Runtime and Memory.
표 9에 나타난 바와 같이, 우리는 다양한 수의 입력 프레임을 처리할 때 피쳐 백본의 추론 실행 시간과 최대 GPU 메모리 사용량을 평가합니다.
측정은 flash attention v3 [98]가 있는 단일 NVIDIA H100 GPU를 사용하여 수행됩니다.
이미지의 해상도는 336 × 518입니다.
사용자가 특정 요구 사항과 가용 자원에 따라 다양한 브랜치 조합을 선택할 수 있기 때문에 피쳐 백본과 관련된 비용에 중점을 둡니다.
카메라 헤드는 가벼워서 일반적으로 런타임의 약 5%와 피쳐 백본에서 사용하는 GPU 메모리의 약 2%를 차지합니다.
DPT 헤드는 프레임당 평균 0.03초와 0.2GB GPU 메모리를 사용합니다.
GPU 메모리가 충분하면 하나의 포워드 패스로 여러 프레임을 효율적으로 처리할 수 있습니다.
동시에, 우리 모델에서는 프레임 간 관계가 피쳐 백본 내에서만 처리되며, DPT 헤드는 프레임마다 독립적인 예측을 수행합니다.
따라서 GPU 리소스에 제약을 받는 사용자는 프레임 단위로 예측을 수행할 수 있습니다.
이러한 절충안은 사용자의 재량에 달려 있습니다.
우리는 전역 셀프 어텐션을 나이브하게 구현하는 것이 많은 토큰으로 인해 메모리 집약도가 높을 수 있다는 것을 인식하고 있습니다.
large language model (LLM) 배포에 사용되는 기술을 사용하여 절약하거나 가속화할 수 있습니다.
예를 들어, Fast3R [141]은 텐서 병렬 처리를 사용하여 여러 GPU로 추론을 가속화하며, 이를 우리 모델에 직접 적용할 수 있습니다.
Patchifying.
섹션 3.2에서 논의한 바와 같이, 우리는 14 × 14 컨볼루션 레이어 또는 사전 학습된 DINOv2 모델을 활용하여 이미지를 토큰으로 패치하는 방법을 탐구했습니다.
경험적 결과에 따르면 DINOv2 모델은 더 나은 성능을 제공하며, 특히 초기 단계에서 훨씬 더 안정적인 학습을 보장합니다.
DINOv2 모델은 학습률이나 운동량과 같은 하이퍼파라미터의 변화에도 덜 민감합니다.
따라서 우리는 모델에서 패치화를 위한 디폴트 방법으로 DINOv2를 선택했습니다.
Differentiable BA.
우리는 또한 VGGSfM [125]에서와 같이 미분 가능한 번들 조정을 사용하는 아이디어를 탐구했습니다.
소규모 예비 실험에서 미분 가능한 BA는 유망한 성능을 보였습니다.
그러나 병목 현상은 학습 중에 발생하는 계산 비용입니다.
Theseus [85]를 사용하여 PyTorch에서 미분 가능한 BA를 활성화하면 일반적으로 각 학습 단계가 약 4배 느려지므로 대규모 학습에는 비용이 많이 듭니다.
학습을 신속하게 진행하기 위해 프레임워크를 맞춤 설정하는 것이 잠재적인 해결책이 될 수 있지만, 이 작업의 범위를 벗어납니다.
따라서 이번 연구에서는 미분 가능한 BA를 포함하지 않기로 결정했지만, 명시적인 3D 주석이 없는 시나리오에서는 효과적인 감독 신호로 작용할 수 있기 때문에 대규모 비지도 학습을 위한 유망한 방향으로 인식하고 있습니다.
Single-view Reconstrucion.
이미지를 복제하여 쌍을 만들어야 하는 DUSt3R 및 MASt3R과 같은 시스템과 달리, 우리의 모델 아키텍처는 본질적으로 단일 이미지의 입력을 지원합니다.
이 경우, 전역 어텐션은 단순히 프레임 단위의 어텐션으로 전환됩니다.
우리 모델은 단일 뷰 재구성을 위해 명시적으로 학습되지 않았지만, 놀라울 정도로 좋은 결과를 보여줍니다.
몇 가지 예는 그림 3과 그림 7에서 찾을 수 있습니다.
더 나은 시각화를 위해 데모를 시도해 보시기를 강력히 권장합니다.

Normalizing Prediction.
섹션 3.4에서 논의된 바와 같이, 우리의 접근 방식은 3D 포인트들의 평균 유클리드 거리를 사용하여 ground truth를 정규화합니다.
DUSt3R과 같은 일부 방법은 네트워크 예측에도 이러한 정규화를 적용하지만, 우리의 연구 결과는 수렴에 필요하지도 않고 최종 모델 성능에 유리하지도 않다는 것을 시사합니다.
게다가, 학습 단계에서 추가적인 불안정성을 유발하는 경향이 있습니다.
6. Conclusions
저희는 수백 개의 입력 뷰에 대한 모든 주요 3D 장면 속성을 직접 추정할 수 있는 피드포워드 신경망인 Visual Geometry Grounded Transformer (VGGT)를 소개합니다.
카메라 매개변수 추정, 멀티뷰 depth 추정, 밀집 포인트 클라우드 재구성, 3D 포인트 추적 등 다양한 3D 작업에서 SOTA 결과를 달성합니다.
우리의 단순하고 신경 우선적인 접근 방식은 기존의 시각 기하학 기반 방법에서 벗어나, 최적화와 후처리를 통해 정확하고 작업별 결과를 얻는 방식입니다.
우리 접근 방식의 단순성과 효율성 덕분에 실시간 애플리케이션에 적합하며, 이는 최적화 기반 접근 방식에 비해 또 다른 이점입니다.
'3D Vision' 카테고리의 다른 글
| MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos (0) | 2025.06.19 |
|---|---|
| Neural Inverse Rendering from Propagating Light (CVPR 2025 Best Student Paper) (2) | 2025.06.18 |
| Compact 3D Gaussian Representation for Radiance Field (1) | 2025.01.13 |
| LRM: Large Reconstruction Model for Single Image to 3D (0) | 2024.05.29 |
| Segment Anything in 3D with NeRFs (0) | 2024.05.16 |