2025. 6. 19. 11:05ㆍ3D Vision
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, Noah Snavely
Abstract
우리는 동적 장면의 캐주얼 단안 비디오에서 카메라 매개변수와 depth 맵을 정확하고 빠르고 견고하게 추정할 수 있는 시스템을 제시합니다.
모션 및 단안 SLAM 기술의 대부분의 기존 구조는 주로 정적인 장면과 많은 시차를 가진 입력 비디오를 가정합니다.
이러한 방법들은 이러한 조건이 없을 때 잘못된 추정치를 생성하는 경향이 있습니다.
최근 신경망 기반 접근 방식은 이러한 문제를 극복하려고 시도하지만, 이러한 방법들은 제어되지 않는 카메라 움직임이나 시야가 알려지지 않은 동적 비디오에서 실행될 때 계산 비용이 많이 들거나 취약합니다.
우리는 Deep Visual SLAM 프레임워크의 놀라운 효과를 입증합니다: 학습 및 추론 방식을 신중하게 수정하면, 이 시스템은 카메라 경로가 제한되지 않은 복잡한 동적 장면의 실제 비디오로 확장할 수 있으며, 여기에는 카메라 시차가 거의 없는 비디오도 포함됩니다.
합성 비디오와 실제 비디오에 대한 광범위한 실험 결과, 우리 시스템이 이전 및 동시 작업에 비해 카메라 포즈와 depth 추정에서 훨씬 더 정확하고 견고하며, 실행 시간이 빠르거나 비슷하다는 것이 입증되었습니다.
1. Introduction
이미지 세트에서 카메라 매개변수와 장면 지오메트리를 추출하는 것은 컴퓨터 비전에서 기본적인 문제로, 일반적으로 structure from motion (SfM) 또는 Simultaneous Localization and Mapping (SLAM)이라고 불립니다.
수십 년간의 연구를 통해 대형 카메라 베이스라인이 있는 정지 장면에 대한 성숙한 알고리즘이 도출되었지만, 이러한 방법은 제어되지 않은 환경에서 촬영된 캐주얼 단안 비디오에 적용될 때 종종 흔들립니다 [26, 78].
이러한 비디오는 핸드헬드 카메라에 의해 자주 촬영되며, 일반적으로 제한된 카메라 움직임 시차 (예: 거의 정지된 카메라 또는 회전하는 카메라)와 넓은 초점 거리를 나타내며, 종종 움직이는 물체와 장면 역학을 포함합니다.
이러한 문제를 해결하기 위한 최근의 노력은 두 가지 주요 전략에 초점을 맞추고 있습니다: 단일 depth 네트워크를 파인튜닝하거나 래디언스 필드를 재구성하여 카메라 및 장면 지오메트리를 최적화하거나 [34, 35, 77, 78], 또는 단안 비디오에서 도출된 depth, flow, 장기 궤적 및 모션 세그멘테이션과 같은 중간 추정치를 전역 최적화 프레임워크로 결합하여 [6, 26, 34, 76, 79].
그러나 이러한 접근 방식은 오랜 시간 지속 시간, 제약 없는 카메라 경로 또는 복잡한 장면 역학을 피쳐로 하는 제약 없는 비디오에 적용될 때 계산 비용이 많이 들거나 취약합니다.
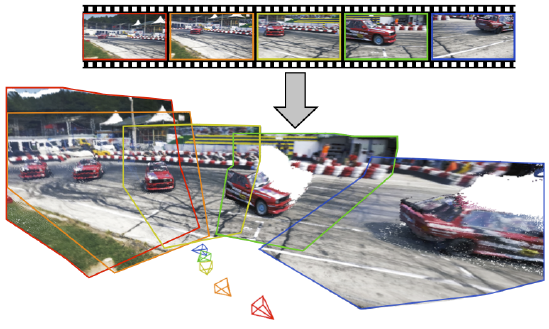
이 연구에서는 동적 장면의 자연스러운 단안 비디오에서 정확하고 빠르고 견고한 카메라 추적 및 depth 추정을 위한 전체 파이프라인인 MegaSaM을 소개합니다.
우리의 접근 방식은 여러 이전 작업의 강점을 결합하여 이전에는 달성할 수 없었던 품질의 결과를 도출합니다, 그림 1 참조.
특히, 우리는 카메라 추적을 위한 이전의 Deep Visual SLAM 프레임워크를 재검토하고 확장합니다.
DROID-SLAM [59]과 같은 Deep Visual SLAM 시스템의 피쳐는 장면 지오메트리와 카메라 포즈 변수를 반복적으로 업데이트하는 미분 가능한 bundle adjustment (BA) 레이어를 채택하고, 카메라와 flow supervision을 통해 대량의 데이터에서 중간 예측을 학습한다는 점입니다.
우리는 이러한 학습된 레이어가 더 어려운 동적 비디오의 경우 정확하고 효율적인 카메라 포즈 추정을 달성하는 데 매우 중요하다는 것을 발견했습니다.
이러한 기반을 바탕으로 동적 장면을 처리하기 위한 주요 혁신 중 하나는 단안 depth prior와 모션 확률 맵을 미분 가능한 SLAM 패러다임에 통합하는 것입니다.
또한, 우리는 비디오에서 구조와 카메라 매개변수의 관측 가능성을 분석하고, 입력 비디오에 의해 카메라 매개변수가 제대로 제한되지 않을 때 시스템의 견고성을 향상시키는 불확실성 인식 전역 BA 방식을 도입합니다.
또한 테스트 시간 네트워크 파인튜닝 없이도 일관된 비디오 depth를 정확하고 효율적으로 얻을 수 있는 방법을 시연합니다.
합성과 실제 데이터셋에 대한 광범위한 평가 결과, 우리 시스템은 카메라와 depth 추정 정확도 모두에서 이전 및 동시 베이스라인을 크게 능가하는 동시에 경쟁력 있는 또는 우수한 런타임 성능을 달성하는 것으로 나타났습니다.
2. Related Work
Visual SLAM and SfM.
SLAM과 SfM은 비디오 시퀀스나 비정형 이미지 컬렉션에서 카메라 매개변수와 3D 장면 구조를 추정하는 데 사용됩니다.
기존 접근 방식은 먼저 피쳐 매칭 [1, 5, 8, 25, 37, 44, 45, 51, 55, 56] 또는 photometric 정렬 [9, 10, 38]을 통해 이미지 간의 2D 대응 관계를 추정함으로써 이 문제를 해결합니다.
그런 다음 bundle adjustment (BA)을 통해 재투영 또는 사진 일관성 오류를 최소화하여 3D 포인트 위치와 카메라 매개변수를 최적화합니다 [61].
최근에는 Deep Visual SLAM 및 SfM 시스템이 등장하여 쌍 또는 장기 대응 관계를 추정합니다 [2, 7, 18, 19, 21, 54, 57, 59, 60, 63, 65, 73] 또는 전역 3D 포인트 클라우드를 재구성하기 위해 딥 뉴럴 네트워크를 채택하고 있습니다 [11, 33, 41].
이러한 방법들은 정확한 카메라 추적 및 재구성을 보여주지만, 일반적으로 주로 정적인 장면과 프레임 간의 충분한 카메라 베이스라인을 가정합니다.
따라서 장면 동역학이나 제한된 카메라 시차가 있는 경우 성능이 크게 저하되거나 완전히 실패할 수 있습니다.
최근 몇몇 연구들은 이러한 한계를 해결하는 데 있어 우리와 유사한 목표를 공유하고 있습니다.
Robust-CVD [26]와 CasualSAM [78]은 공간적으로 변화하는 스플라인 또는 파인튜닝 단안 depth 네트워크를 최적화하여 동적 비디오에서 카메라 매개변수와 밀집 depth 맵을 공동으로 추정합니다.
Particle-SfM [79]과 LEAP-VO [6]는 먼저 장거리 궤적을 기반으로 움직이는 물체 마스크를 추론한 다음, 이 정보를 사용하여 번들 조정 시 피쳐의 기여도를 줄입니다.
동시 작업인 MonST3R [76]은 DuST3R [66]의 3D 포인트 클라우드 표현을 채택하고 추가 정렬 최적화를 통해 카메라를 위치 지정합니다.
우리의 접근 방식은 유사한 아이디어를 공유하지만, 미분 가능한 SLAM 시스템을 기본 동적 장면의 중간 예측과 결합하면 성능이 크게 향상될 수 있음을 보여줍니다.
Monocular depth.
최근 단안 depth 예측에 관한 연구는 대량의 합성 및 실제 데이터 [13, 22, 29, 30, 43, 46, 47, 49, 71, 72, 74, 75]에 대해 심층 신경망을 학습함으로써 야생 단일 이미지에 대한 강력한 일반화를 보여주었습니다.
그러나 이러한 단일 이미지 모델은 비디오에서 시간적으로 일관되지 않은 depth를 생성하는 경향이 있습니다.
이 문제를 극복하기 위해, 이전 기술들은 테스트 시간 최적화를 수행하여 단일 depth 모델을 파인튜닝하거나 [35, 77] 트랜스포머 또는 디퓨전 모델을 사용하여 비디오 depth를 직접 예측하는 방법을 제안합니다 [20, 53, 69].
우리의 접근 방식은 첫 번째 패러다임의 정신을 따르지만, 모든 비디오에 대해 값비싼 네트워크 파인튜닝 없이 더 나은 비디오 depth 품질을 달성할 수 있음을 보여줍니다.
Dynamic scene reconstruction.
최근 여러 연구들은 시간에 따라 변하는 래디언스 필드 표현을 채택하여 야생 비디오에서 동적 장면 재구성과 새로운 뷰 합성을 수행했습니다 [12, 27, 31, 32, 34, 39, 40, 64, 67, 70].
대부분의 레디언스 필드 재구성 방법은 카메라 파라미터나 비디오 depth 맵을 입력으로 필요로 하며, 우리의 출력은 이러한 시스템의 입력으로 사용할 수 있기 때문에 우리의 작업은 대부분의 이러한 기술과 직교합니다.
3. MegaSaM
제약이 없고 연속적인 비디오 시퀀스 V = {I_i ∈ R^(H×W))}가 주어졌을 때, 우리의 목표는 카메라 포즈 ˆG_i ∈ SE(3), 초점 거리 ˆf (알 수 없는 경우), 그리고 밀집 비디오 depth 맵 D = {ˆD_i}를 추정하는 것입니다.
우리의 접근 방식은 입력 비디오에 있는 카메라와 물체의 움직임에 아무런 제약을 가하지 않습니다.
카메라 추적 및 비디오 depth 추정 모듈은 각각 이전의 Deep Visual SLAM (특히 DROID-SLAM[5 9])과 캐주얼 구조 및 모션 [78] 프레임워크를 기반으로 합니다.
다음 섹션에서는 먼저 충분한 카메라 움직임 시차를 가진 정적 장면의 비디오를 추적하기 위해 설계된 Deep Visual SLAM 프레임워크의 주요 구성 요소를 요약합니다 (섹션 3.1).
그런 다음 학습 및 추론 단계 모두에서 제약 없는 동적 비디오에 대해 빠르고 견고하며 정확한 카메라 추적을 가능하게 하는 이 프레임워크의 주요 수정 사항을 소개합니다 (섹션 3.2).
마지막으로, 추정된 카메라 매개변수를 고려하여 일관된 비디오 depth를 효율적으로 추정하는 방법을 시연합니다 (섹션 3.3).
3.1. Deep visual SLAM formulation
DROID-SLAM [59]과 같은 Deep Visual SLAM 시스템은 구조와 모션 매개변수를 반복적으로 업데이트하는 미분 가능하고 학습된 bundle adjustment (BA) 레이어로 특징지어집니다.
특히, 그들은 비디오를 처리하는 동안 두 가지 상태 변수를 추적합니다: 프레임당 저해상도 디스패리티 맵 ˆd_i ∈ R^(H/8 × W/8), 그리고 카메라 포즈 ˆG_i ∈ SE(3).
이러한 변수는 학습 및 추론 단계 모두에서 반복적으로 업데이트되며, 이는 중첩된 field-of-view를 가진 프레임을 연결하기 위해 동적으로 구축된 프레임 그래프 (I_i, I_j) ∈ P의 이미지 쌍 집합에서 작동합니다.
프레임 그래프에서 두 개의 비디오 프레임 I_i와 I_j가 입력으로 주어졌을 때, DROID-SLAM은 반복적인 방식으로 컨볼루션 게이트 순환 유닛을 통해 2D 대응 필드 ˆu_ij ∈ R^(H/8 × W/8 × W/8)와 신뢰도 ˆw_ij ∈ R^(H/8 × W/8)을 예측하는 방법을 학습합니다: (ˆu_ij^(k+1), ˆw_ij^(k+1)) = F(I_i, I_j , ˆu_ij^k, ˆw_ij^k), 여기서 k는 k번째 반복을 나타냅니다.
또한, 경직된 동작 대응 필드는 카메라의 ego-모션과 멀티 뷰 제약을 통해 디스패리티로부터 유도될 수도 있습니다:
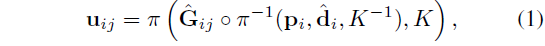
, p_i는 픽셀 좌표의 그리드를 나타내고, π는 원근 투영 연산자를 나타내며, ˆG_ij = ˆG_j ◦ ˆG_i^-1은 I_i와 I_j 사이의 상대적인 카메라 포즈를 나타내며, K ∈ R^(3×3)은 카메라 intrinsic 행렬을 나타냅니다.
Differentiable bundle adjustment.
DROID-SLAM은 알려진 초점 거리를 가정하지만, 일반적으로 실제 비디오에서는 초점 거리가 사전에 알려져 있지 않습니다.
따라서, 우리는 네트워크가 예측한 현재 flow와 카메라 매개변수 및 디스패리티에서 파생된 강체 운동 흐름 간의 가중 재투영 비용을 반복적으로 최소화하여 카메라 포즈, 초점 거리 및 디스패리티를 최적화합니다 [16]:

, 여기서 가중치는 Σ_ij = diag(ˆw_ij)^−1.
미분 가능한 종단 간 학습을 가능하게 하기 위해, 우리는 Levenberg-Marquardt 알고리즘을 사용하여 식 2의 최적화를 수행합니다:

, 여기서 Δξ = (ΔG, Δd, Δf)^T는 상태 변수의 매개변수 업데이트이고, J는 매개변수에 대한 재투영 잔차의 야코비안이며, W는 각 프레임 쌍에서 ˆw_ij를 포함하는 대각선 행렬입니다.
λ은 각 BA 반복 동안 네트워크가 예측한 감쇠 계수입니다.
카메라 매개변수 (포즈 및 초점 거리 포함)와 디스패리티 변수를 식 3의 LHS에서 근사된 헤시안을 다음 블록 행렬 형식으로 나누어 분리할 수 있습니다:

식 2의 각 쌍별 재투영 항에는 단일 디스패리티 변수만 포함되므로 식 4의 H_d는 대각 행렬이므로 Schur complement trick [61]을 사용하여 매개변수 업데이트를 효율적으로 계산할 수 있으며, 이는 완전히 미분 가능한 BA 업데이트로 이어집니다:

Training.
플로우와 불확실성 예측은 정적 장면의 합성 비디오 시퀀스 모음에서 종단 간 학습됩니다:

, L_cam과 L_flow는 추정된 카메라 매개변수와 BA 레이어에서 유도된 자아 운동 플로우를 해당하는 실제 데이터와 비교한 loss입니다.

3.2. Scaling to in-the-wild dynamic videos
Deep Visual SLAM은 정적인 장면이 포함되고 충분한 카메라 변환이 가능한 비디오에서는 비교적 잘 작동하지만, 그림 2의 첫 번째 열에 표시된 것처럼 동적 콘텐츠의 비디오나 시차가 제한된 비디오에서 작동할 때 성능이 저하됩니다.
이러한 문제를 극복하기 위해, 우리는 원래의 학습 및 추론 파이프라인에 대한 주요 수정 사항을 제안합니다.
먼저, 우리 모델은 미분 가능한 BA 레이어 내의 동적 요소를 축소하기 위해 플로우와 불확실성과 함께 학습되는 객체 이동 맵을 예측합니다.
둘째, 우리는 단일 depth 추정치의 prior를 학습 및 추론 파이프라인에 통합하고, 불확실성을 인식하는 전역 BA를 수행할 것을 제안합니다, 이 두 가지 방법은 도전적인 캐주얼 동적 비디오에서 객체와 카메라의 움직임을 명확하게 하는 데 도움이 됩니다.
우리 시스템은 합성 데이터만으로 학습되었지만, 실제 비디오에 대한 강력한 일반화를 보여줍니다.
3.2.1 Training
Learning motion probability.
섹션 3.1에서 선택된 모든 이미지 쌍 (I_i, I_j) ∈ P에 대해 우리 모델이 각 BA 반복에서 2D 플로우 ˆu_ij 및 관련 신뢰도 ˆw_ij를 예측하며, 이러한 예측은 정적 장면의 합성 시퀀스로부터 supervise된다는 점을 기억하세요.
동적 장면을 처리하도록 모델을 확장하기 위해, 우리는 해당 ground truth supervision을 통해 동적 장면의 비디오에서 모델 예측을 직접 학습할 수 있습니다, 이는 쌍별 불확실성이 학습 중에 객체의 움직임 정보를 자동으로 포함하기를 희망합니다.
그러나 이 간단한 학습 전략은 미분 가능한 BA 레이어의 불안정한 학습 행동으로 인해 최적의 결과를 내지 못하는 경향이 있음을 발견했습니다.
대신, 우리는 추가적인 네트워크 F_m을 사용하여 I_i 조건하에 객체 이동 확률 맵 m_i ∈ R^(H/8 × W/8) = F_m ({I_i} ∪ N(i))와 그 인접한 키프레임 집합 N(i) = {I_j |(i, j) ∈ P}를 반복적으로 예측할 것을 제안합니다.
이 이동 맵은 멀티프레임 정보를 기반으로 동적 콘텐츠에 해당하는 픽셀을 예측하도록 특별히 supervise됩니다.
각 BA 반복 동안, 우리는 쌍별 플로우 신뢰도 ˆw_ij와 객체 이동 맵 m_i를 결합하여 식 2에서 최종 가중치를 형성합니다: ˜w_ij = ˆw_ij m_i.
또한, 우리는 정적 비디오와 동적 비디오를 혼합하여 모델을 학습시켜 이동 확률 맵과 함께 2D 플로우를 효과적으로 학습하는 2단계 학습 방식을 설계합니다.
첫 번째 자아 움직임 사전 학습 단계에서는 동적 비디오 데이터 없이 정적 장면의 합성 데이터를 사용하여 예측된 플로우와 신뢰도 맵 (식 7의 loss를 사용하여)을 supervising하여 원래의 Deep SLAM 모델 F를 학습시킵니다.
이 단계는 모델이 자아 움직임에 의해서만 유도되는 쌍별 플로우와 그에 상응하는 신뢰도를 효과적으로 학습하는 데 도움이 됩니다.
두 번째 동적 파인튜닝 단계에서는 합성 동적 비디오에서 F와 파인튜닝 F_m의 매개변수를 freeze하고, 각 반복 동안 사전 학습된 F의 피쳐에 F_m을 조건화하여 이동 확률 맵 m_i를 예측하며, 카메라와 교차 엔트로피 loss를 모두 supervising합니다:

이 단계는 2D 대응 학습을 통해 학습 장면의 역학을 연결하여, 미분 가능한 BA 프레임워크에 대한 보다 안정적이고 효과적인 학습 행동을 유도합니다.
우리는 이 학습 방식이 우리의 ablation 연구에서 보여준 것처럼 동적 비디오에 대한 정확한 카메라 추정 결과를 생성하는 데 매우 중요하다는 것을 발견했습니다.
우리는 그림 3에서 학습된 운동 확률 맵 m_i를 시각화합니다.

Disparity and camera initialization.
DROID-SLAM은 단순히 일정한 값 1로 설정하여 디스패리티 ˆd를 초기화합니다.
그러나 우리는 이 초기화가 제한된 카메라 베이스라인과 복잡한 장면 역학을 가진 비디오에서 정확한 카메라 추적을 수행하지 못한다는 것을 발견했습니다.
최근 연구 [31, 32, 34, 64]에서 영감을 받아 학습 및 추론 단계 모두에서 단일 depth prior를 통합하여 데이터 기반 초기화를 수행합니다.
학습 중에, 우리는 각 학습 시퀀스의 실제 depth에서 차용한 추정된 전역 규모와 이동을 사용하여 DepthAnything [71]로부터 디스패리티를 두고 ˆd를 초기화합니다.
각 학습 시퀀스마다 게이지 모호성을 제거하기 위해 처음 두 개의 카메라 포즈를 ground-truth에 초기화하고, ground truth를 25% 랜덤으로 교란하여 카메라 초점 거리를 초기화합니다.
3.2.2 Inference
우리의 추론 파이프라인은 두 가지 구성 요소로 구성되어 있습니다:
(i) 프론트엔드 모듈은 프레임 선택 후 슬라이딩 윈도우 BA를 실행하여 키프레임용 카메라를 등록합니다.
(ii) 백엔드 모듈은 모든 비디오 프레임에 대해 전역 BA를 수행하여 추정치를 정제합니다.
이 하위 섹션에서는 추론 시 수정한 내용을 설명합니다.
Initialization and frontend tracking.
학습과 마찬가지로, 우리는 단일 depth 및 초점 거리 예측을 추론 파이프라인에 통합합니다.
특히, 우리는 메트릭 정렬 단안 디스패리티 D_i^align = ˆα D_i^rel + ˆβ를 사용하여 프레임별 디스패리티 맵 ˆ d_i를 초기화합니다, 여기서 D_i^rel은 [71]부터 프레임별 아핀-불변 디스패리티이며, 비디오별 전역 스케일 및 시프트 매개변수 (ˆα, ˆβ)는 중앙값 정렬 D_i^rel을 통해 UniDepth [43]의 추가 메트릭 depth 추정치 D_i^abs를 통해 추정됩니다: ˆα_i = (D_i^abs - median_i(D_i^abs)) / (D_i^rel - median(D_i^rel)), ˆβ = median (D_i^abs - ˆα D_i^rel).
UniDepth 모델은 각 프레임의 초점 거리도 예측합니다; 비디오 프레임 전반에 걸친 중앙값 추정치를 사용하여 프론트엔드 단계에서 고정된 초기 초점 거리 추정치 ˆf를 얻습니다.
SLAM 시스템을 초기화하기 위해 N_init = 8개의 액티브 이미지 세트가 있을 때까지 충분한 쌍별 움직임이 있는 키프레임을 축적합니다.
우리는 디스패리티 변수 ˆd_i를 정렬된 단안 디스패리티 D_i^align에 고정하면서 카메라 모션 전용 번들 조정을 수행하여 이러한 키프레임에 대한 카메라 포즈를 초기화합니다.
초기화 후, 우리는 점진적으로 새로운 키프레임을 추가하고, 오래된 키프레임을 제거하며, 슬라이딩 윈도우 방식으로 로컬 BA를 수행합니다, 각 키프레임 디스패리티도 정렬된 단일-디스패리티로 초기화됩니다.
이 단계에서 BA cost 함수는 재투영 오류와 단일 depth 정규화 항으로 구성됩니다:

Uncertainty-aware global BA.
백엔드 모듈은 먼저 모든 키프레임에서 전역 BA를 수행합니다.
그런 다음 모듈은 포즈 그래프 최적화를 수행하여 키프레임이 아닌 포즈를 등록합니다.
마지막으로, 백엔드 모듈은 모든 비디오 프레임에서 전역 BA를 통해 전체 카메라 궤적을 정밀하게 조정합니다.
이 디자인은 의문을 제기합니다: 식 9의 단일 depth 정규화를 전역 번들 조정에 추가해야 할까요 (또는 언제 추가해야 할까요?)?
한편, 입력 비디오에 충분한 카메라 베이스라인이 있는 경우 문제가 이미 잘 제한되어 있고 실제로 모노 depth의 오류로 인해 카메라 추적 정확도가 떨어질 수 있기 때문에 모노 depth 정규화가 필요하지 않다는 것을 알 수 있습니다.
반면에, 카메라 베이스라인이 거의 없는 회전 카메라에서 비디오를 캡처하면 그림 2의 두 번째 열과 같이 추가 제약 없이 재투영 전용 BA를 수행하면 솔루션이 퇴화될 수 있습니다.
그 이유를 알아보기 위해, 우리는 식 4의 선형 시스템에서 근사 헤시안 행렬을 탐구합니다.
Goli et al. [14]에서 볼 수 있듯이, posterior p(θ|I)가 주어지면 라플라스 근사를 사용하여 인버스 헤시안을 통해 변수의 공분산 ∑을 추정할 수 있습니다: ∑_θ = -H(θ∗)-1, 여기서 θ∗는 매개변수의 MAP 추정치이고 ∑_θ는 추정 변수의 인식적 불확실성을 나타냅니다 [23].
입력 프레임의 수가 많을 때 전체 헤시안을 뒤집는 것은 계산 비용이 많이 들기 때문에, 우리는 Ritter et al. [48]을 따르고 헤시안의 대각선을 통해 ∑_θ을 근사합니다:

직관적으로 식 2의 재투영 오차를 고려할 때, 추정 변수 J_θ의 야코비안은 변수를 교란시키면 재투영 오차가 얼마나 변하는지를 나타냅니다.
따라서 매개변수를 교란할 때 불확실성 ∑_θ은 재투영 오류에 거의 영향을 미치지 않습니다.
구체적으로, 디스패리티 변수를 고려하고 입력 비디오가 정적 카메라에 포착되는 극단적인 경우를 고려해 보겠습니다.
이 경우, 쌍별 재투영 오차는 차이의 함수로서 변하지 않을 것이며, 이는 추정된 디스패리티의 큰 불확실성을 의미합니다; 즉, 비디오만으로는 차이를 관찰할 수 없습니다.
우리는 그림 4에서 추정된 정규화된 디스패리티 ∑_d의 공간적 불확실성을 시각화합니다:
첫 번째 줄은 회전 지배적인 움직임이 특징인 비디오를 보여주고, 두 번째 줄은 전진 카메라로 촬영한 비디오를 보여줍니다.
세 번째 열의 색상 막대에서 첫 번째 예제에서 불균형 불확실성의 범위인 ∑_d가 훨씬 더 높다는 것을 알 수 있습니다.

이러한 불확실성 정량화는 카메라와 디스패리티 매개변수의 관측 가능성을 측정할 수 있게 하여, 단일 depth 정규화를 추가해야 할 위치와 카메라 초점 거리 최적화를 언제 꺼야 할지 결정할 수 있게 해줍니다.
실제로, 우리는 테스트한 모든 비디오에서 정규화된 디스패리티의 중앙값 불확실성과 정규화된 초점 거리의 불확실성을 단순히 확인하는 것이 효과적이라는 것을 발견했습니다.
특히, 프론트엔드 추적을 완료한 후 모든 키프레임에서 형성된 디스패리티 헤시안의 대각선 항목을 검색하여 그 중간값med (diag(H_d))과 공유 초점 거리 H_f의 헤시안 항목을 계산합니다.
그런 다음 중앙값 차이 Hessian w_d = γ_d exp (-β_d med (H_d))를 기준으로 단일 depth 정규화 가중치를 설정합니다.
즉, 제한된 카메라 움직임 시차로 인해 입력 영상만으로는 카메라 포즈를 관찰할 수 없는 경우 단일 depth 정규화를 가능하게 합니다.
또한, H_f < τ_f인 경우 초점 거리 최적화를 비활성화합니다, 이 조건은 입력에서 초점 거리를 관찰할 수 없음을 나타내기 때문입니다.
3.3. Consistent depth optimization
선택적으로, 추정된 카메라 매개변수가 주어졌을 때 추정된 저해상도 디스패리티 변수보다 더 높은 해상도로 더 정확하고 일관된 비디오 depth를 얻을 수 있습니다.
특히, 우리는 CasualSAM [78]을 따르고 프레임별 aleatoric 불확실성 맵과 함께 비디오 depth에 대해 추가적인 1차 최적화를 수행합니다.
우리의 목표는 세 가지 cost 함수로 구성됩니다:

, 여기서 C_flow는 쌍별 2D 플로우 재투영 loss, C_temp는 시간적 depth 일관성 loss, C_prior는 스케일 불변 단일 depth prior loss입니다.
기성 모듈 [58]로부터 원래 프레임 해상도에서 2D 옵티컬 플로우를 도출합니다.
저희 디자인은 CasualSAM과 비교했을 때 몇 가지 차이점이 있습니다:
(i) 시간이 많이 소요되는 단일 depth 네트워크 파인튜닝을 수행하는 대신, 입력 비디오에 대한 디스패리티와 불확실성을 위해 일련의 변수를 구성하고 최적화합니다.
(ii) 최적화 중에 카메라와 depth를 공동으로 최적화하는 대신 카메라 매개변수를 수정합니다.
(iii) 표면 법선 일관성과 멀티 스케일 depth 그래디언트 매칭 loss [29, 50]를 채택하여 CasualSAM [78]에서 사용된 depth prior loss를 대체합니다.
우리는 이러한 수정이 훨씬 더 빠른 최적화 시간과 더 정확한 비디오 depth 추정으로 이어진다는 것을 발견했습니다.
loss 및 최적화 방안에 대한 자세한 내용은 보충 자료를 참조하시기 바랍니다.
4. Experiments
Implementation details.
2단계 학습 방식에서는 먼저 TartanAir의 163개 장면 [68]과 정적 Kubric의 5K 비디오 [15]를 포함한 정적 장면의 합성 데이터를 기반으로 모델을 사전 학습합니다.
두 번째 단계에서는 Kubric의 11K 동적 비디오에서 모션 모듈 F_m을 파인튜닝합니다 [15].
각 학습 예제는 7프레임 비디오 시퀀스로 구성되어 있습니다.
학습 중에 w_flow = 0.02, w_motion = 0.1을 설정했습니다.
Adam 옵티마이저 [24]를 사용하여 카메라 추적 모듈을 학습하는 데는 8대의 Nvidia 80G A100이 사용되어 약 4일이 소요됩니다.
초기화 및 프론트엔드 단계에서는 단일 depth 정규화 가중치 w_d = 0.05를 설정합니다.
백엔드 단계에서는 γ_d = 1 × 10^-4, β_d = 0.05, τ_f = 50, 일관된 비디오 depth 최적화 측면에서 w_flow = w_prior = 1.0, w_temp = 0.2를 설정합니다.
우리 최적화의 평균 실행 시간은 Sintel에서 해상도 336 × 144의 비디오 depth에서 1.3 FPS이지만, 우리는 이를 672 × 288의 해상도로 시각화하고 평가합니다.
네트워크 아키텍처 및 기타 학슺/추론 설정에 대한 자세한 내용은 독자들에게 보충 자료를 참조해 주시기 바랍니다.
Baseline.
우리는 MegaSaM을 보정된 (알려진 초점 거리) 비디오와 보정되지 않은 (알려지지 않은 초점 거리) 비디오 모두에서 최신 카메라 포즈 추정 방법과 비교합니다.
ACE-Zero [3]은 정적 장면을 위해 설계된 장면 좌표 회귀 기반의 SOTA 카메라 위치 추정 방법입니다.
CasualSAM [78]과 RodDynRF [34]는 단일 depth 네트워크 또는 InstantNGP [36]을 최적화하여 카메라 파라미터와 밀집 장면 기하학을 공동으로 추정합니다.
Particle-SfM [79]과 LEAP-VO [6]는 장기 궤적에서 모션 세그멘테이션을 예측한 후, 이를 사용하여 표준 시각 오도메트리 또는 SfM 파이프라인 내에서 움직이는 물체를 가려내어 동적 비디오에서 카메라를 추정합니다.
동시 작업인 MonST3R [76]은 동적 장면을 처리하기 위해 Dust3R [66]을 확장하여 입력 프레임 쌍에서 예측된 전역 3D 포인트 클라우드로부터 카메라 매개변수를 추정합니다.
depth 정확도를 평가하기 위해 CasualSAM, MonST3R, VideoCraftfter [20]의 출력과 비교합니다.
완성도를 위해 DepthAnything-V2 [72]의 원시 모노 depth도 포함되어 있습니다.
위의 모든 베이스라인은 단일 Nvidia A100 GPU를 사용하여 동일한 머신에서 각각의 오픈 소스 구현을 사용하여 실행됩니다.
4.1. Benchmarks and metrics
MPI Sintel.
MPI Sintel [4] 데이터셋에는 복잡한 객체 동작과 카메라 경로로 구성된 애니메이션 비디오 시퀀스가 포함되어 있습니다.
CasualSAM [78]에 이어, 우리는 데이터셋의 18개 시퀀스에 대한 모든 방법을 평가합니다, 각 시퀀스는 20-50개의 이미지로 구성되어 있습니다.
DyCheck.
DyCheck 데이터셋 [12]은 처음에 새로운 뷰 합성 작업을 평가하기 위해 설계되었으며, 핸드헬드 카메라에서 촬영한 동적 장면의 실제 비디오를 포함하고 있습니다.
각 동영상에는 180~500프레임이 포함되어 있습니다.
우리는 Shape of Motion [64]에서 제공하는 정교한 카메라 매개변수와 센서 depth를 실제 데이터로 사용합니다.
In-the-wild.
우리는 또한 야생 내 동적 비디오에 대해 평가합니다.
구체적으로, DynIBaR [32]에서 사용된 12개의 야생 내 비디오에 대한 비교를 포함합니다.
이 비디오들은 긴 시간 (100-600프레임), 제어되지 않는 카메라 경로, 그리고 복잡한 장면 동작을 특징으로 합니다.
인스턴스 ID를 수동으로 지정하는 인스턴스 세그멘테이션 [17]을 통해 ground truth 이동 마스크를 구성하고, 이를 사용하여 COLMAP [51]을 실행하기 전에 움직이는 물체를 마스킹하여 신뢰할 수 있는 카메라 매개변수를 얻습니다.
Metrics.
카메라 포즈 추정을 평가하기 위해 표준 오차 지표를 사용합니다: Absolute Translation Error (ATE), Relative Translation Error (RTE), Relative Rotation Error (RRE).
CasualSaM을 따라, 다양한 비디오의 카메라 궤적이 크게 달라질 수 있고, 궤적이 긴 비디오가 계산된 지표에 더 높은 영향을 미칠 수 있기 때문에, 우리는 ground truth 카메라 궤적을 단위 길이로 정규화합니다.
모든 방법에 대해, 우리는 Umeyama 정렬 [62]을 통해 전역 Sim(3) 변환을 계산하여 추정된 카메라 경로를 실제 경로와 일치시킵니다.
각 방법의 총 실행 시간을 입력 프레임 수로 나누어 평균 실행 시간을 보고합니다.
또한, 우리는 표준 depth 지표를 채택하여 추정된 비디오 depth의 품질을 최근 베이스라인과 비교합니다: Absolute Relative Error, log RMSE, 및 Delta accuracy.
우리는 100미터 이상의 지점을 제외하고 표준 평가 프로토콜을 따릅니다.
모든 방법에 대해, 우리는 예측된 비디오 depth를 실제 데이터와 일치시키기 위해 전역 규모와 이동 추정치를 사용합니다.


4.2. Quantitative Comparisons
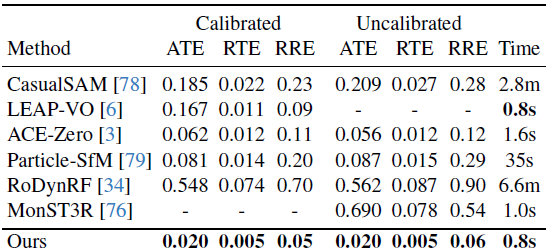
세 가지 벤치마크에서 카메라 포즈 추정에 대한 수치 결과는 표 1, 2, 3에 보고되어 있습니다.
우리의 접근 방식은 상당한 개선을 보여주며, 보정된 설정과 보정되지 않은 설정 모두에서 모든 오류 지표에서 최고의 카메라 추적 정확도를 달성하면서도 실행 시간 측면에서 경쟁력이 있습니다.
특히, 우리의 접근 방식은 동적 장면을 위해 최신 전역 3D 포인트 클라우드 표현을 채택했음에도 불구하고 견고성과 정확성 면에서 동시 작업인 MonST3R [76]을 능가합니다.
또한, 표 4의 Sintel 및 Dycheck에 대한 depth 예측 결과를 보고합니다.
우리의 depth 추정치는 모든 지표에서 다른 베이스라인을 크게 능가합니다.

4.3. Ablation study
우리는 카메라 추적 및 depth 추정 모듈의 주요 설계 선택 사항을 검증하기 위해 ablation 연구를 수행합니다.
구체적으로, 우리는 다양한 구성으로 카메라 추적 결과를 평가합니다: 1) vanilla Droid-SLAM [59], 2) 모노 depth 초기화 없이 (mono-init 없이), 3) 객체 이동 맵 예측 없이 (ˆm_i 없이), 4) 제안된 2단계 학습 방식을 사용하지 않고 동적 비디오에서 모델을 직접 학습시킵니다 (2단계 학습 없이), 5) 전역 BA (u-BA 없이 항상 모노 depth 정규화를 켭니다.
우리는 또한 비디오 depth 추정을 위한 두 가지 주요 설계 결정을 요약합니다: 1) 카메라 포즈와 depth 추정 (ft-pose 제외)을 공동으로 개선하고, 2) 제안된 단일 dpeth prior loss (새로운 C_prior 제외) 대신 CasualSAM의 원래 단일 depth prior loss를 사용합니다.
표 5에 나타난 바와 같이, 우리의 전체 시스템은 다른 모든 대체 구성을 능가합니다.


4.4. Qualitative Comparisons
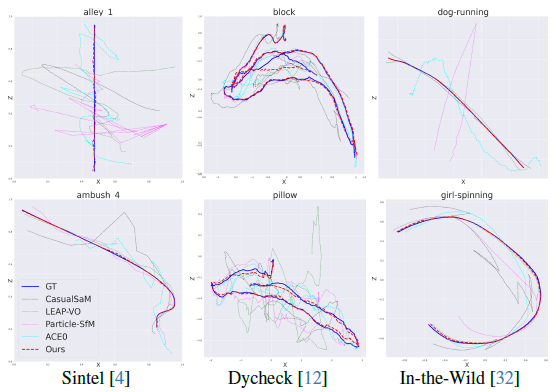
그림 5는 세 가지 벤치마크에서 2D 방법과 다른 베이스라인으로부터 추정된 카메라 궤적을 정성적으로 비교한 결과를 보여주며, 우리의 카메라 추정치는 실제 데이터에 가장 가깝습니다.
또한, 우리는 그림 6에서 우리의 접근 방식과 두 가지 최신 최적화 기반 기법인 CasualSAM [78] 및 MonST3R [76]을 통해 추정된 비디오 depth를 시각화하고 비교합니다.
특히, 우리는 전체 비디오에서 참조 프레임의 depth 맵과 해당 x-t depth 슬라이스를 시각화합니다.
우리의 접근 방식은 다시 한 번 더 정확하고 세밀하며 시간적으로 일관된 비디오 depth를 생성합니다.

마지막으로, 추정된 카메라와 투영되지 않은 depth 맵을 시각화하여 DAVIS [42]의 도전적인 예제에 대한 다양한 접근 방식 간의 재구성 및 카메라 추적 품질을 비교합니다.
그림 7에서 볼 수 있듯이, CasualSaM은 왜곡된 3D 포인트 클라우드를 생성하는 경향이 있는 반면, MonST3R은 회전 카메라의 움직임을 병진으로 잘못 처리합니다.
반면에, 우리의 접근 방식은 이러한 어려운 입력에 대해 더 정확한 카메라와 일관된 지오메트리를 제공합니다.
5. Discussion and conclusion
Limitations.
다양한 현장 동영상에서 뛰어난 성능을 보였지만, 이전 연구[78]의 결과와 유사하게 매우 어려운 시나리오에서는 우리의 접근 방식이 실패할 수 있음을 관찰했습니다.
예를 들어, 움직이는 물체가 전체 이미지를 지배하거나 시스템이 신뢰할 수 있는 추적 대상이 없는 경우 카메라 추적이 실패합니다.
실패 사례의 시각화를 위해 보충 자료를 참조하세요.
게다가, 우리 시스템은 비디오 내에서 초점 거리가 다양하거나 강한 방사형 왜곡이 있는 비디오를 처리할 수 없습니다.
현재 비전 기반 모델의 더 나은 priors를 파이프라인에 통합하는 것은 향후 유망한 방향입니다.
conclusion.
우리는 동적 장면의 캐주얼 모노 비디오에서 정확한 카메라 매개변수와 일관된 depth를 생성하는 파이프라인을 제시했습니다.
우리의 접근 방식은 제약 없는 카메라 경로와 복잡한 장면 역학을 통해 다양한 시간대의 현장 영상으로 효율적으로 확장할 수 있습니다.
신중한 확장을 통해 이전의 심층 비주얼 SLAM 및 SfM 프레임워크를 확장하여 다양한 비디오에 대한 강력한 일반화를 달성하고 최신 SOTA 방법을 크게 능가할 수 있음을 보여주었습니다.
'3D Vision' 카테고리의 다른 글
| Neural Inverse Rendering from Propagating Light (CVPR 2025 Best Student Paper) (2) | 2025.06.18 |
|---|---|
| VGGT: Visual Geometry Grounded Transformer (CVPR 2025 Best Paper) (0) | 2025.06.17 |
| Compact 3D Gaussian Representation for Radiance Field (1) | 2025.01.13 |
| LRM: Large Reconstruction Model for Single Image to 3D (0) | 2024.05.29 |
| Segment Anything in 3D with NeRFs (0) | 2024.05.16 |