2025. 6. 18. 11:21ㆍ3D Vision
Neural Inverse Rendering from Propagating Light
Anagh Malik, Benjamin Attal, Andrew Xie, Matthew O’Toole, David B. Lindell
Abstract
우리는 전파하는 빛의 다중 시점 비디오에서 물리적 기반의 뉴럴 인버스 렌더링을 위한 최초의 시스템을 소개합니다.
우리의 접근 방식은 뉴럴 래디언스 캐싱의 시간 분해 확장에 의존합니다 — 어느 방향에서든 도달하는 무한-바운스 래디언스를 저장하여 인버스 렌더링을 가속화하는 기술입니다.
결과 모델은 직접 및 간접 빛 전송 효과를 정확하게 설명하며, 플래시 라이다 시스템에서 캡처한 측정값에 적용하면 강한 간접 빛이 존재하는 상황에서 SOTA 3D 재구성이 가능합니다.
또한, 우리는 전파되는 빛의 뷰 합성, 캡처된 측정값을 직접 및 간접 구성 요소로 자동 분해하는 방법, 그리고 캡처된 장면의 멀티 뷰 시간 해상도 relighting과 같은 새로운 기능을 시연합니다.
1. Introduction
라이다와 같은 초고속 이미징 시스템은 빛의 펄스로 장면을 비추고 전파하는 파면에서 후방으로 흩어진 "echoes"를 포착합니다 [75].
후방 산란광의 광속 지연을 정밀하게 측정하면 3D 재구성이 가능하므로 이 원리에 기반한 라이다 시스템은 자율 주행 [36]부터 증강 현실 [2] 및 원격 감지 [13]에 이르기까지 다양한 응용 분야에서 인기가 높습니다.
라이다는 표면에서 센서로 직접 반사되는 빛, 즉 직접적인 빛의 시간 분해 측정에 의존합니다.
간접 빛 전송 (즉, 센서에 도달하기 전에 여러 번 산란하는 빛)의 측정은 일반적으로 무시되거나 폐기됩니다, 왜냐하면 간접 빛을 모델링하려면 재귀 경로 추적과 같은 절차를 사용하여 계산 비용이 많이 들고 종종 다루기 어려운 인버스 렌더링이 필요하기 때문입니다 [25, 65].
그럼에도 불구하고 간접 빛 측정은 재료의 특성, 외관, 지오메트리에 대한 풍부한 정보를 제공합니다 [32, 56, 62, 88, 99].
우리의 연구는 라이다 시스템에서 전파되는 빛의 다중 시점, 시간 분해 측정값을 모델링하고 반전시켜 장면 지오메트리를 복원하고, 새로운 시점과 새로운 조명 조건에서 전파되는 빛의 비디오를 렌더링하는 것을 목표로 합니다 (그림 1 참조).

기존의 라이다 시스템은 시간 분해 측정값을 캡처하여 3D 포인트 클라우드로 변환했으며, 이는 직접적인 빛 전송을 기반으로 한 장면 지오메트리의 추정치를 나타냅니다.
최근 연구에서는 여러 시점에서 포착된 라이다 측정을 활용하여 3D 재구성과 새로운 뷰 합성을 수행하는 반면, 기존 방법들은 포인트 클라우드 표현 [12, 21, 71, 96] 또는 직접적인 시간 분해 측정 [45, 47, 54, 67]을 사용하여 간접 빛을 무시합니다.
액티브 이미징을 사용한 다중 시점 재구성을 위한 다른 방법으로는 비행 시간 센서 [3, 59] 또는 구조화된 빛 [23, 77]을 사용하지만, 마찬가지로 간접 빛을 명시적으로 모델링하는 데 실패합니다.
우리의 연구는 Malik et al. [48]의 연구와 유사합니다, 그것은 라이다 측정과 neural radiance fields (NeRFs)를 기반으로 한 표현을 사용하여 새로운 관점에서 전파되는 빛의 비디오를 렌더링합니다 [51].
그러나 이러한 표현은 뷰 합성에 효과적이지만 물리적 기반 모델을 사용하지 않기 때문에 정확한 지오메트리를 재구성하거나 새로운 조명 조건에서 장면을 렌더링할 수 없습니다.
간접 빛 전송을 정확하게 모델링하려면 렌더링 방정식을 풀어야 합니다 [29].
많은 렌더러들이 Monte Carlo 샘플링을 기반으로 한 경로 추적 알고리즘을 사용하며, 이러한 방법의 미분 가능한 버전은 기존 (즉, 정상 상태) 이미지 [35, 44, 58]와 라이다 시스템과 같은 시간 분해 측정값 [91, 94]의 인버스 렌더링 가능성을 보여주었습니다.
그러나 이러한 방법들은 비시선 이미징과 같은 제한된 문제 설정에서 작동하지만 [24, 82], 계산 비용과 노이즈 및 로컬 미니마에 대한 민감성 때문에 캡처된 다중 시점 실험에 적용하기는 어렵습니다.
이 문제를 해결하기 위해 최근 방법들은 기하학 및 물리 기반 외관 모델의 부피 표현을 사용하여 렌더링 방정식을 하이브리드 방식으로 근사화합니다 [79, 98].
이러한 유형의 접근 방식은 기존의 강도 이미지에서 외관, 지오메트리 및 재료 매개변수를 인버스 렌더링하는 데 특히 효과적인 것으로 입증되었습니다 [4, 28, 42, 99].
여전히, 이전의 어떤 기술도 동일한 방식으로 시간 분해 직접 및 간접 빛 전송을 인버스 렌더링으로 수행하지 않습니다.
여기서 우리는 플래시 라이다 시스템에서 전파되는 빛의 다중 시점, 시간 분해 측정값을 인버스 렌더링하는 방법을 제안합니다 — 빛의 펄스로 장면 전체를 flood-illuminates로 변환하는 라이다의 일종.
우리의 접근 방식은 하이브리드 신경망 표현을 기반으로 하며, 볼륨 렌더링을 사용하여 지오메트리를 모델링하고, 래디언스 캐시를 사용하여 전역 조명 효과를 시뮬레이션하는 물리 기반 모델을 사용하여 외관을 모델링합니다 [87].
특히, 경로 추적을 사용하여 빛 경로를 통합하는 대신, 우리의 래디언스 캐시는 볼륨의 어느 지점에서든 도착하는 시간 분해 래디언스의 표현을 저장합니다.
표현은 상각된 방식으로 최적화되므로 렌더링 적분을 재귀적으로 평가할 필요가 없습니다, 대신 라이다에서 직접 조명을 렌더링하고 래디언스 캐시를 쿼리하여 표면 지점에서 간접 조명을 평가하기만 하면 됩니다.
우리 모델은 전파되는 빛의 직접 [47] 및 간접 구성 요소 [48]의 다중 시점, 시간 분해 렌더링을 위한 이전의 신경망 렌더링 프레임워크를 기반으로 하며, 이를 물리 기반 렌더링 프레임워크에 기반합니다.
전반적으로 다음과 같은 기여를 합니다.
• 우리는 시간 분해 래디언스 캐시를 사용하는 물리 기반 모델을 사용하여 전파되는 빛을 신경 인버스 렌더링하는 방법을 제안합니다.
• 보정된 광원과 카메라 위치를 사용하여 다중 시점, 시간 분해 플래시 라이다 측정의 새로운 데이터 세트를 캡처합니다.
• 우리는 시뮬레이션과 캡처된 데이터를 통해 우리의 방법을 시연합니다, 강력한 간접 빛 전송 하에서 기하학적 재구성의 SOTA 결과를 보여주고, 다양한 반사 특성과 중요한 간접 빛 전송 효과를 가진 장면에서 새로운 관점과 새로운 조명 조건 하에서 전파되는 빛의 비디오를 렌더링합니다.
2. Related Work
우리의 접근 방식은 시간 분해 이미징과 렌더링, 그리고 인버스 렌더링 분야를 결합합니다.
Time-resolved imaging.
라이다와 같은 비행 시간 시스템은 후방 산란 펄스의 도착 시간을 표시하여 비행 시간을 측정합니다 [33].
이러한 시스템은 일반적으로 나노초 또는 피코초 펄스 레이저를 고속 포토다이오드 [22] 또는 single-photon avalanche diodes (SPAD) [31, 70, 78]와 결합하여 입사광의 초고속 변화를 측정합니다.
결과적으로 시간 분해된 측정값은 직접 및 간접 빛 전송을 포착하며, 초고속 시간 척도에서 빛이 전파되는 비디오를 녹화하는 데 사용할 수 있습니다 [16, 38, 60, 84].
연속파 비행 시간 시스템 [18, 34]은 빛의 전파를 포착하는 데에도 사용할 수 있지만, 시간 해상도는 더 제한적입니다 (예: 피코초가 아닌 나노초) [20, 60].
우리의 접근 방식은 피코초 펄스 레이저와 SPAD가 장착된 라이다 시스템을 사용하여 전파되는 빛의 멀티 뷰 비디오를 캡처합니다.
이전 작업 [10, 15, 47, 48, 62, 69, 92]과 마찬가지로 레이저에서 나오는 빛의 펄스로 장면을 반복적으로 조명합니다.
SPAD는 개별 광자의 도착 시간을 피코초 수준의 정확도로 감지하고 입사광의 시간 분해 파형을 근사하는 광자 수 히스토그램을 출력합니다 [61].
우리의 접근 방식은 플래시 라이다 광원과 센서의 위치가 모두 달라지는 광자 수 히스토그램의 멀티 뷰 데이터셋을 최초로 포착한 것입니다.
또한, 우리는 전파하는 빛의 다중 시점 비디오를 사용하여 물리적 기반의 시간 분해 인버스 렌더링을 위한 첫 번째 기술을 개발합니다.
Time-resolved rendering.
시간 분해 경로 추적 렌더러는 전파되는 빛의 파면을 시뮬레이션하며 [27], birefringence [58], refraction [64], volumetric scattering [26, 63]과 같은 효과를 고려합니다.
최근에 이러한 시간 분해 렌더러의 미분 가능한 버전이 개발되었습니다 [91, 94], 그러나 이러한 방법을 사용한 강력한 합성 분석 장면 재구성은 계산 복잡성과 초기화 및 노이즈에 대한 민감성 때문에 아직 해결되지 않은 문제입니다.
다른 렌더러들은 비시선 이미징과 같은 특정 이미징 문제에 대해 시간 분해 빛 전송 행렬 [60, 68]을 근사합니다.
이 분야에서는 occluded 지오메트리를 복원하기 위해 두 번의 바운스 [32, 81], 세 번의 바운스 [39, 41, 69, 76, 92] 또는 고차 산란 사건 [37, 73]을 모델링하는 기술이 개발되었습니다.
비시선 설정에서는 렌더러가 일반적으로 빛이 평면 표면에서 반사되어 알려진 (보통 확산되는) 반사 특성을 가진다고 가정하거나, 임의의 빛 전달이 아닌 특정 산란 경로를 모델링합니다 [15].
여러 연구들이 연속파 시간-오프-라이트 센서의 맥락에서 간접 빛 전송을 고려하고 있지만, depth를 추정할 때 보통 제거해야 할 잔여물로 취급합니다 [1, 18, 57].
우리는 장면 지오메트리나 재료 특성에 대한 제한적인 가정 없이 다중 산란광의 물리적 기반 모델링을 수행하고, 캡처된 측정값으로부터 장면 재구성을 위한 인버스 렌더링 프레임워크에 우리의 접근 방식을 통합합니다.
Physically-based inverse rendering.
인버스 렌더링은 이미지 세트에서 재료, 조명, 지오메트리와 같은 장면 속성을 복원하는 것을 목표로 합니다 [11, 66, 95].
기존 기술은 물리적 기반의 빛 전송 모델 [29, 65, 83]과 그래디언트 기반 최적화를 통한 미분 가능한 렌더링을 사용하여 장면의 외관을 구성 속성 [10, 25, 35]으로 분해합니다.
최근 NeRF를 사용한 물리 기반 렌더링 기술 [51]은 인버스 렌더링을 훨씬 더 견고하게 만들었지만, 직접 조명 [7, 8, 79, 86, 98] 만을 고려하거나 간접 조명 [46]을 모델링하기 위해 여러 빛의 반사를 명시적으로 시뮬레이션해야 하므로 계산 비용이 많이 듭니다.
또 다른 접근 방식은 레디언스 캐시를 사용하는 것입니다 — 모든 지점에서 들어오는 래디언스의 반구를 저장하는 데이터 구조 [87].
그런 다음 이 반구를 로컬 bidirectional reflectance distribution function (BRDF) [65]와 통합하여 관측된 이미지 픽셀과 일치하도록 최적화된 방사광을 생성합니다.
레디언스 캐시와 NeRF를 결합하면 간접광을 더 효율적으로 모델링할 수 있습니다 [4, 42, 89, 93, 99].
마지막으로, Wu et al. [90]의 동시 연구는 공동으로 배치된 포인트 광원과 컬러 카메라를 사용한 레디언스 캐싱 기반 인버스 렌더링을 사용한다는 점에 주목합니다.
그러나 이전의 어떤 기술도 다중 시점 시간 분해 측정에서 물리적 기반 인버스 렌더링을 수행하지 않습니다.
이를 위해, 우리는 전파되는 빛의 비디오에서 신경 인버스 렌더링을 가능하게 하는 새로운 시간 분해 래디언스 캐시를 개발합니다.
3. Background: Radiance Caching with NeRFs
렌더링 방정식 [29]은 원점 o와 ray 매개변수 t를 가진 ray x(t) = o - t ω_o를 따라 점 x에서 ω_o 방향으로 빛의 래디언스를 모델링합니다:

이 방정식은 BRDF f로 가중된 방향 ω_i에서 x에 도달하는 입사 래디언스 L_i를 적분합니다.
적분은 법선 n에 대해 양의 반구 위에 있습니다: Ω = {ω_i : n · ω_i > 0}.
렌더링 방정식을 나이브하게 평가하면 입사 래디언스를 계산하기 위해 방정식을 재귀적으로 평가해야 하므로 계산이 기하급수적으로 증가합니다.
이 계산 페널티를 피하기 위해 렌더링 방정식에서 입사 래디언스 L_i를 캐시 L_i^cache로 조회하여 문제가 되는 재귀를 제거하는 래디언스 캐싱을 활용합니다:
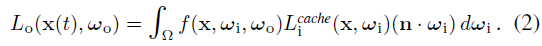
적분은 예를 들어, 다중 중요도 샘플링을 사용하여 캐시와 BRDF를 샘플링함으로써 효율적으로 근사할 수 있습니다 [65].
최근 연구에 따르면 NeRF는 래디언스 캐시의 정확한 모델링을 제공합니다 [4, 28, 40].
구체적으로, 우리는 이차 ray x′(t) = o′ - t ω′_o를 따라 NeRF를 볼륨 렌더링하여 L_i^cache (x, ω_i)를 계산할 수 있습니다, 여기서 o′ = x 및 ω′_o = ω_i [14, 43, 51]:

여기서 L_o^cache는 NeRF에 의해 예측된 2차 ray를 따라 각 지점에서 방출되는 래디언스입니다.
w_k 값은 각 샘플 지점 x′(t_k)에서의 밀도 σ과 ray 간격 (Δt)_k [50, 80]에서 계산된 ray의 투과율과 흡수를 설명하는 직교 가중치입니다:

우리의 연구는 라이다 측정을 기반으로 한 시간 분해 렌더링에 이 관찰을 적용합니다.
4. Method
우리는 장면 지오메트리와 재료 특성을 회복하기 위해 직접 및 간접 효과를 포함한 시간 분해 빛 전송을 모델링하고 반전시킵니다.
우리의 방법은 그림 2와 같이 신경망에 의해 매개변수화된 시간 분해 래디언스 캐시를 가진 물리 기반 시간 분해 렌더러를 사용합니다.
플래시 라이다 시스템에서 전파되는 빛의 측정값을 사용하여 표현을 최적화하여 인버스 렌더링을 수행합니다.

4.1. Physically-Based Time-Resolved Rendering
우리는 1차 ray x(t) = o - t ω_o를 장면에 투사하여 라이다 측정을 모델링합니다.
그 ray를 따라 각 지점마다 센서 방향으로 나가는 래디언스 L_o를 렌더링합니다.
우리의 시간 분해 렌더링 방정식은 식 1의 수정된 버전으로, 비행 τ 시간을
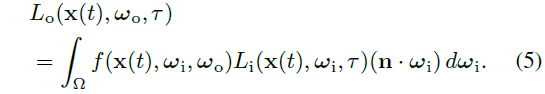
로 추가합니다.
반사율 f는 부록에 설명된 장면의 재료 특성에 따라 달라지는 Disney-GGX BRDF [9]를 사용하여 모델링됩니다.
우리는 입사 래디언스를 L_i = L_i^dir + L_i^cache의 두 가지 구성 요소로 더 분해합니다: 직접 성분 L_i^dir와 래디언스 캐시를 사용하여 평가된 간접 성분 L_i^cache.
직접 성분은
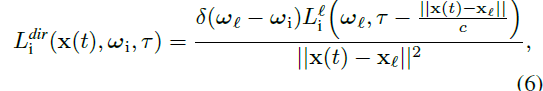
으로 주어지며, 여기서 x_ℓ은 광원의 위치, ω_ℓ은 광원의 방향, L_i^ℓ는 광원의 강도, δ(ω_ℓ - ω_i)는 디랙 델타 함수입니다.
우리는 빛의 속도 c를 기반으로 역제곱 법칙 강도의 감소와 위치 x(t)로의 시간 지연을 모델링합니다.
정상 상태 경우 (식 3)와 유사하게, 시간 분해 래디언스 캐시 L_i^cache (x, ω_i, τ)는 1차 ray o′ = x의 점에서 ω'_o = ω_i로 주조된 2차 ray x′(t) = o′ - t ω'_o를 사용하여 평가됩니다.
우리는 시간 분해 볼륨 렌더링 [3, 17, 47]을 사용하여 레디언스 캐시를

로 렌더링합니다, 여기서 L_o^cache는 신경 표현에 의해 예측되는 나가는 레디언스입니다.
위의 내용은 시간 τ에서 ω_i 방향으로 o′에 입사하는 빛이 ω'_o를 따라 각 점 x′를 떠나는 지연된 빛의 복사본의 합이며, 지연은 ray 매개변수 t_k에 의해 주어진 o′까지의 거리에 따라 달라진다는 것입니다.
주 ray의 각 포인트에 대한 시간 분해 렌더링 방정식 (식 5)을 평가한 후, 라이다 측정은 캐시와 동일한 방식으로 볼륨 렌더링을 통해 계산됩니다:
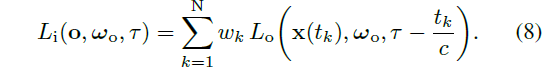
4.2. Time-Resolved Radiance Cache
Representation.
캐시는 위치 의존적인 외관 피쳐 f^app을 학습하기 위해 H^app [5, 55]를 인코딩하는 멀티 해상도 해시를 사용하여 매개변수화됩니다.
마찬가지로 해시 인코딩 기반 신경망 N^geom은 밀도와 법선을 통해 장면 기하학을 나타냅니다.
그것은,
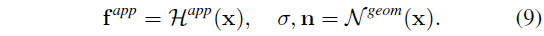
볼륨 렌더링에 사용되는 밀도 값은 물리 기반 모델과 레디언스 캐시 (즉, 식 7 및 8) 모두에서 공유됩니다.
외관 피쳐는 래디언스 캐시를 계산하는 데 사용되며, 이를
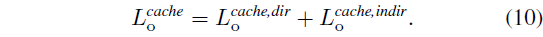
과 같이 직접 및 간접 구성 요소로 분해합니다.
이 각 구성 요소를 다음과 같이 설명합니다.
Direct light.
직접 구성 요소는 라이다 소스에서 x_ℓ으로 방출되어 장면의 한 지점 x′로 전파되고 ray 원점 o′로 직접 산란되기 때문입니다:

여기서 f^dir는 BRDF를 학습하는 신경망입니다 (자세한 설명은 부록을 참조하십시오).
실제로 우리는 식을 이산화하고 각 시간 간격에서 래디언스를 나타내는 벡터를 계산합니다.
Indirect light.
우리는 나가는 간접 빛을 효율적으로 캐싱하기 위해 스플릿섬 근사법 [30]을 활용합니다:

, 여기서 F_Ω^indir와 L_(i,Ω)^indir는 각각 통합 BRDF와 통합 입사 래디언스를 예측하는 신경망입니다.
간접 빛은 광원의 위치에 따라 달라지기 때문에 x_ℓ 조건을 포함합니다.
Malik et al. [48]에 따르면, L_(i, ω)^indir는 이산화된 시간 간격 동안의 래디언스를 나타내는 벡터를 예측합니다.
4.3. Inverse Rendering from Propagating Light
라이다 시스템은 센서 L_i^meas에서 시간 분해된 입사 래디언스를 포착합니다.
라이다 측정값과 물리 기반 렌더러의 출력 L_i 간의 차이를 최소화하여 표현을 최적화합니다 (간단함을 위해 o, ω_o, τ에 대한 의존성은 생략합니다):
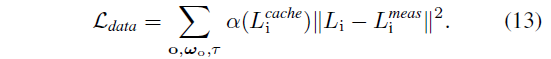
캐시는 센서에서 시간 분해된 입사 래디언스를 렌더링하는 데에도 사용할 수 있으므로, 위에서 언급한 L_i를 L_i^cache로 대체하는 L_cache를 최소화하여 동일한 방식으로 이를 supervise합니다.
함수 α는 어두운 영역에서 오류를 더 강하게 처벌하기 위해 선택되었으며, 이는 톤 매핑 곡선을 적용하는 것과 유사하게 지각 품질을 향상시킵니다 [52]:
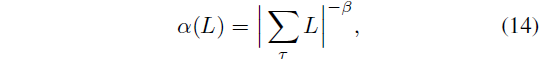
, 여기서 β는 하이퍼파라미터입니다.
식 13에서는 Monte Carlo 렌더 노이즈의 영향을 받지 않기 때문에 캐시에서 들어오는 래디언스 (L_i 대신 L_i^cache)를 사용하여 이 가중치를 계산합니다.
Hadadan et al. [19]에 따르면, 우리는 캐시를 사용하여 렌더링된 직접 및 간접 빛이 전체 물리 기반 모델과 일치하도록 제한하는 radiometric prior를 활용합니다.
구체적으로, 우리는 기본 ray를 따라 샘플 포인트 x에서 래디언스의 직접과 간접 성분을 렌더링합니다, 이는 캐시(L_o^(cache, dir/indir))와 물리 기반 모델(즉, L_o^(dir/indir))을 사용하여, 각각 L_i^dir 또는 L_i^cache만을 사용하여 식 5를 평가하여 제공됩니다.
loss를 사용하여 캐시를 제한합니다:

마지막으로, 완전한 photometric loss 함수는

이며, 여기서 λ_cache, λ_dir, λ_indir는 각 loss 성분을 측정하는 하이퍼파라미터입니다.
이 loss 함수를 최소화함으로써, 이 방법은 장면의 재료 모델 (Disney-GGX 모델을 사용하여 매개변수화됨)과 장면 기하학, 법선 및 외관 매개변수를 복구합니다.
위의 photometric loss 외에도, 우리는 밀도 필드 [85]에서 예측된 노멀을 분석 노멀과 연결하는 정규화 L_normal, 분석 노멀에 대한 매끄러움 페널티 L_geom, 예측된 BRDF 매개변수에 대한 매끄러움 페널티 L_mat, Zip-NeRF [5]에서와 같은 제안 리샘플링 및 왜곡 loss L_interlevel 및 L_distortion, 그리고 마스크 loss L_mask를 포함합니다.
우리는 Attal et al. [4]에서와 같이 BRDF를 기반으로 한 이차 ray에 대한 다중 중요도 샘플링과 입사 조명에 대한 학습 가능한 중요도 샘플링기를 사용합니다.
학습 가능한 중요도 샘플러는 loss L_vMF로 supervise됩니다.
우리는 시간 분해된 직접 방출 빛을 원핫 벡터로 표현합니다, 여기서 각 빈은 이산 시간 간격에 해당하며, 간접 빛은 동일한 크기의 밀집 벡터로 표현됩니다 (여기서 크기는 데이터셋에 따라 달라집니다).
부록에 완전한 설명이 제공됩니다.
5. Results
우리는 세 가지 작업을 통해 시스템을 평가합니다: (1) 시간 분해 라이다 측정값의 뷰 합성, (2) 통합 (steady 상태) 라이다 이미지의 뷰 합성, (3) 기하학적 재구성.
Evaluation metrics.
렌더링된 통합 라이다 이미지를 평가하기 위해 PSNR, SSIM, LPIPS를 사용합니다 [97].
복구된 시간 분해 측정의 정확성을 평가하기 위해 Malik et al. [48]이 도입한 transient intersection-over-union (transient IOU)을 사용합니다.
mean absolute error (MAE)와 L1 오차를 사용하여 각각 복원된 normal과 depth의 정확도를 측정합니다.
표 1에서 시뮬레이션된 장면과 캡처된 장면 모두에 대한 정량적 결과를 보고합니다.
Baselines.
우리는 우리의 방법을 다음과 같은 SOTA 시간 분해 신경 렌더링 기술과 비교합니다: 시간 분해 라이다 측정을 위해 신경 표현과 렌더링 모델을 사용하는 T-NeRF [47]와 공간의 모든 지점에서 시간 분해 래디언스를 예측하는 Flying with Photons (FWP) [48].
원래 버전의 FWP는 광원이나 광원의 이동을 모델링하지 않기 때문에, 우리는 전체 시간 분해된 래디언스 캐시에 해당하는 수정된 버전 (FWP++)을 사용합니다.
우리는 동일한 해시 인코딩 기반 신경 표현 [55]을 사용하여 두 베이스라인을 모두 구현하고, 공정성을 위해 동일한 정규화기와 하이퍼파라미터를 사용합니다.
5.1. Simulated Results
Dataset.
우리는 Mitsuba 2 렌더러 [58]의 수정된 [72]를 사용하여 세 개의 소규모 객체 중심 합성 장면, Cornell box, pots, peppers, 그리고 하나의 방 규모 장면, kitchen에 대한 멀티 뷰 transient 데이터를 렌더링합니다 [6].
Comparison.
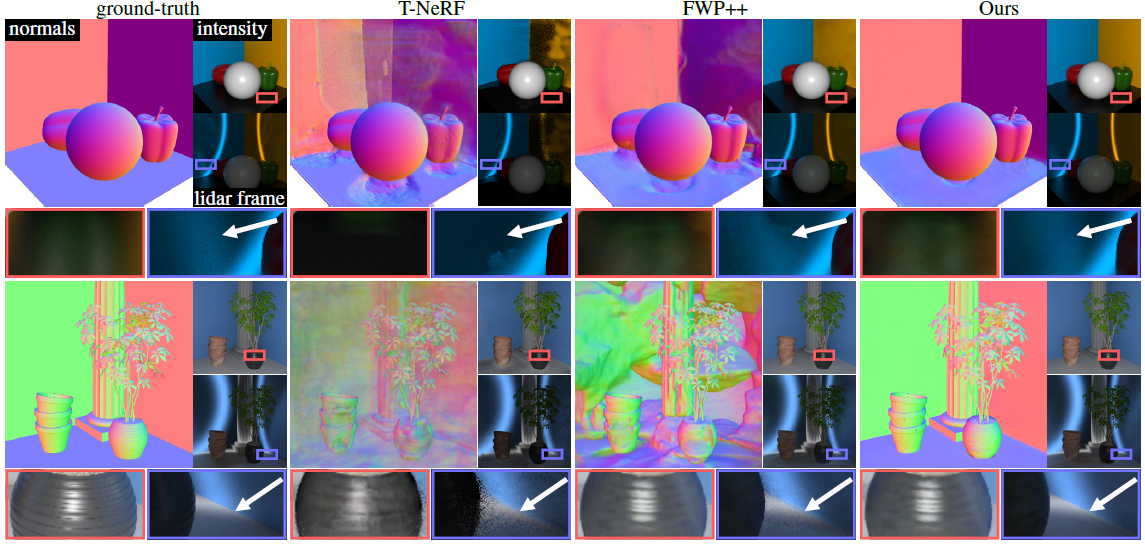
그림 4에서는 peppers와 pots 장면에 대한 새로운 관점, 복원된 노멀, 개별 라이다 프레임의 통합 라이다 스캔을 보여줍니다.
T-NeRF [47]은 직접적인 빛만을 모델링하기 때문에, 반사와 확산된 상호 반사로부터 강한 간접적인 빛을 받으면 정확한 지오메트리를 회복하는 데 실패합니다.
특히, 이러한 효과를 설명하기 위해 플로팅 아티팩트를 도입하여 새로운 뷰를 정확하게 예측하지 못합니다.
반면, FWP++ [48]은 직접 및 간접 래디언스를 모델링하고 정확한 통합 새로운 뷰와 라이다 프레임을 복원합니다.
그러나 물리적으로 정확한 렌더링 모델을 사용하지 않기 때문에 데이터에 과적합됩니다.
구체적으로, 장면의 거울 사본을 사용하여 반사 장면 (예: peppers 장면의 바닥이나 화분 장면의 부분적으로 파란 벽)을 설명하는 것은 자유롭습니다.
또한, 잘못된 depth를 사용하여 확산 상호 반사를 설명합니다(예: peppers 장면의 벽 모서리 또는 pots 장면의 기둥 플루팅을 따라).

5.2. Captured Results
Dataset.
우리는 Malik et l. [48]과 유사한 하드웨어 설정 (그림 3)을 사용하여 다중 시점 플래시 라이다 데이터셋을 캡처합니다.
Malik et al. [48]과 달리, 우리의 광원 위치는 장면에 대해 정지해 있는 것이 아니라 카메라의 시점에 따라 움직입니다.
우리는 세 장면을 포착합니다: globe, house, 그리고 spheres를 사용하며, 우리는 Malik et al. [48]의 동상 장면을 사용합니다, 이 장면은 우리의 방법이 고정된 광원을 처리할 수 있음을 보여줍니다.
부록에서 캡처 및 보정에 대한 자세한 내용을 제공합니다.

Comparison.
시각적으로 캡처된 결과는 시뮬레이션된 결과와 유사한 경향을 따릅니다.
그림 5는 globe 장면의 벽 모서리나 동상 장면의 촛불 바닥과 같이 간접 빛이 존재하는 영역에서 FWP++보다 더 정확한 지오메트리를 복원한다는 것을 보여줍니다.

표 1은 라이다 측정의 새로운 뷰 합성에 대한 정량적 결과를 제공합니다.
우리는 FWP++가 뷰 합성 접근 방식에 비해 약간의 개선을 보인다는 것을 발견했지만, 이는 훨씬 덜 제약된 모델을 사용하기 때문이라고 가정합니다—우리의 접근 방식은 물리적으로 기반을 두고 있으므로 물리적 시스템의 보정과 모델 불일치에 더 민감할 수 있습니다.
캡처된 실험에 대한 depth 및 일반 지표는 ground truth 참조가 없기 때문에 생략합니다.
5.3. Additional Results
Relighting.
우리의 접근 방식은 시간 분해 뷰 합성 및 재조명을 가능하게 하며, 이는 우리가 아는 한, 캡처된 멀티 뷰, 시간 분해 측정에서 이전에 입증된 적이 없습니다.
그림 1은 "C-V-P-R" 문자가 있는 패턴을 투영하는 시뮬레이션 펄스 소스를 사용하여 캡처된 house 장면에서 새로운 뷰로 재조명 결과를 보여줍니다.
그림 6에서는 시간 분해 재조명의 두 가지 추가 예를 보여줍니다: (1) 세 가지 다른 광원이 집에 모이는 동일한 house 장면과 (2) 펄스 트레인을 방출하는 세 가지 포인트 소스로 다시 조명하는 시뮬레이션 kitchen 장면.

광원 위치를 조건으로 한 신경망을 사용하여 레디언스 캐시의 간접 구성 요소를 예측한다는 점에 유의하세요 (식 12).
따라서 재조명에 사용되는 광원의 강도 프로파일이 학습 데이터 (예: 그림 1과 같이 균일한 포인트 광원 대신 프로젝터)와 다를 경우, 식 15의 래디언스 loss L_(dir/indir)과 원하는 광원 프로파일을 사용하여 파인튜닝을 수행합니다 (추가 세부 정보는 부록에 제공됩니다).
Time-resolved imaging without lidar.
비록 우리 시스템이 시간 분해된 빛 전송을 회복하더라도, 반드시 라이다 측정에 대한 supervision이 필요한 것은 아닙니다.
특히, 우리는 continuous-wave time-of-flight (CW-ToF) 측정이나 강도 이미지를 사용하여 모델을 학습할 수 있습니다, 두 가지는 모두 시간 분해 데이터에서 도출될 수 있기 때문입니다.
우리는 각 입력 유형에 따라 전파되는 빛의 시간 분해 비디오를 생성함으로써 이 기능을 입증합니다.
그림 7은 학습 후 렌더링된 시간 분해 측정값을 CW-ToF 측정값 (라이다 측정값을 CW-ToF 조명 파형과 합성하여 에뮬레이션) 또는 강도 이미지 (라이다 측정값을 시간에 따라 통합하여 에뮬레이션)로 보여줍니다.
또한 ToF 측정과 정상 상태 이미지에서 직접 및 간접 빛 전송 효과의 회복을 시연합니다.
예를 들어, house에서는 버섯 아래에서 확산된 상호 반사를 회복하고, spheres에서는 지면에서 정구로 반사를 회복합니다 (그림 7의 화살표).

이 애플리케이션에서는 모델의 supervision만 수정합니다.
구체적으로, loss를 계산하기 전에 시간 분해 예측을 CW-ToF 또는 정상 상태 측정값을 모방하도록 변환합니다.
최적화 후, 우리는 시간 분해된 비디오 프레임을 직접 렌더링합니다.
Material decomposition.
우리의 방법은 또한 Disney-GGX BRDF의 재료 매개변수 (알베도, 거칠기, 금속성)를 복구합니다.
부록에서 합성 장면과 캡처 장면에 대한 이러한 매개변수를 시각화합니다.
6. Discussion
Limitations.
결과 섹션에서 언급했듯이, 우리의 방법은 FWP++ 베이스라인을 포함한 다른 접근 방식보다 더 제한된 물리적 모델에 의존합니다.
따라서 모델 불일치가 잠재적인 문제인 캡처된 데이터의 베이스라인에 비해 성능이 일부 저하되는 것을 확인할 수 있습니다.
이 문제는 물리적 설정을 더 잘 조정함으로써 완화될 수 있을 것입니다.
또한, 우리의 방법은 시간 소모적인 물리적 빛 전송 시뮬레이션, 대규모 시간 분해 측정 벡터 로드로 인한 입출력 페널티, GPU 메모리 대역폭 요구 사항으로 인해 단일 GPU에서 하루 이상의 최적화가 필요합니다.
이 문제를 해결하기 위해 전체 시간 분해 벡터를 예측하는 대신 단일 순간에 신호를 예측하고 supervise하는 다른 신경 표현을 사용하는 것이 가능할 수 있습니다.
3D Gaussian Ray Tracing [53] 또는 EVER [46]과 같은 더 빠른 신경 표현을 사용하는 것도 흥미로운 방향입니다.
Impact and future applications.
비록 이 연구에서 비시선 이미징 문제를 다루지는 않지만, 원칙적으로 비평면 릴레이 표면을 사용한 비시선 이미징과 같은 제약 없는 조건에서도 이 응용을 위한 프레임워크를 확장하는 것이 가능합니다 [39].
라이다 기술의 광범위한 사용으로 인해, 우리는 우리의 연구가 자율 주행이나 원격 감지와 같은 분야에서 영향을 미칠 가능성이 있다고 믿습니다 — 특히 간접 조명 효과가 강한 시나리오에서는 더욱 그렇습니다.
'3D Vision' 카테고리의 다른 글
| MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos (0) | 2025.06.19 |
|---|---|
| VGGT: Visual Geometry Grounded Transformer (CVPR 2025 Best Paper) (0) | 2025.06.17 |
| Compact 3D Gaussian Representation for Radiance Field (1) | 2025.01.13 |
| LRM: Large Reconstruction Model for Single Image to 3D (0) | 2024.05.29 |
| Segment Anything in 3D with NeRFs (0) | 2024.05.16 |